linux系统下结巴分词库(cppjieba)的下载和应用
本文详细介绍linux系统下结巴分词库(cppjieba)的下载编译以及在c++项目中使用。操作过程全部由作者测试实现。作者的系统环境如下:
- linux操作系统:CentOS 7
- linux内核版本:3.10.0-327.el7.x86_64(命令$uname -r查看)
- g++版本:g++ (GCC) 4.8.5 20150623 (Red Hat 4.8.5-11)
- cmake版本:cmake version 2.8.12.2
cppjieba的下载
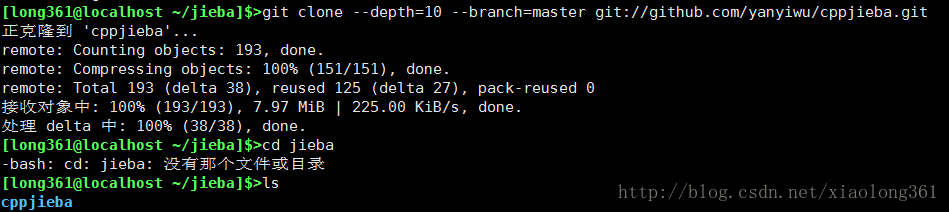
在linux系统可以访问互联网的前提下,可以在指定文件夹下执行下列命令,从而将cppjieba的软件包下载到本地该文件夹下:
git clone –depth=10 –branch=master git://github.com/yanyiwu/cppjieba.git
下载后的结果如下图所示:
如果希望下载cppjieba的软件包的打包文件也可以直接点击网址:GitHub-yanyiwu/cppjieba,然后点击“Clone or download”下载压缩包即可。
cppjieba的编译和测试
在cppjieba的GitHub下载界面可以看到,其依赖软件为:
- g++ (version >= 4.1 is recommended) or clang++;
- cmake (version >= 2.6 is recommended);
使用git命令下载好cppjieba软件包并确保本地软件符合上述要求之后,执行下列命令对其进行编译:
cd cppjieba
mkdir build
cd build
cmake ..
make
编译完成后build文件夹下的内容如下图所示:

编译完成后,使用如下命令,即可运行其demo程序:
./demo
运行之后结果如下图所示:
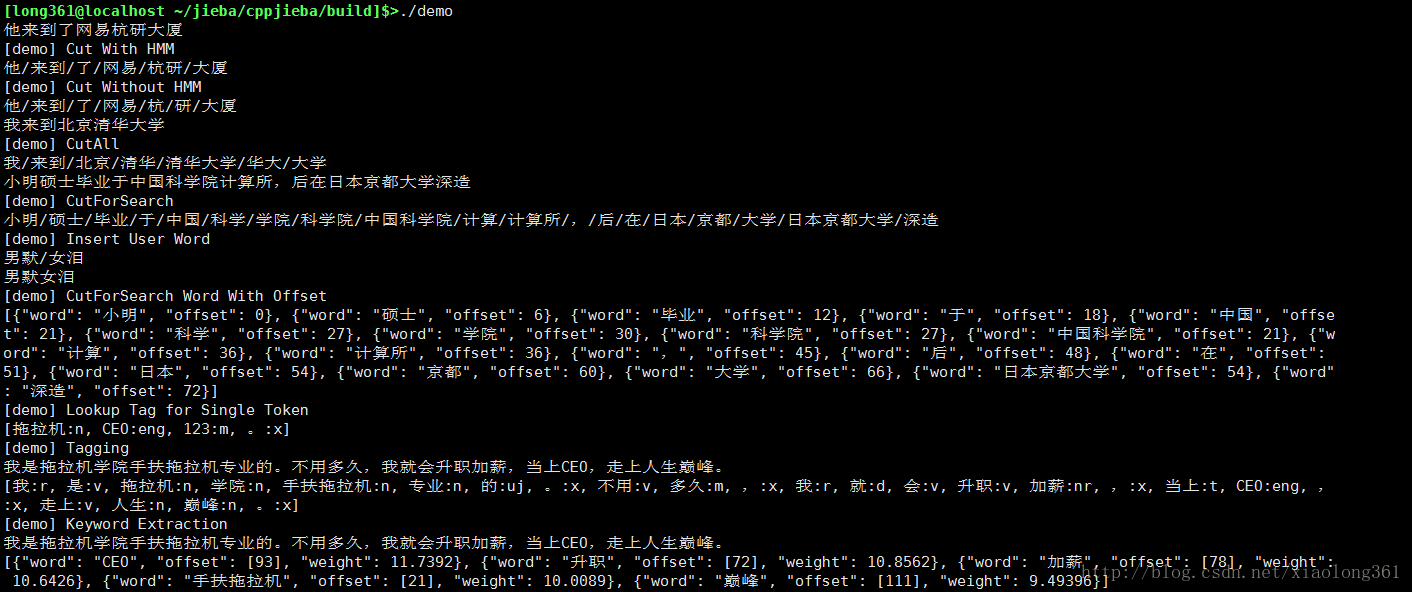
cppjieba在c++项目中的应用
上述运行的demo程序源程序位于“cppjieba\test”中,根据该demo程序及其结果,可以发现要使用结巴分词库进行分词,首先需要创建cppjieba::Jieba对象,创建时需要传入相关词典的路径信息。然后使用创建的cppjieba::Jieba进行不同类型的分词操作。
下面展示在一个c++项目中应用结巴分词库cppjieba的具体过程:
方便起见,我们将结巴分词库的使用封装成一个WordSegmentation类,并将其声明和实现均放在“WordSegmentation.hpp”文件中。WordSegmentation.hpp文件的内容如下:
#ifndef _MY_WORD_SEGMENTATION_H_
#define _MY_WORD_SEGMENTATION_H_
#include "cppjieba/Jieba.hpp"
#include <iostream>
#include <string>
#include <vector>
using std::cout;
using std::endl;
using std::string;
using std::vector;
const char * const DICT_PATH = "/home/long361/jieba/cppjieba/dict/jieba.dict.utf8";//最大概率法(MPSegment: Max Probability)分词所使用的词典路径
const char * const HMM_PATH = "/home/long361/jieba/cppjieba/dict/hmm_model.utf8";//隐式马尔科夫模型(HMMSegment: Hidden Markov Model)分词所使用的词典路径
const char * const USER_DICT_PATH = "/home/long361/jieba/cppjieba/dict/user.dict.utf8";//用户自定义词典路径
const char* const IDF_PATH = "/home/long361/jieba/cppjieba/dict/idf.utf8";//IDF路径
const char* const STOP_WORD_PATH = "/home/long361/jieba/cppjieba/dict/stop_words.utf8";//停用词路径
class WordSegmentation//使用结巴分词库进行分词
{
public:
WordSegmentation()
: _jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH,IDF_PATH,STOP_WORD_PATH)//初始化Jieba类对象
{
cout << "cppjieba init!" << endl;
}
vector<string> operator()(const string str)//返回str的分词结果
{
vector<string> words;
_jieba.CutAll(str, words);//FullSegment
return words;
}
private:
cppjieba::Jieba _jieba;
};
#endif这里只封装了cppjieba::Jieba类中的一个CutAll函数用作演示。需要注意的是,需要将cppjieba软件包中的文件夹“cppjieba\include\cppjieba”放到该头文件所在的文件夹下。另外,由于cppjieba中的头文件”QuerySegment.hpp“包含了文件夹“cppjieba\deps\limonp\”中头文件的内容,因此可以直接将该limonp文件夹也复制到c++项目中cppjieba文件夹中,即可解决这一问题。如果为复制limonp文件夹,则在程序编译时可能会出现下图所示的情况:

下面是测试程序test_jieba.cpp中的内容:
#include"WordSegmentation.hpp"
#include<iostream>
#include<string>
#include<vector>
using std::cout;
using std::endl;
using std::string;
using std::vector;
int main()
{
string str="结巴分词库的下载和应用";
WordSegmentation wordSeg;
vector<string> results=wordSeg(str);
cout<<"分词结果如下:"<<endl;
for(auto it=results.begin();it!=results.end();++it)
{
cout<<*it<<" ";
}
return 0;
}执行编译后的程序,即可得到如下图所示的结果,可以看到屏幕打印出了分词的结果:
