记录pandas中实现和SQL相同操作的语句
union all -- 不去重
union -- 默认distinct去重
intersect -- 默认distinct去重
except -- 默认distinct去重
1 #coding=gbk 2 import numpy as np 3 import pandas as pd 4 from pandas import DataFrame,Series 5 df1=DataFrame({'a':[1,2,3],'b':[4,5,6]}) 6 df2=DataFrame({'a':[1,2,8],'b':[4,7,9]}) 7 print('df1') 8 print(df1) 9 print('df2') 10 print(df2) 11 print('union all的结果') 12 print(pd.concat([df1,df2])) 13 print('union的结果') 14 print(pd.concat([df1,df2]).drop_duplicates()) 15 print('union并且重建索引的结果') 16 print(pd.concat([df1,df2]).drop_duplicates().reset_index(drop=True)) 17 print('intersect的结果') 18 print(df1.merge(df2).drop_duplicates()) 19 print('伪except的结果') 20 print(df1[df1.isin(df2)==False].dropna(how='all')) 21 print('except的结果') 22 print(df1.append(df2).append(df2).drop_duplicates(keep=False))
结果如下
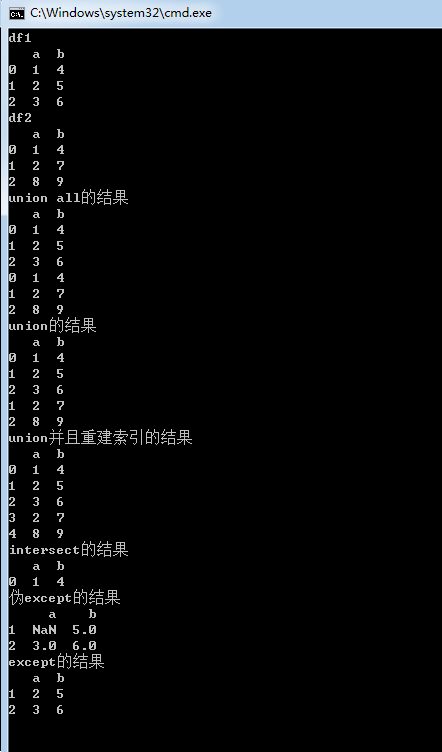
drop_duplicates()的默认keep='first' 保留第一个 keep='False' 代表有重复则全部删除
可能在某种情况下并不完全等价 仅提供参考
谢谢!