背景
这个facebook登录的方法是我偶然间发现的,之所以把它公布呢,是因为facebook的爬虫项目公司在看完我做的facebook cookie压力测试后,和预期目标差的有点多,就停止了,以后启用也不会是这个方法了,所以我才会公布出来。
关于splash
代码是需要splash的,关于splash大家可以去看看别的博主所作的介绍,我在这里就不多描述了,你只要知道它其实是一个js渲染服务就行了,它可以通过 lua 来调用, lua是一门脚本语言,容易上手。**splash 是 在 docker 上运行的,关于docker,我也不过多介绍,如果你不是win10 pro 就不要装 docker desktop,装其他版本就好,不要像我一样为了装desktop版本,专门把系统给换了。至于为什么第一时间选用选择spalsh呢,因为facebook的Ajax请求太难构造了,而且还会过段时间更换参数,而用splash,你只需使用下滑操作就行了,一直滑一直爽。
**
所以看到这里你应该知道,这是建立在你使用了docker,运行了splash,略懂scrapy,并且splash可以翻墙登录facebook的前提下才有的。
关于方法
简单描述一下我的登录方法把,一般使用splash都是使用账号 密码进行登录操作,而我的这种方法是使用cookie,你可能就要我问了,使用requests里带上cookie也能用啊,为什么还要使用这种方法呢?原因就是 我这种登录方式 cookie 是永远不会过期的,除非facebook改变了cookie验真的参数和方法,还有你每次进行密码登录的时候facebook其实每次都会验证一下的,而这种方式就不会,它是默认这个账号原本就是在这里的。
下面我就来讲讲代码里面的东西把,git项目地址在后面。
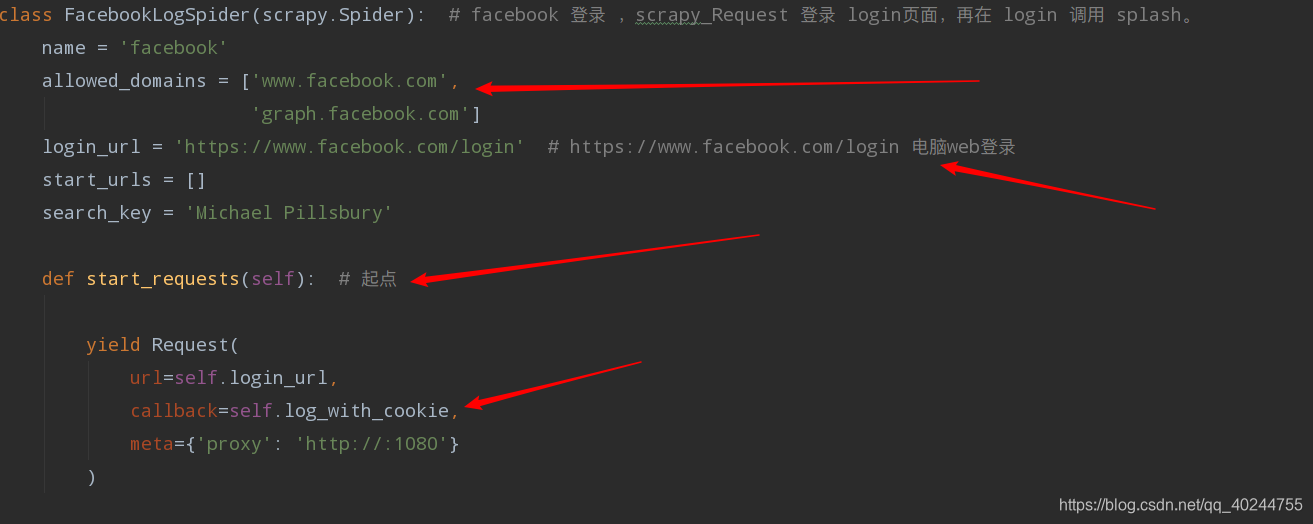
再正常不过的scrapy开始的方法,它里面有 登录的url、回调的登录方法,还有一个就是翻墙的本地端口。
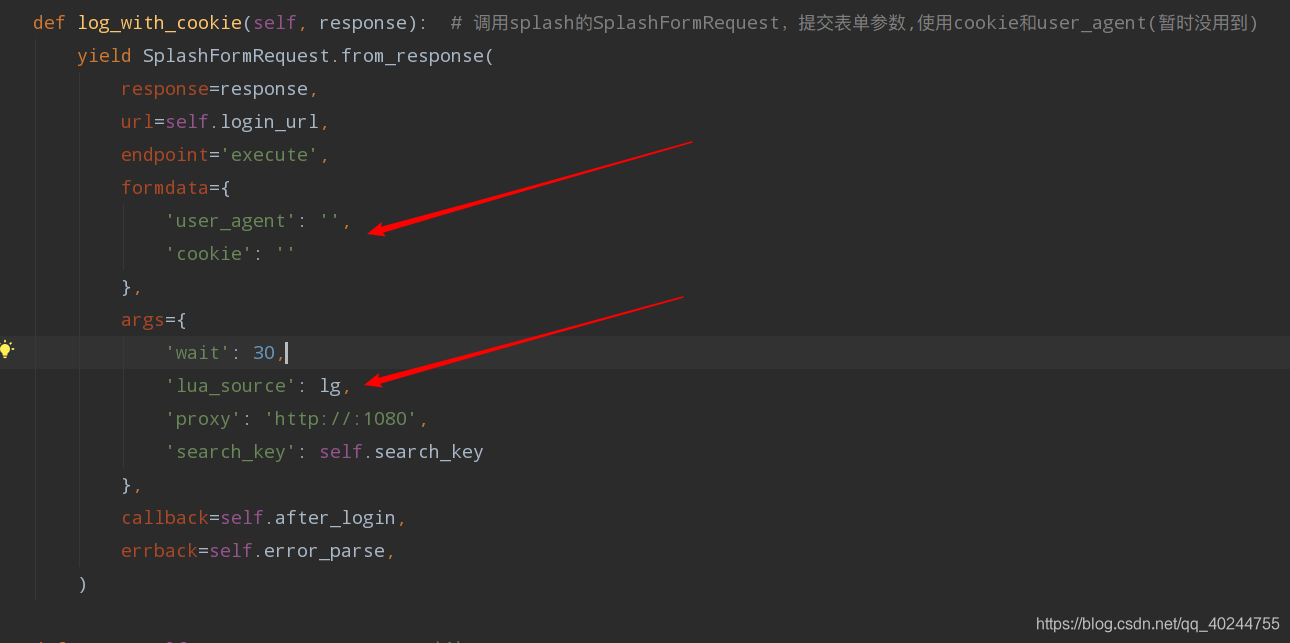
formdata 里 为什么没有参数呢,工作机制是在这样的,在登录到facebook页面后,会调用jsduicookie进行一番操作再进行一次重定向,就登陆了,所以这个formdata 用处不大。
下面说说调用的 lua 脚本

调用的lua 脚本
zero lua脚本
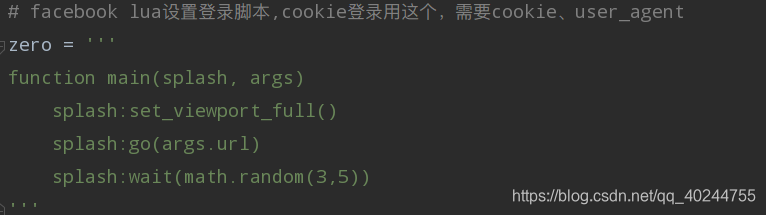
five脚本

coo 为用户的cookie,这段代码就是 js语法 对cookie进行操作,然后重定向之后就登陆了。
zero_end = '''
splash:wait(math.random(3,5))
search_key = args.search_key
search_text = splash:select('.inputtext')
search_btn = splash:select('button[type=submit]')
if (search_text and search_btn) then
search_text: send_text(search_key)
search_btn: mouse_click({})
end
splash:wait(math.random(4,5))
user_href = splash:select('li[data-edge=keywords_users]')
if user_href then
user_href: mouse_hover({x=0, y=0})
user_href: mouse_click({})
end
splash:wait(math.random(4,5))
user_html = splash:html()
public_href = splash:select('li[data-edge=keywords_pages]')
if public_href then
public_href: mouse_hover({x=0, y=0})
public_href: mouse_click({})
end
splash:wait(math.random(4,5))
public_html = splash:html()
return {
user_html,
public_html,
}
end
'''
这段是lua 搜索的脚本(就是你可以搜一个人,然后splash会点击搜索)
lua 脚本我就不多说了,和 js 稍微有点像,至于翻墙 你们可以去搜 shadowsocket + privoxy 组合, privoxy 下载地址:https://sourceforge.net/projects/ijbswa/
privoxy 配置:https://blog.csdn.net/zyf2333/article/details/84563986
因为调用splash和原本的期望相差太多,而rquests 带cookie做的压力测试也不甚理想,只能放弃了,所以我把方法分享出来,留给后来人去做吧。
联系我:[email protected]
觉得有用的话,github给颗小星星
github 地址:https://github.com/madpudding/FacebookCrawler
另外我还提供一种思路把,爬取公共主页这种东西的话,我建议您注册facebook开发者呢,使用图谱工具去检索,简直不要太爽,如果您的作业里牵涉到公共主页,种草使用facebook自己的图谱供工具,虽然它被阉割了很多次了,基本还能用。如果你是Facebook开发者,建议您 pip install facebook-sdk 呢,这个包维护良好,调用facebook 图谱(graph) 很方便呢。