学习目的:
xpath定位是针对常规定位方法中,最有效的定位方式。
场景:
页面元素的定位。
正式步骤:
step1:常规属性
示例UI

示例UI相关HTML代码

相关代码示例:
#通过id定位 dr.find_element_by_xpath('//*[@id="loginform-username"]').click() #通过tag标签定位 #*号可以匹配任何标签 dr.find_element_by_xpath('//*[@id="loginform-username"]').click() #指定标签名称 dr.find_element_by_xpath('//input[@id="loginform-username"]').click() #通过class定位 dr.find_element_by_xpath('//*[@class="form-control"]').click() #通过name定位 dr.find_element_by_xpath('//*[@name="LoginForm[username]"]').click()
step2: 其他属性
#其他属性,就是本文中非id、name、class之外的一些页面定位的属性 dr.find_element_by_xpath('//*[text()="定位的页面文本"]') #多个属性组合 dr.find_element_by_xpath('//*[@type="text" and @id="loginform-username"]')
step3: 层级关系
a.如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(父元素)
b.找到它老爸后,再找下个层级就能定位到了
HTML代码释义
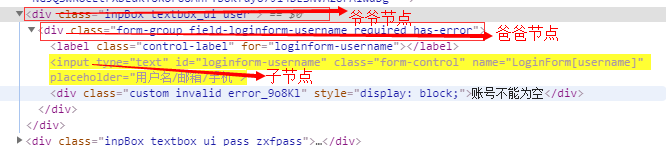
解决方案
#通过爸爸节点定位 dr.find_element_by_xpath('//*[@class="form-group field-loginform-username required has-error"]/input').click() #通过爷爷节点定位 dr.find_element_by_xpath('//*[@id="login-form"]/div[1]/div/input')
step4: 索引定位
Html代码演示
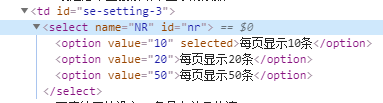
解决方案:
#xpath索引定位,索引初始值从1开始 dr.find_element_by_xpath('//select[@id="nr"]/option[1]').click()
step5: 模糊匹配
1.xpath还有一个非常强大的功能,模糊匹配
2.掌握了模糊匹配功能,基本上没有定位不到的
3.比如我要定位百度页面的超链接“hao123”,在上一篇中讲过可以通过by_link,也可以通过by_partial_link,模糊匹配定位到。当然xpath也可以有同样的功能,并且更为强大。
2.掌握了模糊匹配功能,基本上没有定位不到的
3.比如我要定位百度页面的超链接“hao123”,在上一篇中讲过可以通过by_link,也可以通过by_partial_link,模糊匹配定位到。当然xpath也可以有同样的功能,并且更为强大。
#定位百度首页hao123 dr.find_element_by_xpath('//*[contains(text(),"hao123")]').click() #模糊匹配某个属性,针对百度搜索框 dr.find_element_by_xpath('//*[contains(@id,"kw") and @class = "s_ipt"]').click() #模糊匹配以什么开头 dr.find_element_by_xpath('//*[starts-with(@class,"s_ip")]').click()
难点分析:
没有难点,就是要多用,活学活用。
学习总结:
xpath控制了80%的页面定位解决方案