1 术语
1.1 泛化
学习得到的模型适用于新样本的能力称为泛化能力
1.2 过拟合-关键障碍
学习器能拟合样本所有数据,即把训练样本自身的一些特点当作所有潜在样本的一般性质,导致泛化能力下降的现象。
- 即假设函数中特征变量过多
- 只可缓解,无法消除
- 常见导致因素:学习能力过好
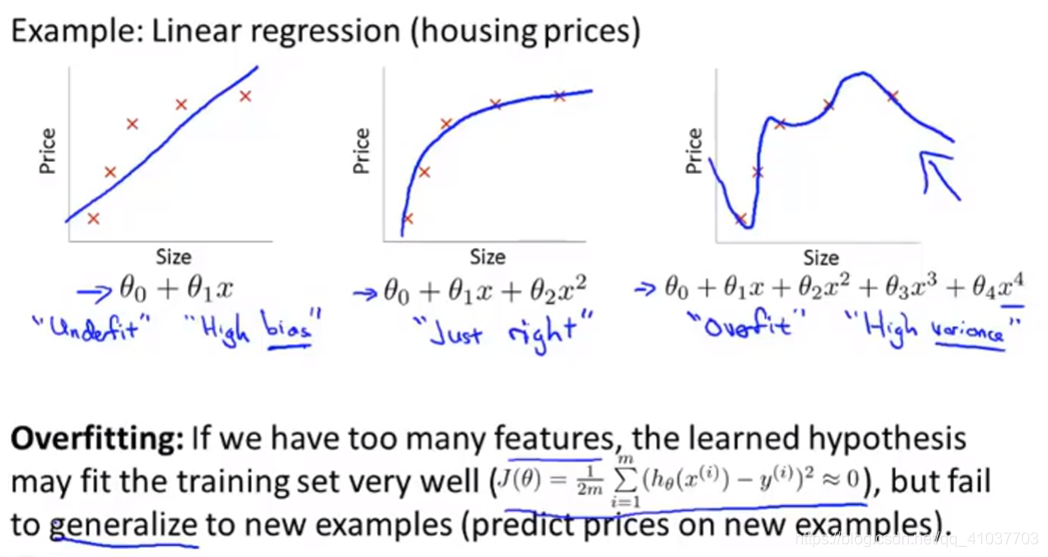
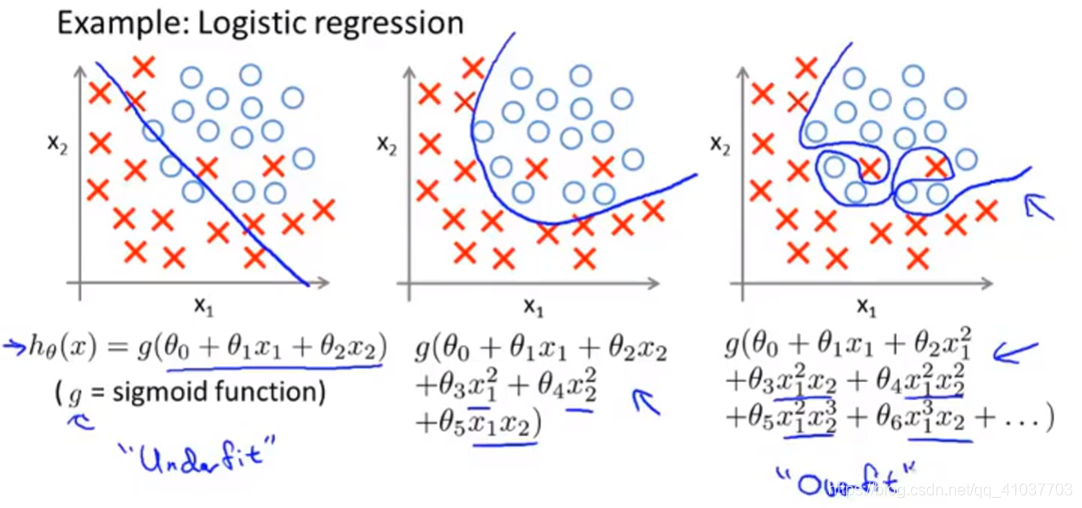
1.2.1 解决方法
- 人为或者利用算法舍去影响程度不高的特征变量
- 正则化:保留所有特征变量但降低参数大小
1.3 错误率
分类错误样本数占样本总数的比率,==设定样本数少的类别作为正类别==
1.3.1 查准率P(Precision)
机器预测的正结果中用户真正需要的结果所占的比例 eg:判断得癌症人中,真正得癌症的人的比率
1.3.2 查全率/召回率R(Recall)
用户真正需要的结果中机器成功预测结果所占的比例 eg:所有得癌症的人中,能判断出得癌症人的比率
- 与P互斥
![[外链图片转存失败(img-oaKzvm5x-1568601688891)(E:\Artificial Intelligence Markdown\Machine Learning\pictures\1.3 查准率与召回率.png)]](https://img-blog.csdnimg.cn/20190916104326649.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxMDM3NzAz,size_16,color_FFFFFF,t_70)
1.3.3 权衡查准率与查全率
通过改变判断阈值,高阈值,P高R低;低阈值P低R高
![[外链图片转存失败(img-aXm2LzGs-1568601688892)(E:\Artificial Intelligence Markdown\Machine Learning\pictures\1.3.3 权衡查准率与召回率.png)]](https://img-blog.csdnimg.cn/20190916104341675.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxMDM3NzAz,size_16,color_FFFFFF,t_70)
1.3.4 BEP
查准率与查全率相等时的值
1.3.5 利用调和平均判断基于查准率与查全率算法的好坏
各统计变量倒数算术平均数的倒数。给较低的值更高的权重
\[ \frac{1}{F1}=\frac{1}{2}(\frac{1}{P}+\frac{1}{R})\tag{1.1} \]
\[ F_1=2\frac{PR}{P+R}\tag{1.2} \]
- 结果恒小于算术平均
- \(F_1\in[0,1]\),越高越好
1.4 卡方分布
标准正态分布的平方
1.5 布尔数据
即逻辑数据类型,取值为0或1