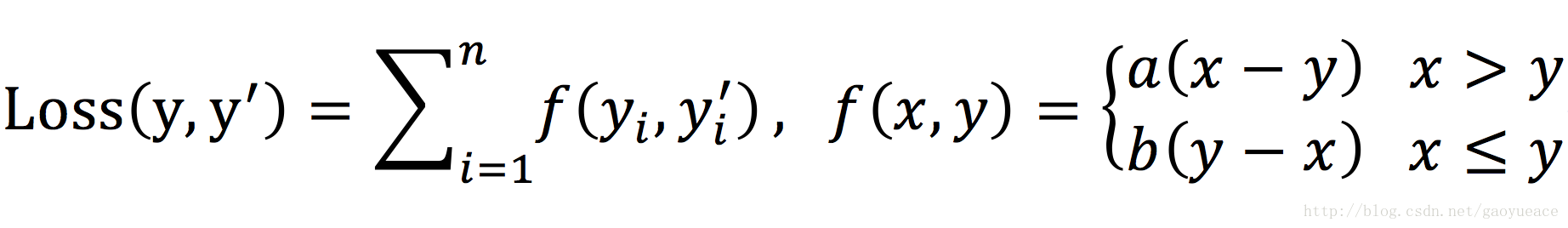原因:
为什么用自定义损失?
例子:假如卖西瓜,多预测一车,损失成本5k元,,但是如果少预测一车,则损失50k元,这样很有可能无法最大化利润,
目的
神经网络中损失函数定义的是损失,所有要结果利益最大化,定义的损失函数应该刻画成本或者代价。下面的公式为当预测多于真实值和预测少于真实值时有不同损失系数的损失函数:
yi为一个batch中第i个数据的正确答案,
yi’为神经网络得到的预测值,
a和b是常量。
在TensorFlow中,可以使用以下代码实现:
loss = tf.reduce_sunm(tf.select(tf.greater(v1, v2), (v1-v2)*a, (v2-v1)*b))
- tf.greater函数是比较两个输入张量中每一个元素的大小
- tf.select(条件,value1,value2)函数有三个参数,第一个为选择条件依据,当选择条件为True时,tf.select会选择第二个参数的值,否则选择第三个元素的值,(这里不是三目运算,以为他会分别选择取二者中符合的值做拼接)
#一个例子:
import tensorflow as tf v1 = tf.constant([1.0,2.0,3.0,4.0]) v2=tf.constant([4.0,3.0,2.0,1.0]) sess = tf.InteractiveSession() print(tf.greater(v1,v2).eval()) #输出 [False ,False,True,True] print(tf.select(tf.greater(v1,v2),v1,v2).eval()) #输出 [4. ,3. ,3. ,4.] sess.close()