序
交叉熵损失是分类任务中的常用损失函数,但是是否注意到二分类与多分类情况下的交叉熵形式上的不同呢?
本次记录一下二者的不同。
两种形式
![]()
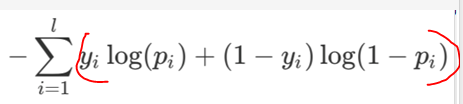
这两个都是交叉熵损失函数,但是看起来长的却有天壤之别。为什么同是交叉熵损失函数,长的却不一样呢?
因为这两个交叉熵损失函数对应不同的最后一层的输出:
第一个对应的最后一层是softmax,第二个对应的最后一层是sigmoid。
信息论中的交叉熵
先来看下信息论中交叉熵的形式

交叉熵是用来描述两个分布的距离的,神经网络训练的目的就是使 g(x) 逼近 p(x)。
softmax层的交叉熵
g(x)是什么呢?就是最后一层的输出 y 。
p(x)是什么呢?就是我们的one-hot标签。我们带入交叉熵的定义中算一下,就会得到第一个式子:
其中 j 代表样本 x 属于第 j 类。
扫描二维码关注公众号,回复:
6496450 查看本文章

sigmoid作为输出的交叉熵
sigmoid作为最后一层输出的话,那就不能吧最后一层的输出看作成一个分布了,因为加起来不为1。
现在应该将最后一层的每个神经元看作一个分布,对应的 target 属于二项分布(target的值代表是这个类的概率),那么第 i 个神经元交叉熵为:

所以最后一层总的交叉熵损失函数是:
转载自:
作者:0过把火0
链接:https://www.jianshu.com/p/5139f1166db7