Hadoop是Apache软件基金会所开发的并行计算框架与分布式文件系统。最核心的模块包括Hadoop Common、HDFS与MapReduce。
HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。采用Java语言开发,可以部署在多种普通的廉价机器上,以集群处理数量积达到大型主机处理性能。
一、HDFS基本概念
1、Block:HDFS默认的基本存储单位是64M的数据块,和普通文件系统相同的是,HDFS中的文件是被分成64M一块的数据块存储的。不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
2、元数据节点(NameNode)
a、主要用来管理文件系统的命名空间,其将所有的文件和文件夹的元数据保存在一个文件系统树中。这些信息也会在硬盘上保存成以下文件:命名空间镜像(namespace image)及修改日志(edit log)
b、其还保存了一个文件包括哪些数据块,分布在哪些数据节点上。然而这些信息并不存储在硬盘上,而是在系统启动的时候从数据节点收集而成的。
3、数据节点(DataNode)
真正存储数据的地方。客户端(client)或者元数据信息(namenode)可以向数据节点请求写入或者读出数据块。其周期性的向元数据节点回报其存储的数据块信息。
4、从元数据节点(secondary namenode)
从元数据节点并不是元数据节点出现问题时候的备用节点,它和元数据节点负责不同的事情。其主要功能就是周期性将元数据节点的命名空间镜像文件和修改日志合并,以防日志文件过大。这点在下面会相信叙述。合并过后的命名空间镜像文件也在从元数据节点保存了一份,以防元数据节点失败的时候,可以恢复。

二、HDFS 架构原理
HDFS采用master/slave架构。一个HDFS集群包含一个单独的NameNode和多个DataNode。
NameNode作为master服务,它负责管理文件系统的命名空间和客户端对文件的访问。NameNode会保存文件系统的具体信息,包括文件信息、文件被分割成具体block块的信息、以及每一个block块归属的DataNode的信息。对于整个集群来说,HDFS通过NameNode对用户提供了一个单一的命名空间。
DataNode作为slave服务,在集群中可以存在多个。通常每一个DataNode都对应于一个物理节点。DataNode负责管理节点上它们拥有的存储,它将存储划分为多个block块,管理block块信息,同时周期性的将其所有的block块信息发送给NameNode。
下图为HDFS系统架构图,主要有三个角色,Client、NameNode、DataNode。

1、文件写入过程:
Client向NameNode发起文件写入的请求。
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
Client将文件划分为多个block块,并根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
2、文件读取过程:
Client向NameNode发起文件读取的请求。
NameNode返回文件存储的block块信息、及其block块所在DataNode的信息。
Client读取文件信息。
三、HDFS 数据备份
HDFS被设计成一个可以在大集群中、跨机器、可靠的存储海量数据的框架。它将所有文件存储成block块组成的序列,除了最后一个block块,所有的block块大小都是一样的。文件的所有block块都会因为容错而被复制。每个文件的block块大小和容错复制份数都是可配置的。容错复制份数可以在文件创建时配置,后期也可以修改。HDFS中的文件默认规则是write one(一次写、多次读)的,并且严格要求在任何时候只有一个writer。NameNode负责管理block块的复制,它周期性地接收集群中所有DataNode的心跳数据包和Blockreport。心跳包表示DataNode正常工作,Blockreport描述了该DataNode上所有的block组成的列表。
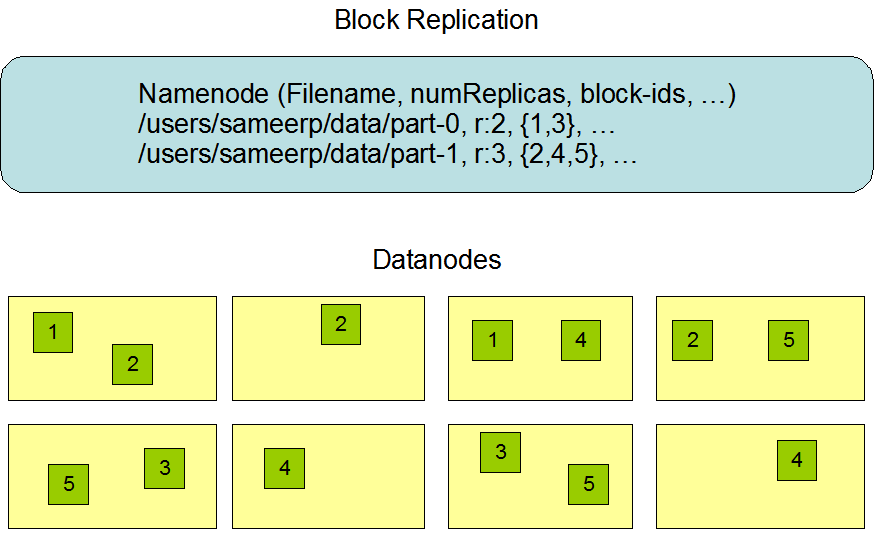
1、备份数据的存放:
备份数据的存放是HDFS可靠性和性能的关键。HDFS采用一种称为rack-aware的策略来决定备份数据的存放。通过一个称为Rack Awareness的过程,NameNode决定每个DataNode所属rack id。缺省情况下,一个block块会有三个备份,一个在NameNode指定的DataNode上,一个在指定DataNode非同一rack的DataNode上,一个在指定DataNode同一rack的DataNode上。这种策略综合考虑了同一rack失效、以及不同rack之间数据复制性能问题。
2、副本的选择:
为了降低整体的带宽消耗和读取延时,HDFS会尽量读取最近的副本。如果在同一个rack上有一个副本,那么就读该副本。如果一个HDFS集群跨越多个数据中心,那么将首先尝试读本地数据中心的副本。
3、安全模式:
系统启动后先进入安全模式,此时系统中的内容不允许修改和删除,直到安全模式结束。安全模式主要是为了启动检查各个DataNode上数据块的安全性。