1.什么是RHCS
RHCS是Red Hat Cluster Suite的缩写,也就是红帽子集群套件,RHCS是一个能够提供高可用性、高可靠性、负载均衡、存储共享且经济廉价的集群工具集合,它将集群系统中三大集群架构融合一体,可以给web应用、数据库应用等提供安全、稳定的运行环境。
更确切的说,RHCS是一个功能完备的集群应用解决方案,它从应用的前端访问到后端的数据存储都提供了一个行之有效的集群架构实现,通过RHCS提供的这种解决方案,不但能保证前端应用持久、稳定的提供服务,同时也保证了后端数据存储的安全。
RHCS提供了集群系统中三种集群构架,分别是高可用性集群、负载均衡集群、存储集群。
RHCS提供的三个核心功能
高可用集群是RHCS的核心功能。当应用程序出现故障,或者系统硬件、网络出现故障时,应用可以通过RHCS
提供的高可用性服务管理组件自动、快速从一个节点切换到另一个节点,节点故障转移功能对客户端来说是透
明的,从而保证应用持续、不间断的对外提供服务,这就是RHCS高可用集群实现的功能。
RHCS通过LVS(Linux Virtual Server)来提供负载均衡集群,而LVS是一个开源的、功能强大的基于IP的负载均衡技术,LVS由负载调度器和服务访问节点组成,通过LVS的负载调度功能,可以将客户端请求平均的分配到各个服务节点,同时,还可以定义多种负载分配策略,当一个请求进来时,集群系统根据调度算法来判断应该将请求分配到哪个服务节点,然后,由分配到的节点响应客户端请求,同时,LVS还提供了服务节点故障转移功能,也就是当某个服务节点不能提供服务时,LVS会自动屏蔽这个故障节点,接着将失败节点从集
群中剔除,同时将新来此节点的请求平滑的转移到其它正常节点上来;而当此故障节点恢复正常后,LVS又会自动将此节点加入到集群中去。而这一系列切换动作,对用户来说,都是透明的,通过故障转移功能,保证了服务的不间断、稳定运行。
RHCS通过GFS文件系统来提供存储集群功能,GFS是Global File System的缩写,它允许多个服务同时去读写一个单一的
RHCS集群的搭建
1.准备阶段
因为是实验,所以我们只需要做两个节点,我们要做高可用,负载均衡和存储文件系统的集群,那么我们就要为其配置yum源,我们的节点分别为server1和server2
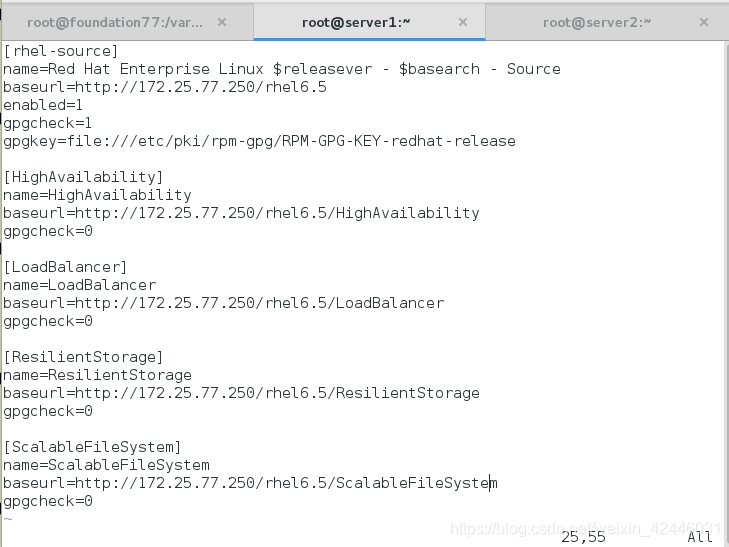
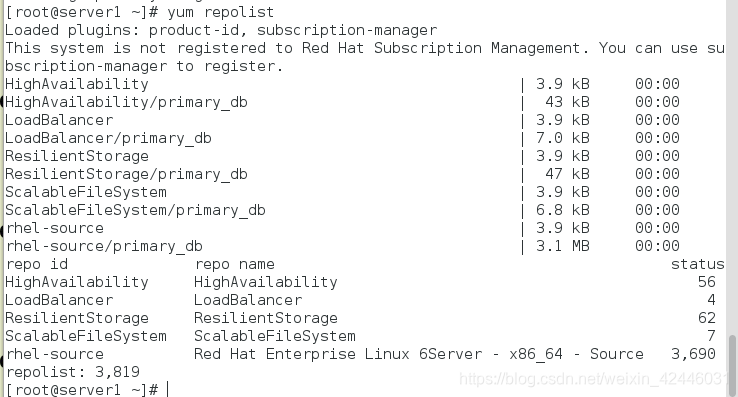
server1和server2要配置成一样的
2.两个节点安装ricci和luci
ricci:集群管理软件
luci:集群管理的web界面

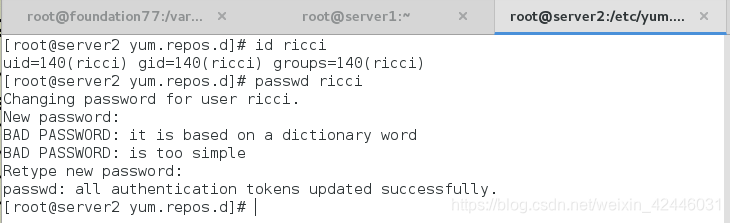
3.给ricci管理者用户添加密码
在我们安装了ricci之后我们是可以看到系统会多一个ricci用户,那么我们就给他一个密码,这样是的我们的集群管理更加的安全
4.server1和server2开启ricci和luci,并设置开机自启动
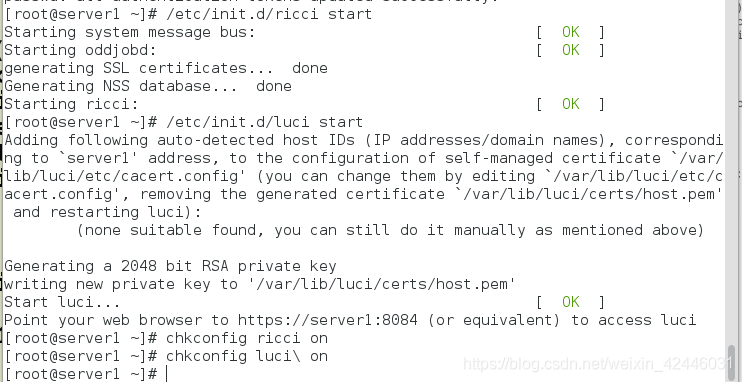
5.利用浏览器登陆luci查看
这里需要注意的是luci的端口是8084,且登陆是要加https

我们选择不要证书
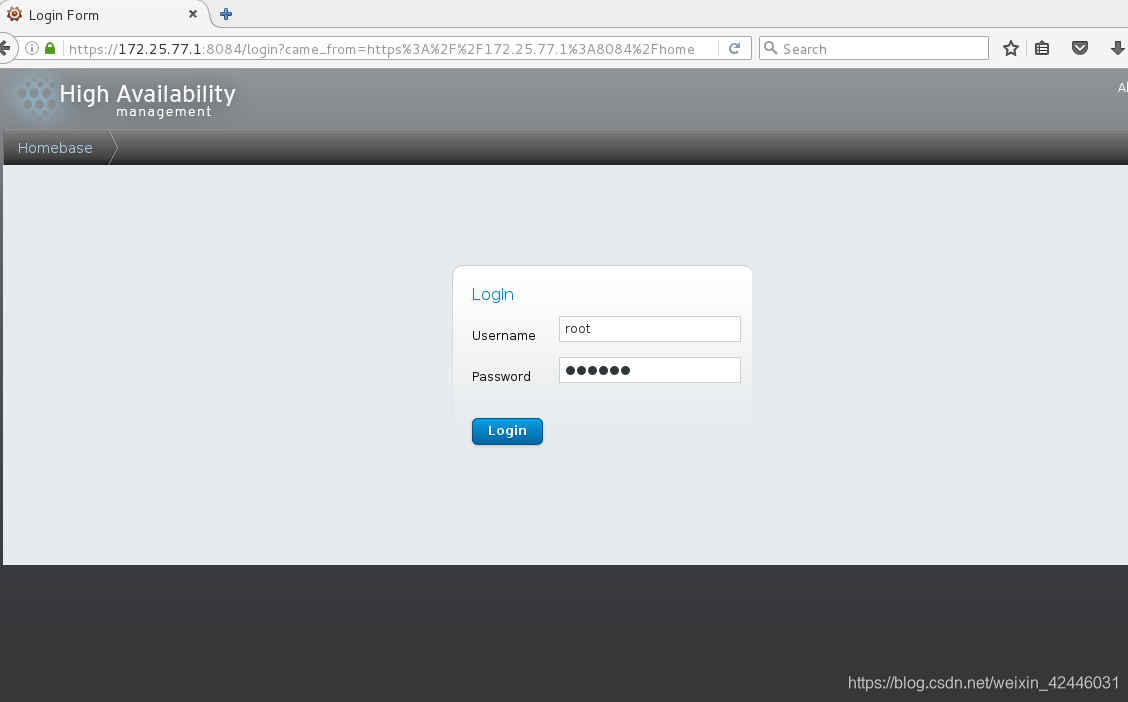
登陆密码使我们刚才给ricci的密码
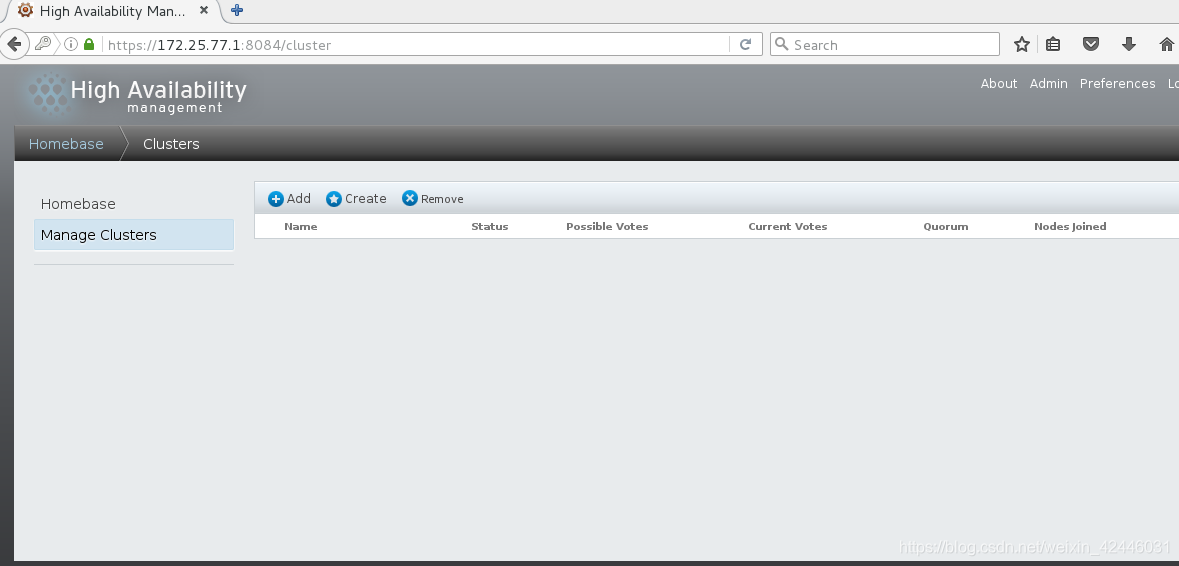
6.添加集群并添加节点
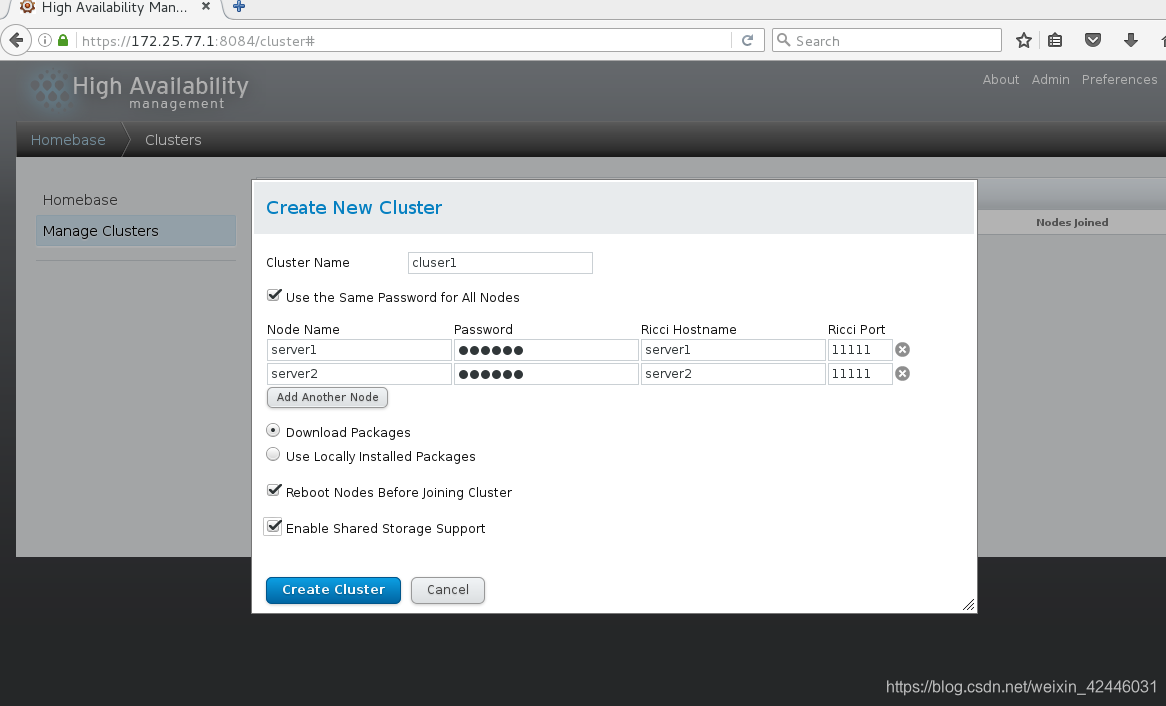
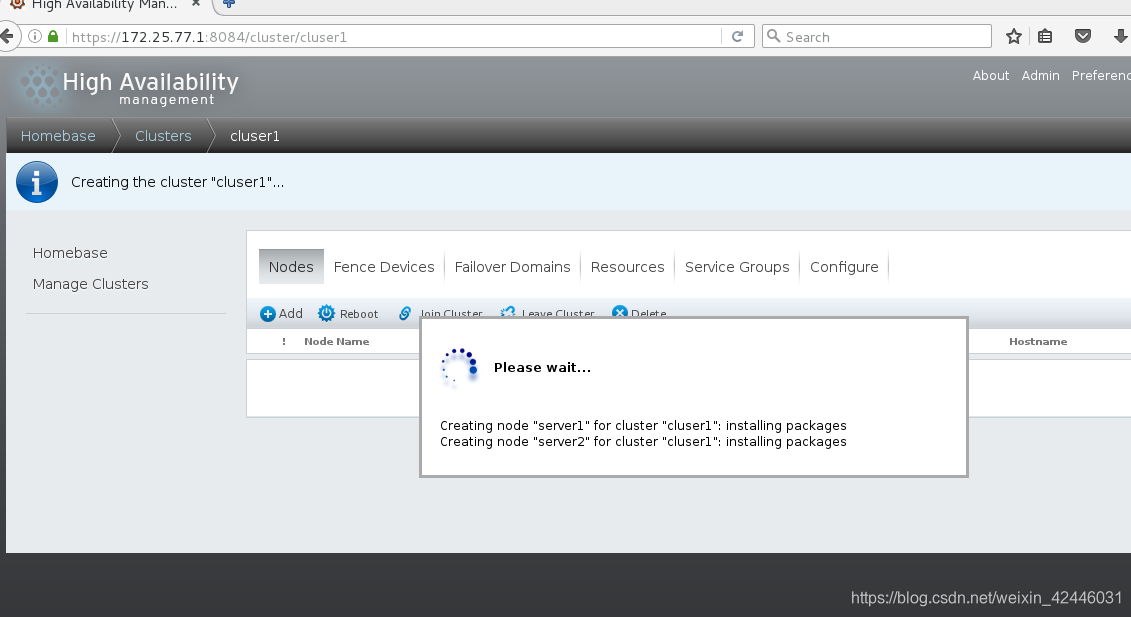
然后等待,等待时随时注意节点机的ricci和luci服务状态,因为节点的加入会断掉服务,需要我们手动开启
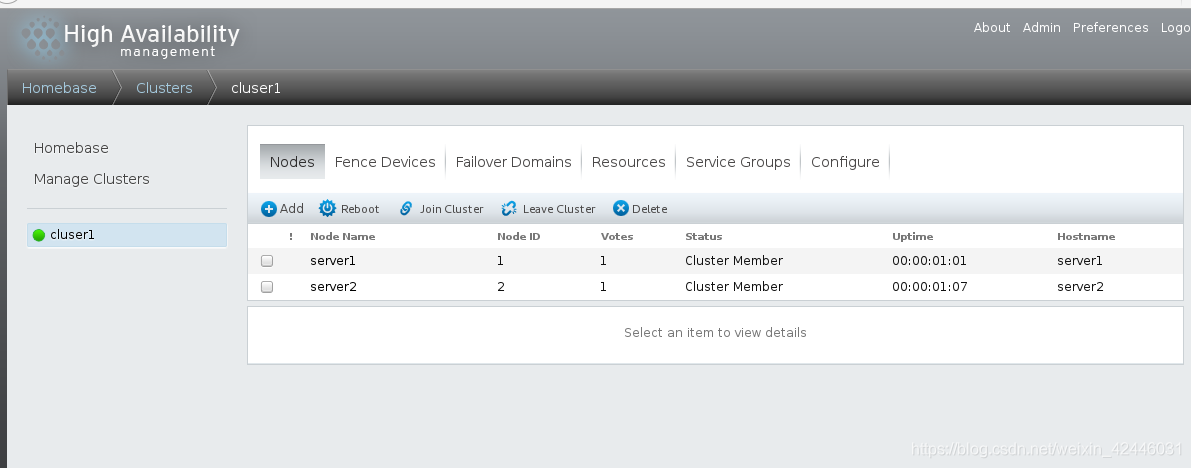
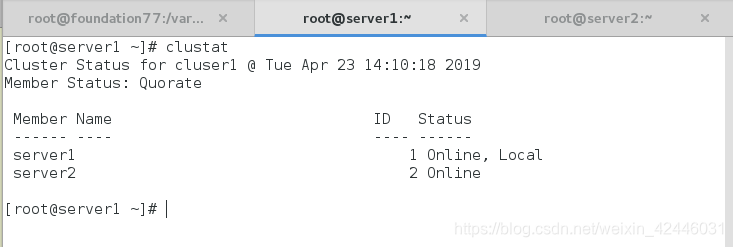
我们还可以手动查看集群的属性

7.fence
fence:脑裂现象,通过软件来控制硬件,可以将有问题的设备隔离出来,有点像直接关闭出问题主机的物理电源
我们在真机安装fence,初始化fence

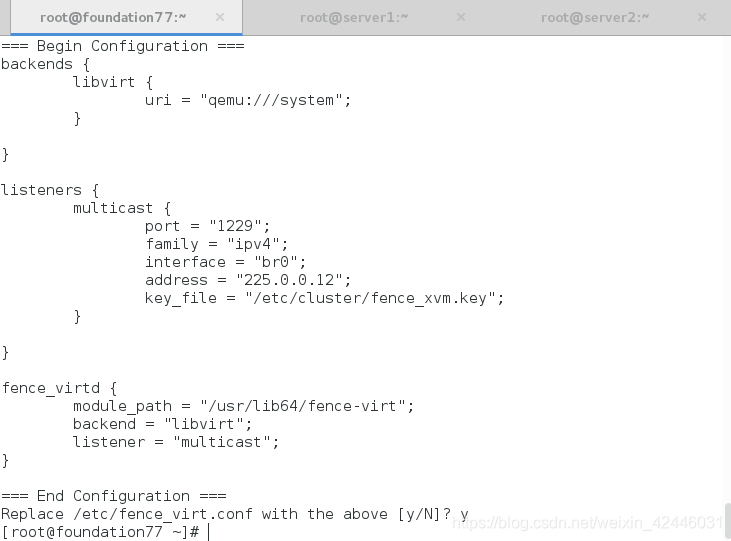
大部分内容选择默认即可
查看fence刚才初始化生成的key

我们发现其时并没有生成,那是因为我们的fence缺少了libvirt和multicast模块,那么我们需要安装两个模块并且重新初始化
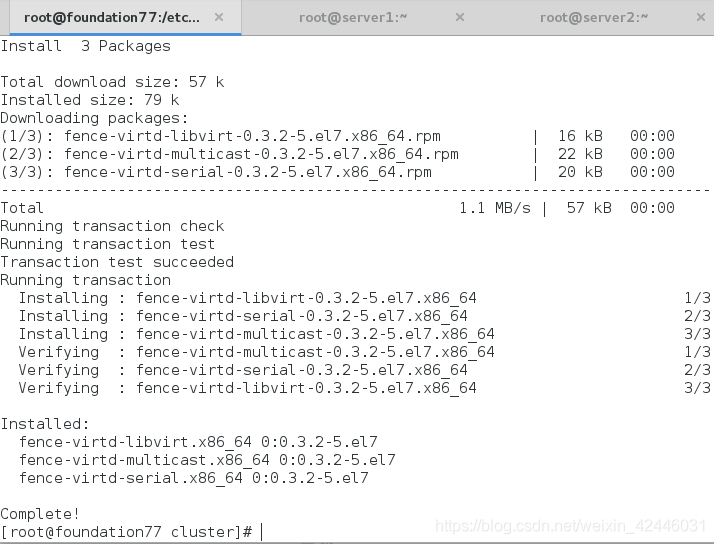
如果还没有生成fence的密钥的话我们则可以通过手动截取一个密钥

然后将生成的密钥传给server1和server2
真机开启fence
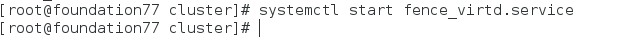
在网页上添加fence
然后在Nodes中分别为server1和server2添加fence
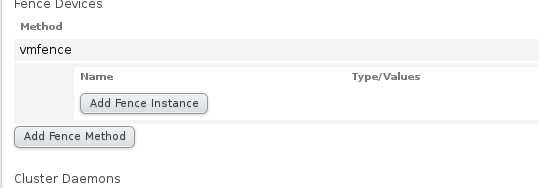

因为在这里我们要为server1和server2添加唯一辨认标志,ip等时可变的,那么UUID则时固定不可变的,满足我们的要求,我们通过虚拟机的图形化管理查看虚拟机的UUID


server2同server1相同
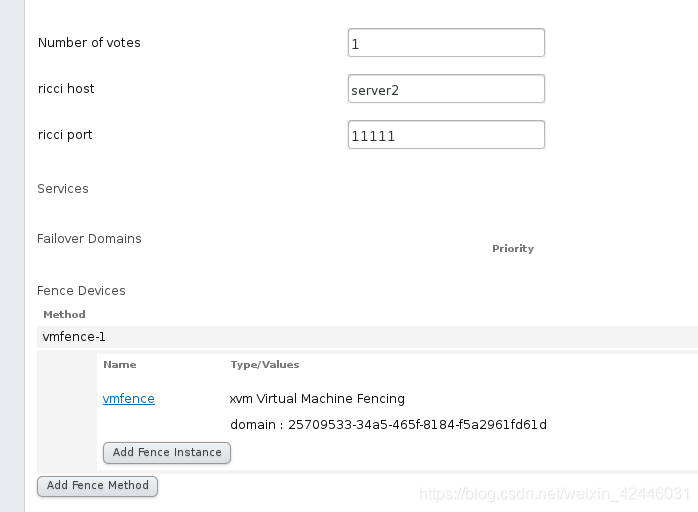
我们在真机测试server1上测试fence

我们会发现server2自动挂掉了,相当于关闭了其物理电源
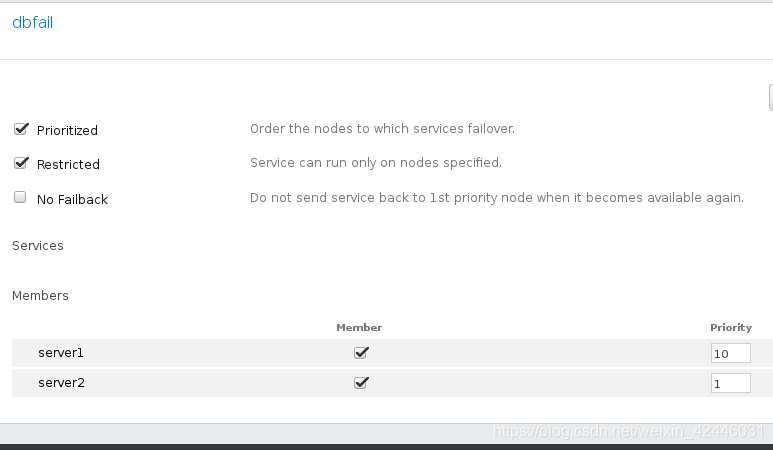
8.Failover Domains
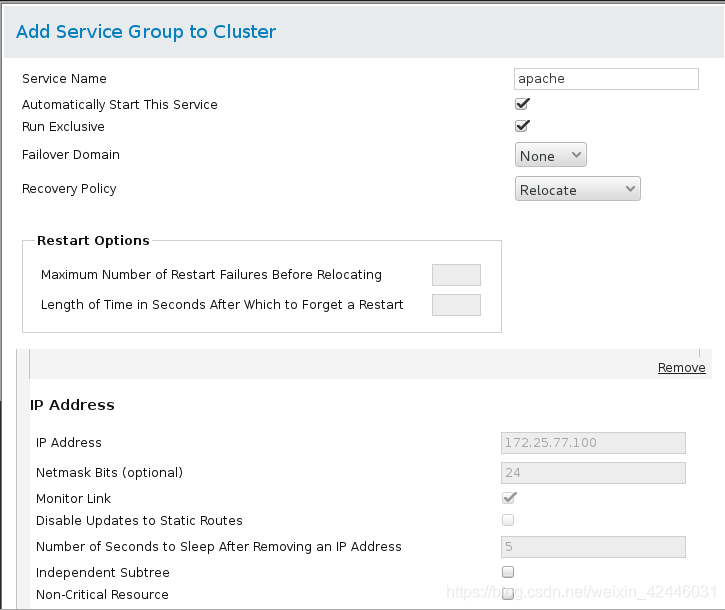
加下来我们来添加时间回切(将挂掉的服务重启),选择优先机高的,然后添加相应的资源服务,使集群可以自动管理服务
apache
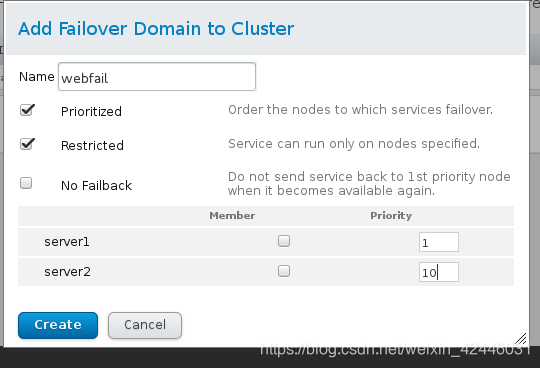
在这里我们添加一个webfail域,并且设置节点的优先机,数字越小优先机越高
9.添加域中的资源
我们接下来做高可用,那么我们需要一个虚拟主机
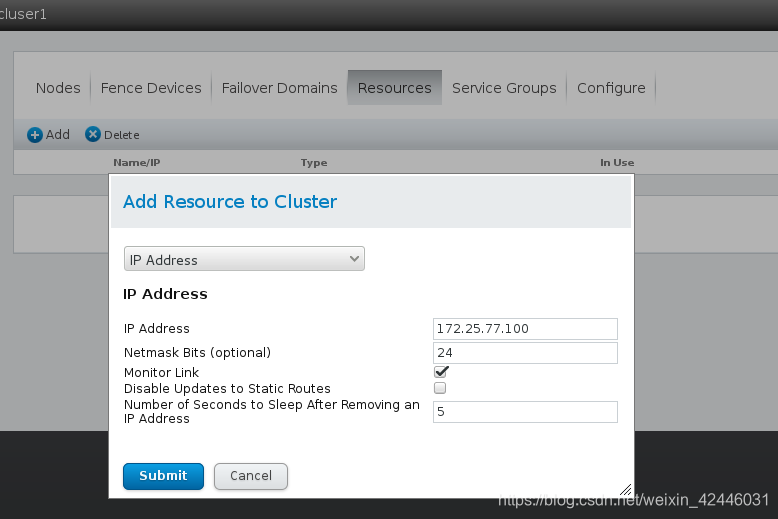
添加服务,包括服务名和服务启动脚本
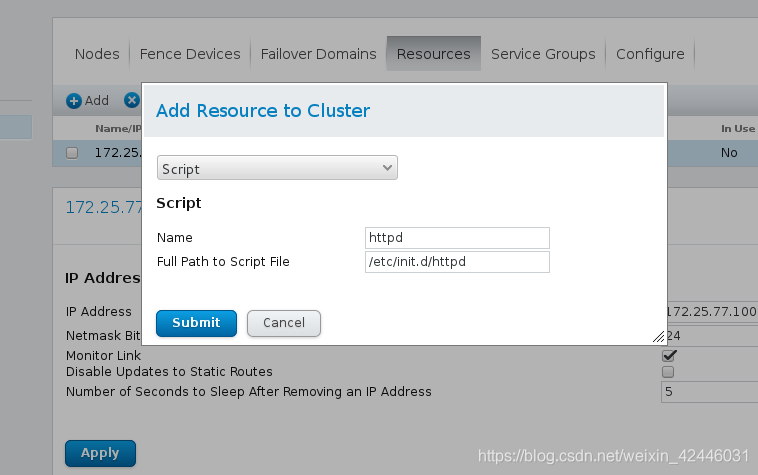
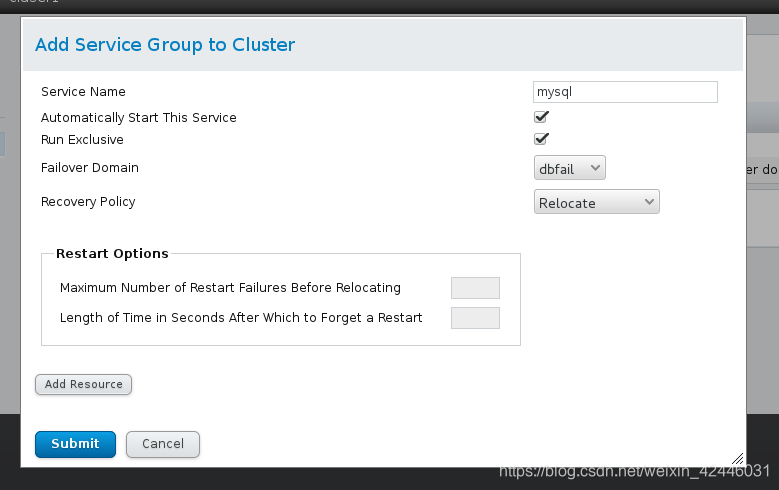
10.添加群组
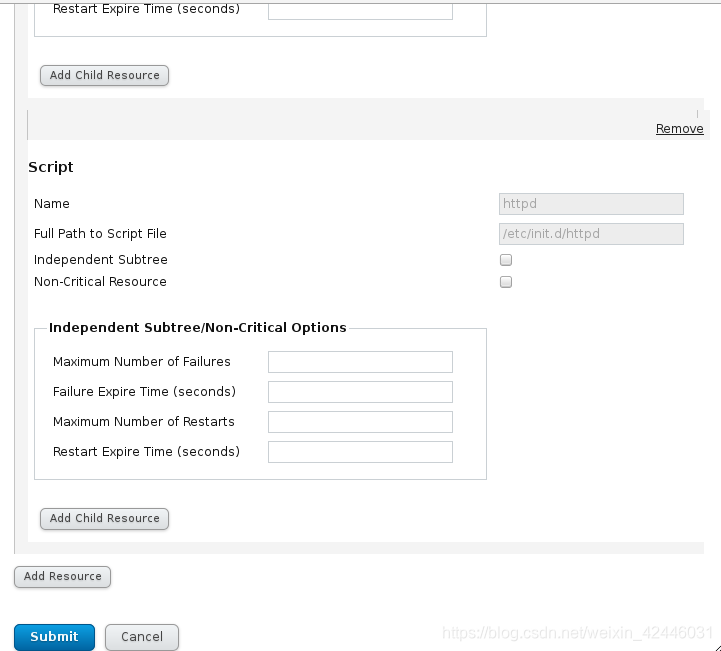
11.server1和server2安扎unghttpd并且书写默认发布目录,并在网也启动apache群组

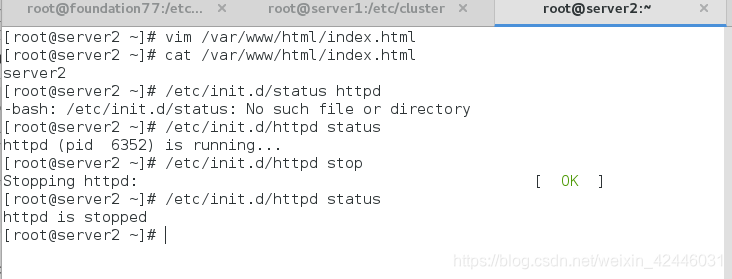

我们成功启动server2的httpd服务

然后我们将server2整崩溃
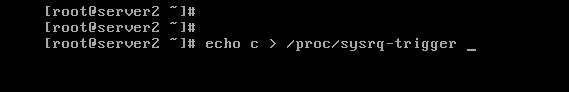
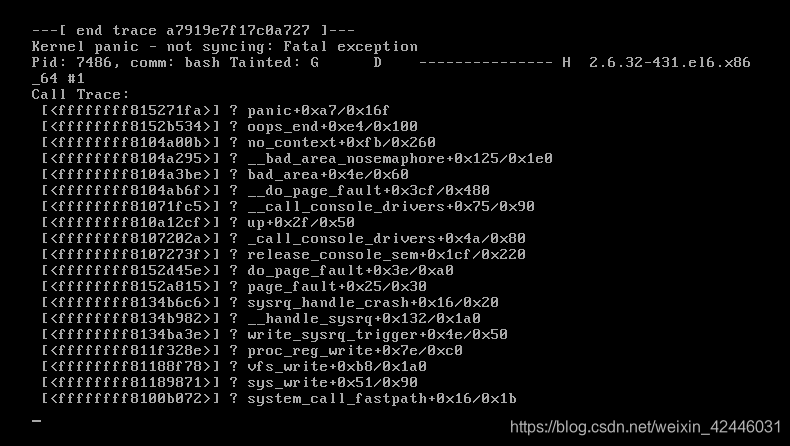
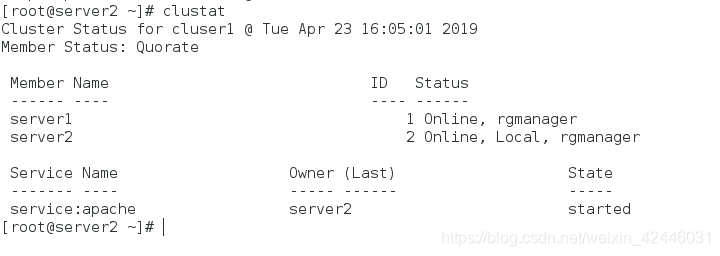
我们再来看server1

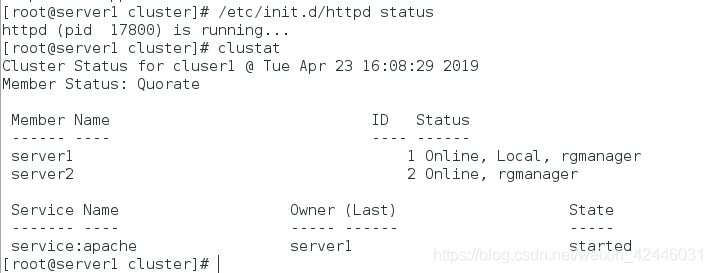
我们可以很清楚的发现当server2挂掉后server1重新开启httpd服务,实现高可用,防止单点故障
集群存储管理
在前面我们做了集群的高可用,那么接下来我们来做锦群的存储管理
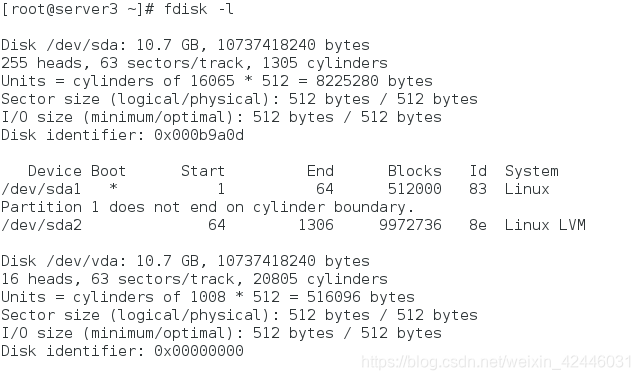
1。首先我们需要一台虚拟机来通过iscsi设备做共享存储

server3编辑配置文件然后将设备共享出去
vim /etc/tgt/target.conf


tgt-admin -s 查看共享设备
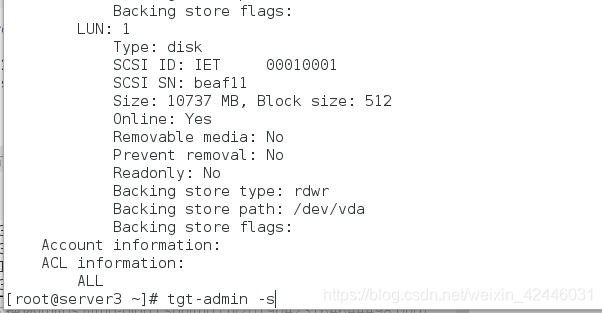
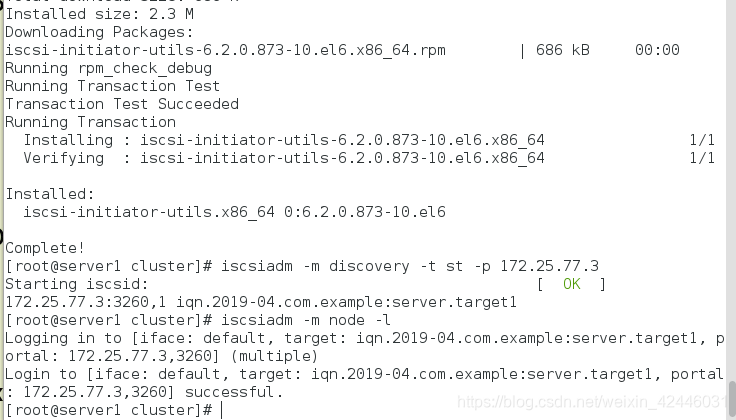
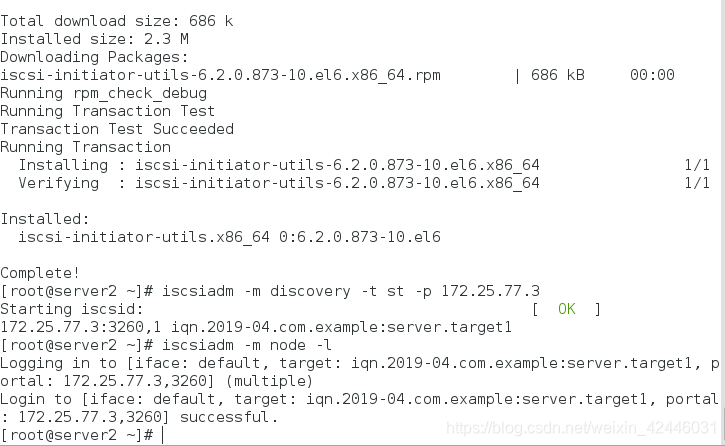
2.server1和server2寻找共享设备并登陆
fdisk -l查看设备
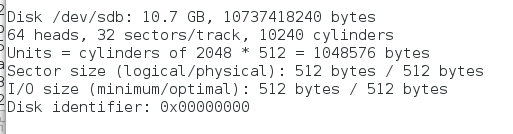
那么接下来我们需要将共享的设备做成可用的逻辑卷
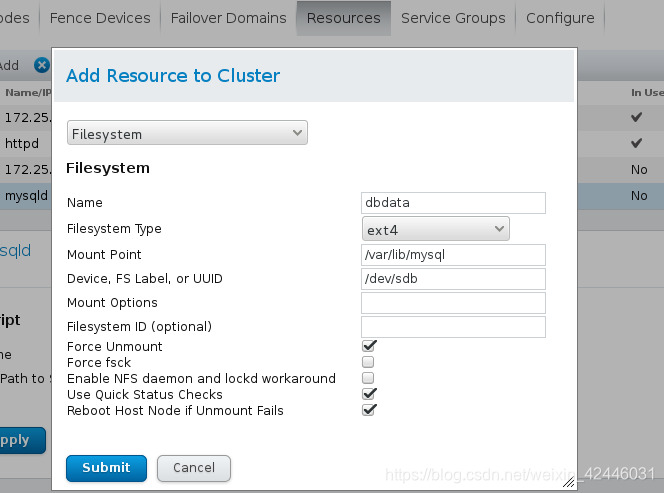
然后我们格式化磁盘/dev/sdb

安装mysql-server,通过mysql将设备共享出去

我么将设备挂载到mysql目录中,并且修改mysql目录的用户和用户组为mysql
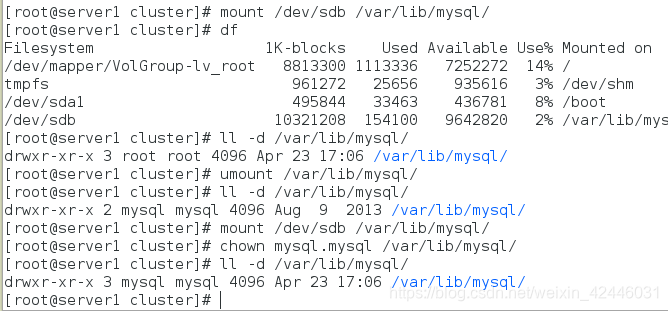
然后启动mysql进行初始化,生成mysql数据库
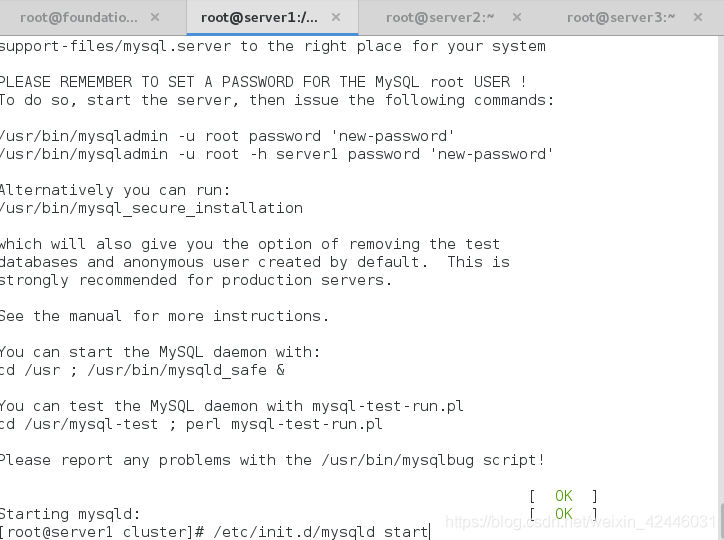

然后关闭mysql,
注意:server2只用安装mysql,并不用做格式化等处理
3.在web页面台添加资源等
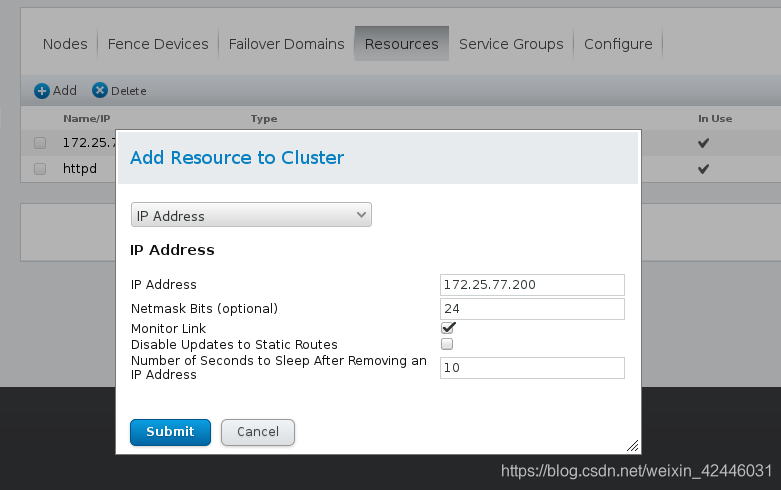
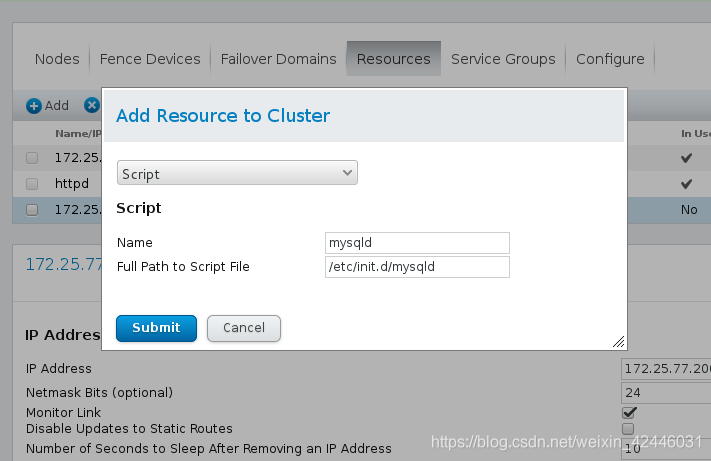


4.关闭apache,开启mysql
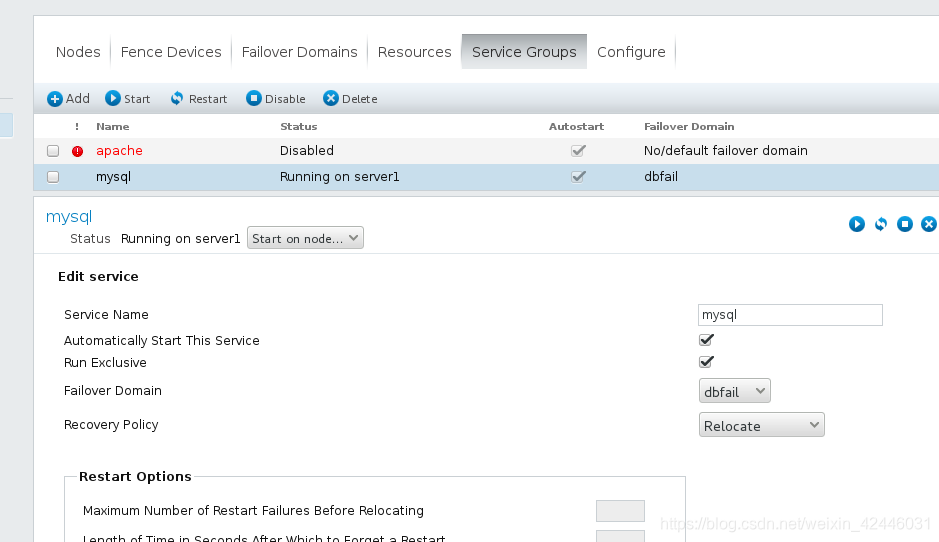

发现server2自动挂载
5.在server1上关闭mysql,过一段时间后自动卸载,然后查看server2
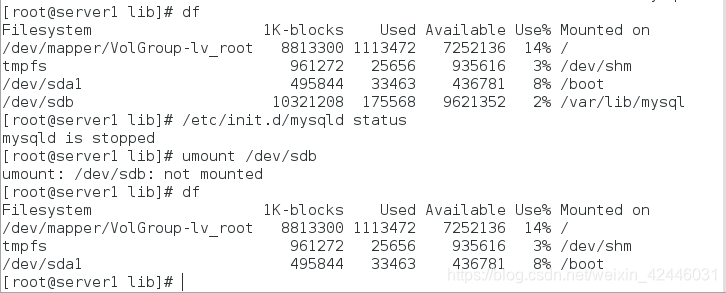
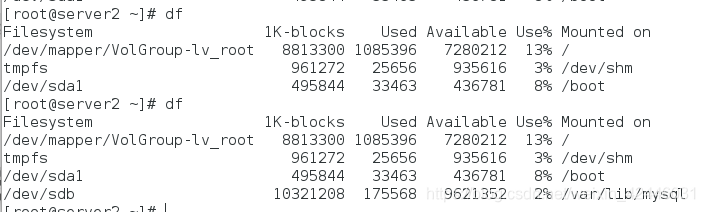
手动控制集群
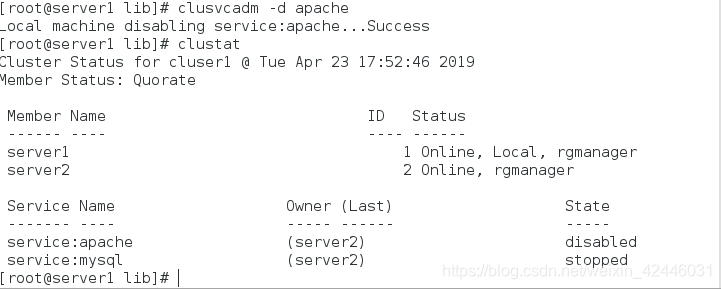
我们有些时候也可以不通过web界面去控制集群,也可以通过clusvcadm去手动控制
首先我们查看一下clusvcadm的帮助

开启群组

指定节点
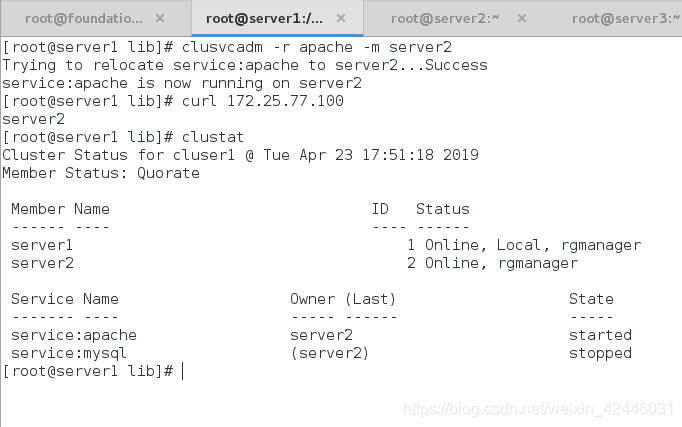
停止群组即部运行
集群存储的多点写入
在刚才我们的集群存储中我们使用的是ext4格式的磁盘,但这种格式由各不好的就是它是单点写入的,如果我们在两个后端存储服务器使用ext4格式,如果正在运行的后端服务器挂掉,那么它的数据是无法在另外一台存储服务器上出现之前的数据,这时我们就需要使用GFS2格式,因为它可以实现多点写入,即可以将写入的数据同步到另外一台后端存储服务器中
在之前我们需要查看我们的逻辑卷是否可以在集群中使用
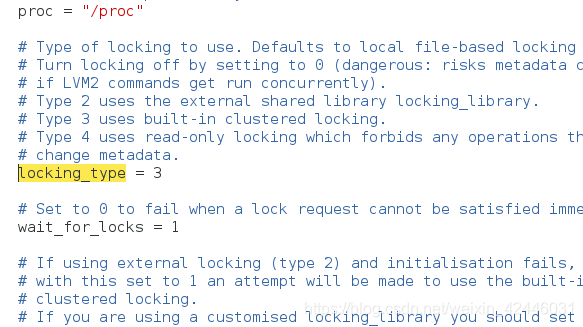
如果locking_type等于1,则是表示不可使用,这时我们就要使用命令lvmconf --enable-cluster去改变他的数值
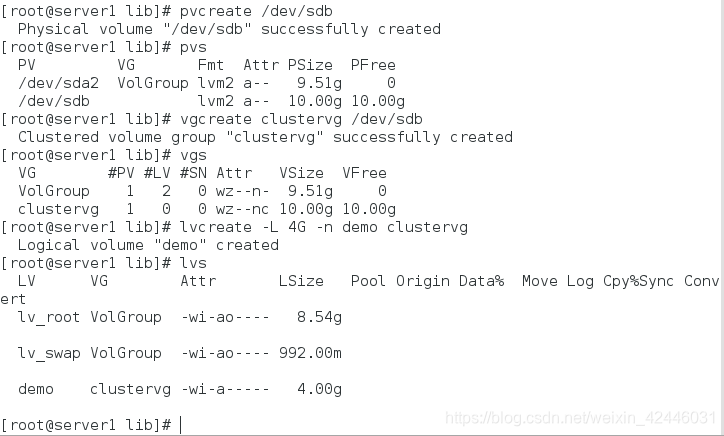
我们创建新的逻辑卷
pvcreate /dev/sdb
vgcreate clustervg /dev/sdb
lvcreate -L 4G -n demo clustervg #创建大小为4G的逻辑卷demo
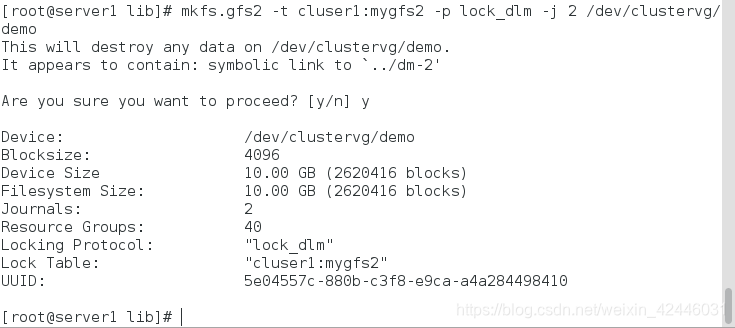
格式化逻辑卷
mkfs.gfs2 -t cluser1:mygfs2 -p lock_dlm -j 2 /dev/clustervg/demo #-j 2 表示两个设备
DLM锁管理
表示一个分布式锁管理器,他是RHCS的一个底层基础构建,同时也为集群提供了一个公用的锁运行机制,在RHCS中,DLM运行在集群的每个节点上,GFS通过锁管理机制来同步访问数据系统元数据,CLVM通过锁管理其来同步更新数据到LVM卷和逻辑卷, DLM 不需要设定锁骨哪里服务器,它采用对等的锁管理方式,大大提高了处理性能,同时,DLM避免了当单个节点失败需要整体恢复的性能瓶颈,另外,DLM的请求都是本地的,不需要网络请求,因而请求会立即生效,最后,DLM通过分层机制,可以实现多个锁空间的并行管理模式
我们的gfs2时可以扩展的,所以我们可以对其进行扩容处理
lvextend -L +6G /dev/clustervg/demo
e2fsck -f /dev/clustervg/demo
resize2fs /dev/clustervg/demo
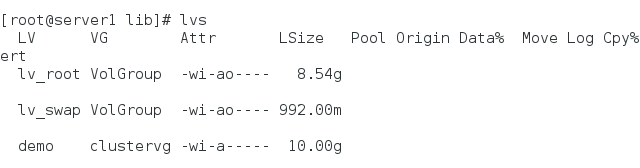
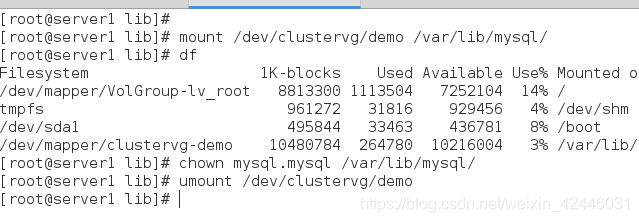
修改挂载后的用户和用户组,然后开启mysql
多点写入的尝试


我们可以轻易的发现我们在server2上的两次ls出现的文件里面第二次多了passwd这个文件,这就是我们的多点写入,我们在server1上写入了passwd这个文件,他就同步到server2上了
server1设置自动挂载
vim /etc /fstab

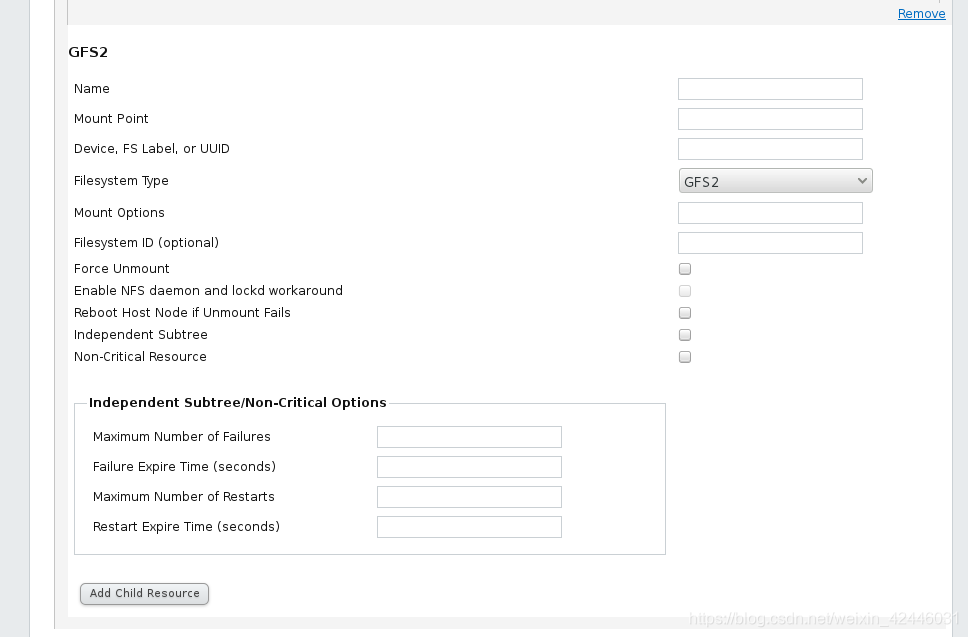
在web界面删除掉刚才的filesystem,添加GFS2的文件系统

注意:在组中删除后一定要记的保存
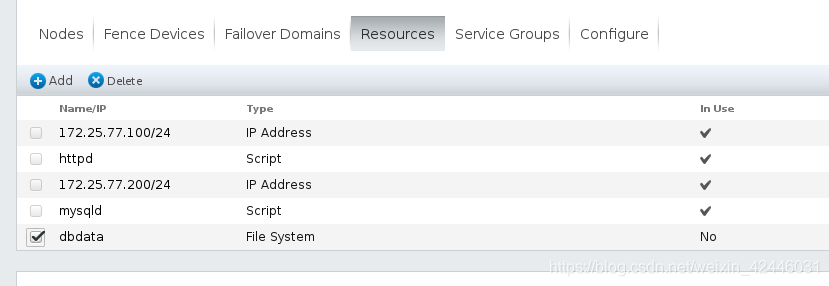

添加新的文件系统

 然后开启mysql的集群组
然后开启mysql的集群组

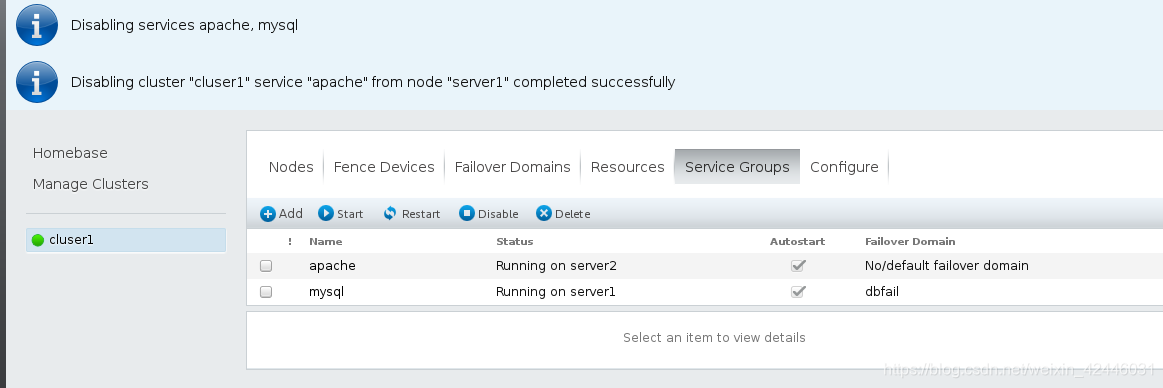
集群配置的删除
1.服务组暂停
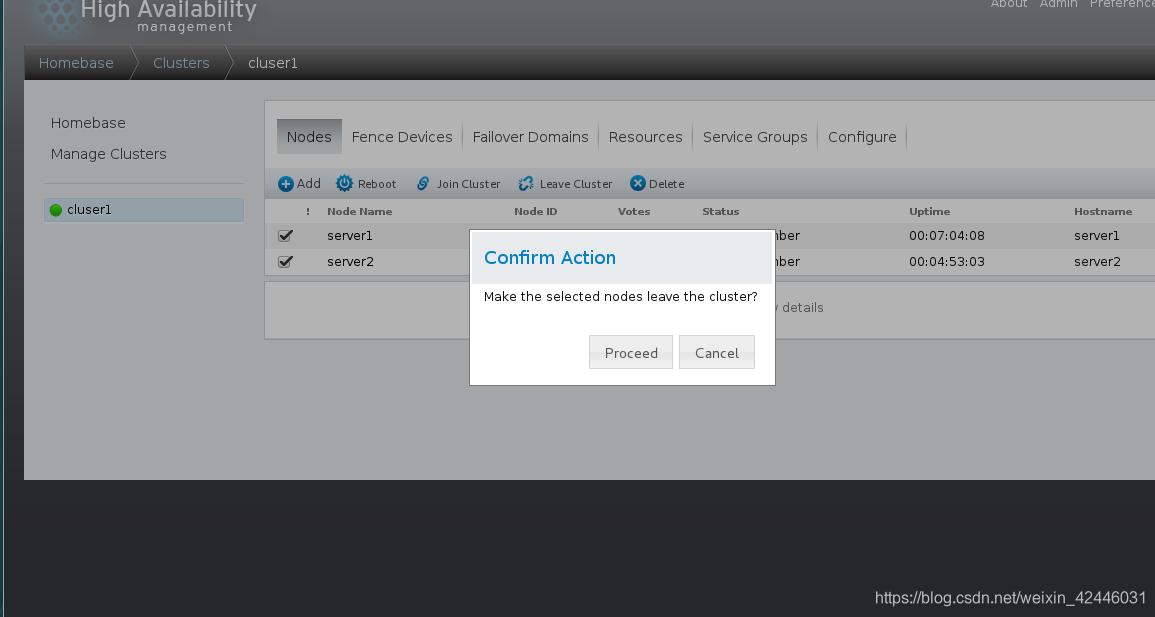
2.节点离开
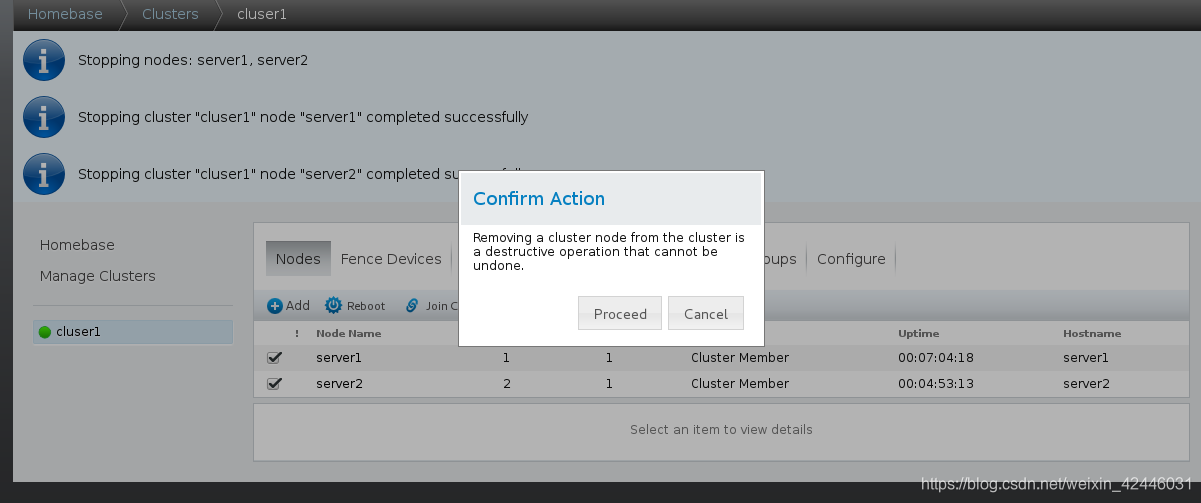
3.删除节点
CAMN和rgmanager
我们在之前做实验的时候应该注意到几个服务

这些里面有一些我们在本章可能建国的,其中比较重要的两个就是CMAN和rgmanager
Cluster manager 简称CMAN,是一个分布式集群管理工具,运行在集群的各个节点上,为RHCS提供集群管理任务。
它用于管理集群成员、消息和通知。它通过监控每个节点的运行状态来了解节点成员之间的有关系。当集群中某个节点
出现故障时,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。
CMAN根据每个节点的运行状态,统计出一个法定节点数,作为集群是否存活的依据。当整个集群中有多于一半的
节点处于激活状态时,表示达到了法定节点数,此集群可以正常运行,当集群中有一半或少于一半的节点处于激活
状态时,表示没有达到法定的节点数,此时整个集群系统将变得不可用。CMAN依赖于CCS,并且CMAN通过CCS读取
cluster.conf文件。
rgmanager主要用来监督、启动、停止集群的应用、服务和资源。当一个节点的服务失败时,高可用集群服务管理
进程可以将服务从这个失败节点转移至其点健康节点上,这种服务转移能力是自动动,透明的。RHCS通过rgmanager
来管理集群服务,rgmanager运行在每个集群节点上,在服务器上对应的进程为clurgmgrd。
在RHCS集群中,高可用生服务包括集群服务和集群资源两个方面。集群服务其实就是应用,如APACHE,MYSQL等。
集群资源有IP地址,脚本,EXT3/GFS文件系统等。
在RHCS集群中,高可用性服务是和一个失败转移域结合在一起的。由几个节点负责一个特定的服务的集合叫失败转移域,
在失败迁移域中可以设置节点的优先级,主节点失效,服务会迁移至次节点,如果没有设置优先,集群高可用服务将在任
意节点间转移。
我们在关闭了web后还奥关闭一些相应的服务

当然server2同1一样也得关闭