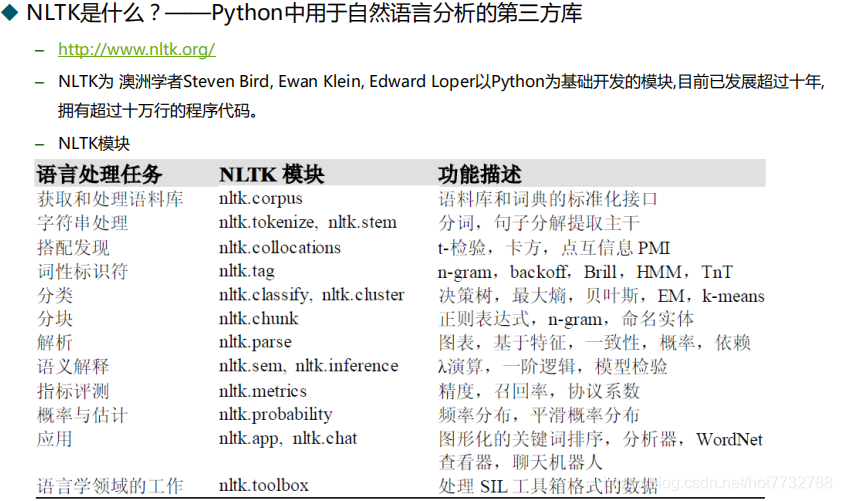
1.NLTK模块
2.常用操作
- 词密度-重复率
def lexical_diversity(text): #词密度-重复率
return len(text) / len(set(text))
- 搜索单词
text1.concordance("monstrous")
- 搜索相似度
text1.similar("monstrous")
- 搜索共同上下文
text2.common_contexts(["monstrous", "very"])
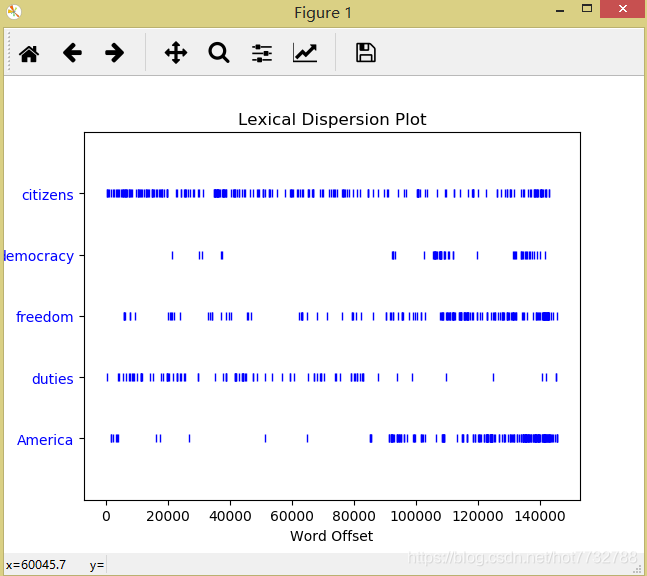
- 查看词汇分布图
text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])
3.统计方法
- 创建样本频率分布
fdist1 = FreqDist(text1) #以词汇本身作为索引值
- 输出索引值,即单词,并选择频率最高的50个
vocabulary1 = list(fdist1.keys())
print(vocabulary1[:50]) #50个最常出现的词
- 输出只出现过一次的索引值词汇
print(fdist1.hapaxes()) #获取只出现过一次的词汇
- 获取长词,高于15个长度,并进行排序
V = set(text4)
long_words = [w for w in V if len(w) > 15] #获取长词
sorted(long_words)
print(long_words)
- 获取长度大于7并且频率也大于7的词汇
fdist5 = FreqDist(text5)
sorted([w for w in set(text5) if len(w) > 7 and fdist5[w] > 7])#长度超过7并且出现的频率超过7
- 词语搭配,输出连词搭配
from nltk.util import bigrams #双连词
print(list(bigrams(['more', 'is', 'said', 'than', 'done'])))
print(text4.collocations()) #输出双连词搭配
4.其他统计方法
-以词频长度作为索引建立频率分布-输出索引值(即词语长度的分类) + 输出分布后经过频数统计的数值
fdist = FreqDist([len(w) for w in text1]) #词语长度的词频
print(fdist)
print(fdist.keys()) #查看索引值-即词语长度
print(fdist.items()) #输出统计后的数据
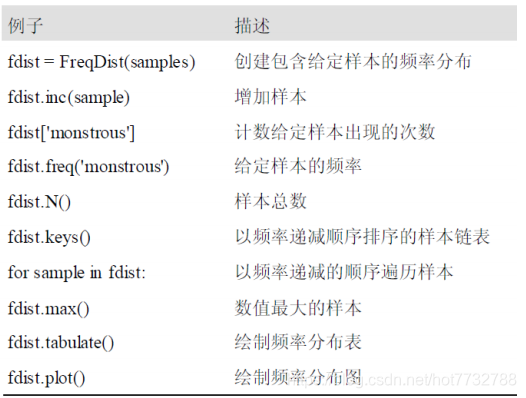
- 其他统计结果方法
 -
-