主要探究h2o的排放量,这里是污水
#!/usr/bin/python
# -*- encoding: utf-8
import numpy as np
import matplotlib as mpl
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import BaggingRegressor
def read_data():
plt.figure(figsize=(10, 6), facecolor='w')
plt.subplot(121)
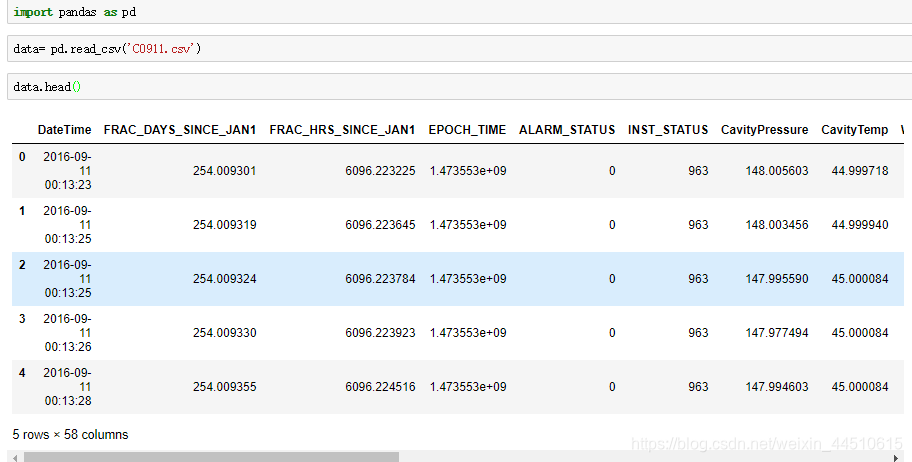
data = pd.read_csv('C0904.csv', header=0)
x = data['H2O'].values
plt.plot(x, 'r-', lw=1, label='C0904')
plt.title('实际排放数据0904', fontsize=16)
plt.legend(loc='upper right')
plt.grid(b=True, ls=':', color='#404040')
plt.subplot(122)
data = pd.read_csv('C0911.csv', header=0)
x = data['H2O'].values
plt.plot(x, 'r-', lw=1, label='C0911')
plt.title('实际排放数据0911', fontsize=16)
plt.legend(loc='upper right')
plt.grid(b=True, ls=':', color='#404040')
plt.tight_layout(2, rect=(0, 0, 1, 0.95))
plt.suptitle('如何找到下图中的异常值', fontsize=18)
plt.show()
if __name__ == "__main__":
mpl.rcParams['font.sans-serif'] = ['simHei']
mpl.rcParams['axes.unicode_minus'] = False
# read_data()
data = pd.read_csv('C0911.csv', header=0) # C0911.csv, C0904.csv
x = data['H2O'].values
print(x)
# 异常检测
width = 500
delta = 10
eps = 0.15
N = len(x)
p = []
abnormal = []
for i in np.arange(0, N-width, delta):
s = x[i:i+width]
p.append(np.ptp(s))
if np.ptp(s) > eps:
abnormal.append(list(range(i, i+width)))
abnormal = np.unique(abnormal)
plt.figure(facecolor='w')
plt.plot(p, lw=1)
plt.grid(b=True, ls=':', color='#404040')
plt.title('固定间隔$H_2O$含量的差值', fontsize=16)
plt.xlabel('时间', fontsize=15)
plt.xlabel('差值', fontsize=15)
plt.show()
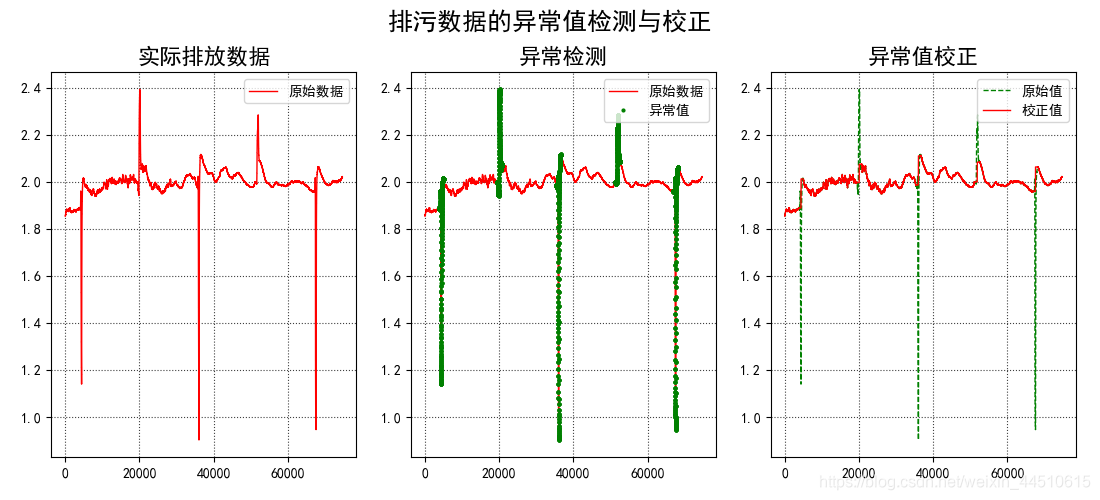
plt.figure(figsize=(11, 5), facecolor='w')
plt.subplot(131)
plt.plot(x, 'r-', lw=1, label='原始数据')
plt.title('实际排放数据', fontsize=16)
plt.legend(loc='upper right')
plt.grid(b=True, ls=':', color='#404040')
plt.subplot(132)
t = np.arange(N)
plt.plot(t, x, 'r-', lw=1, label='原始数据')
plt.plot(abnormal, x[abnormal], 'go', markeredgecolor='g', ms=2, label='异常值')
plt.legend(loc='upper right')
plt.title('异常检测', fontsize=16)
plt.grid(b=True, ls=':', color='#404040')
# 异常校正(预测)
plt.subplot(133)
select = np.ones(N, dtype=np.bool)
select[abnormal] = False
t = np.arange(N)
dtr = DecisionTreeRegressor(criterion='mse', max_depth=10)
br = BaggingRegressor(dtr, n_estimators=10, max_samples=0.3)
br.fit(t[select].reshape(-1, 1), x[select])
y = br.predict(np.arange(N).reshape(-1, 1))
y[select] = x[select]
plt.plot(x, 'g--', lw=1, label='原始值') # 原始值
plt.plot(y, 'r-', lw=1, label='校正值') # 校正值
plt.legend(loc='upper right')
plt.title('异常值校正', fontsize=16)
plt.grid(b=True, ls=':', color='#404040')
plt.tight_layout(1.5, rect=(0, 0, 1, 0.95))
plt.suptitle('排污数据的异常值检测与校正', fontsize=18)
plt.show()
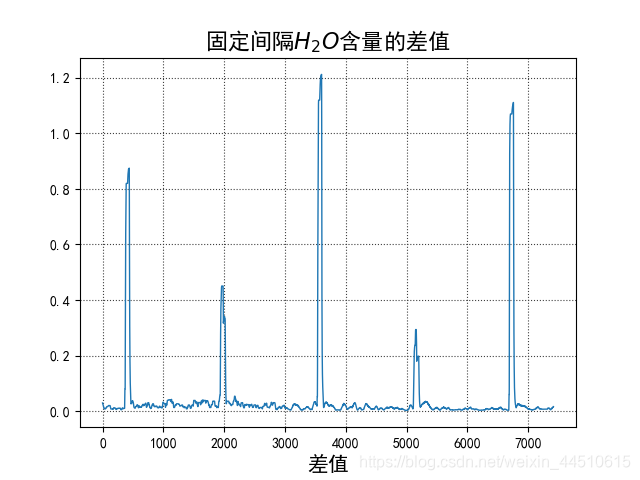
此图是上一个数据相对于下一个数据的差值,很快就找出异常值
下一步就是使用机器学习来预测异常值的预测值,采用决策树来集成的方法