物理内存的划分
Linux把每个物理内存划分成3个管理区
| 内存区域 | 说明 |
|---|---|
| ZONE_DMA | 范围是0~16M,该区域的物理页面专门供I/O设备的DMA使用 |
| ZONE_NORMAL | 范围是16~896M,该区域的物理页面是内核能够直接使用的 |
| ZONE_HIGHMEM | 范围是896~结束,高端内存,内核不能直接使用 |
高端内存的由来
通常32位Linux内核地址空间划分0 ~ 3G为用户空间,3 ~ 4G为内核空间
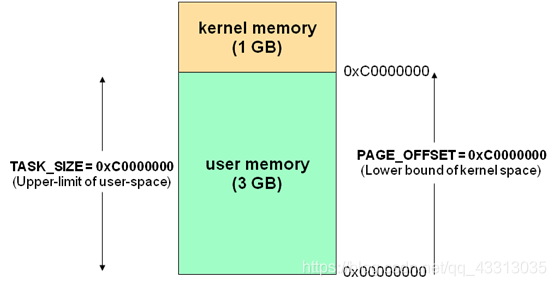
当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射。
物理地址 = 逻辑地址 – 0xC0000000

假设按照上述简单的地址映射关系,内核只能访问1G物理内存空间
存在这样一个问题:由于内核只能访问1G物理内存空间,如果物理内存是2G,那内核如何访问剩余的1G物理内存空间呢?
由本文开始我们知道物理内存地址被划分成了3个Zone,其中0~ 896M是内核直接可以访问的,896M ~ 2G这一部分内核要如何访问呢?
实际上内核想访问高于896M的物理地址时,从0xF8000000~ 0xFFFFFFFF虚拟地址空间中取一部分与想要访问的物理内存建立映射即填充内核PTE页表(内核页表),访问完成之后内核释放0xF8000000~0xFFFFFFFF中的虚拟地址空间,以便其它进程访问。(采用这128M的虚拟空间,建立临时地址映射,完成了对所有高于896M物理内存的访问)
如下图所示

1G的虚拟内核空间如下图
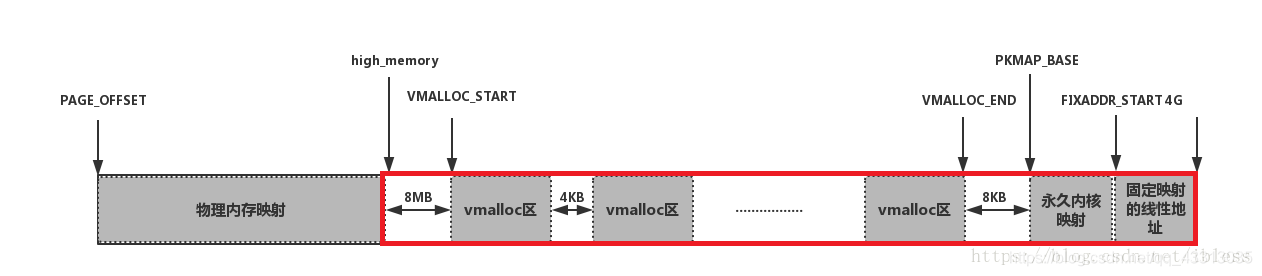
上图中PAGE_OFFSET通常为0xC000 0000,而high_memory指的是0xF7FF FFFF,在物理内存映射区和和第一个vmalloc区之间插入的8MB的内存区是一个安全区,其目的是为了“捕获”对内存的越界访问。处于同样的理由,插入其他4KB大小的安全区来隔离非连续的内存区。
内核空间的映射
Linux内核可以采用以下机制将页框映射到内核空间
| 虚拟内存区域 | 说明 |
|---|---|
| 物理内存映射 | 映射物理内存空间0~896M部分,这一部分是内核可以直接访问的。 |
| vmalloc区 | 用来分配物理地址非连续的内存空间 |
| 永久内核映射 | 允许内核建立高端页框到内核虚拟地址空间的长期映射。 |
| 固定映射的线性地址空间 | 其中的一部分用于建立临时内核映射 |
物理内存映射
线性空间中从3G开始大小为896M的区间,为直接内存映射区
映射关系为:物理地址等于虚拟地址减去0xc0000000,即虚拟地址减去3G。
永久内核映射
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。这个空间叫永久内核映射空间
这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,在内核初始化页表管理机制时,专门用pkmap_page_table这个变量保存了PKMAP_BASE对应的页表项的地址,由pkmap_page_table来维护永久内核映射区的页表项的映射,页表项总数为LAST_PKMAP个。通过 kmap(),可以把一个 page 映射到这个空间来。
由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,应该及时通过 kunmap()把一个 page 对应的线性地址从这个空间释放掉(也就是解除映射关系)
这里的永久并不是指调用kmap()建立的映射关系会一直持续下去无法解除,而是指在调用kunmap()解除映射之间这种映射会一直存在,这是相对于临时内核映射机制而言的。
需要注意的是,当永久内核映射区没有空闲的页表项可供映射时,请求映射的进程会被阻塞,因此永久内核映射请求不能发生在中断和可延迟函数中。
临时内核映射
临时内核映射和永久内核映射相比,其最大的特点就是不会阻塞请求映射页框的进程,因此临时内核映射请求可以发生在中断和可延迟函数中
这块空间具有如下特点:
(1)每个 CPU 占用一块空间
(2)在每个CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的 km_type 中。
系统中的每个CPU都有自己的13个临时内核映射窗口,根据不同的需求(用于内核控制路径),选择不同的窗口来创建映射。每个CPU的映射窗口集合用 enum km_type 数据结构表示,该数据结构中的每个符号,如 KM_BOUNCE_READ 、 KM_USER0 或 KM_PTE0 ,标识了窗口的线性地址,其实是一个下标。当要内核建立一个临时映射时,通过 cpu_id 和 窗口下标 来确定线性地址。通过 kmap_atomic() 可实现临时映射。
临时内核映射的实现比永久内核映射要简单,当一个进程申请在某个窗口创建映射,即使这个窗口已经在之前就建立了映射,新的映射也会建立并且覆盖之前的映射,所以说这种映射机制是临时的,并且不会阻塞当前进程。
非连续内存分配
非连续内存分配是指将物理地址不连续的页框映射到线性地址连续的线性地址空间
主要应用于大容量的内存分配。
优点:避免了外部碎片
缺点:必须打乱内核页表,而且访问速度较连续分配的物理页框慢
非连续内存分配的线性地址空间是从 VMALLOC_START 到 VMALLOC_END ,每当内核要用vmalloc类的函数进行非连续内存分配,就会申请一个vm_struct结构来描述对应的vmalloc区,两个vmalloc区之间的间隔至少为一个页框的大小,即PAGE_SIZE。
总结
-
由于内核的线性地址空间有限,因此采取上面介绍的三种方式来映射高端内存。但是每种映射的本质都是通过页表来建立线性地址与物理地址之间的联系。
-
永久内核映射和临时内核映射,都由内核指定了需要进行映射的页面,也就是说指定了页描述符(页描述符和物理页框之间的关系是固定不可变的)。
在永久内核映射中,内核只需要在永久内核映射区找到空闲的,也就是未被映射的线性地址对应的页表项,然后将其分配给page即可,若找不到则将阻塞申请建立映射的进程。
而临时内核映射更直接,连进行映射的线性地址窗口都是固定的,若是其已经分配给了某个页框,则直接抢过来用,因此之前的映射就被覆盖了,体现出了临时性。 -
非连续内存分配,内核不用指定具体的页框,只需指定要申请的内存大小,内核将在非连续内存分配区找到一块相应大小虚拟地址空间,然后再由伙伴系统分配页框,还要通过slab分配器为一些数据结构分配内存,最后再用同样的方式(设置PTE表项)来建立映射。