学号 20172326 《程序设计与数据结构》第九周学习总结
教材学习内容总结
- 异常(exception):定义非正常情况下或错误的情况的对象,由程序或运行时环境抛出,可根据需要进行相应的捕获处理。
- 异常与错误的区别:错误代表不可恢复的问题并且必须捕获处理。而异常可以忽视,或者使用try语句处理,或调用更高级的方法。
- 可检测异常与不可检测异常:可检测异常必须由方法捕获,或者必须在可能抛出或传递异常方法的throws子句中列出来。在方法定义的声明头中追加一条throws子句。不可检测异常不需要使用throws子句。
- IO流:分为Sysetm.in,System.out,System.err三种,其中,后两者为输出流。
教材学习中的问题和解决过程
- 问题1:自定义异常如何编写
- 问题1解决方案:
- 以下列代码为例
public class ExceptionDemo3{
public static void main(String []args){
Bar bar=new Bar();
try{
bar.enter(15);
}catch(AgeLessThanEighteenException e){
System.out.println("错误信息:"+e.getMessage());
}
System.out.println("end");
}
}
//自定义异常
class AgeLessThanEighteenException extends Exception{
private String message;//描述异常信息
public AgeLessThanEighteenException(String message){
this.message=message;
}
//重写getMessage()方法
public String getMessage(){
return message;
}
}
class Bar{
public void enter(int age)throws AgeLessThanEighteenException{
if(age<18){
throw new AgeLessThanEighteenException("年龄不合格");
}else{
System.out.println("欢迎光临");
}
}
}- 以此为例。
这里可以看到,自定义异常并不能直接使用try-catch语句,需要另外一个类作为“桥梁”来判定抛出的条件,接着在主函数使用try-catch语句来将自定义的异常抛出。
- 问题2:可检测异常与不可检测异常的理解
问题2解决方案:对于这两个定义,我再理解的时候十分迷惑,为什么可检测的异常需要将在方法头加上throws?
首先如果可检测异常不被throws子句处理或者是被方法捕获,程序将因为而被停止,所以,必须使用相应的方法处理。而不可检测异常则不会编译器检测出来,非检测异常不遵循处理或声明规则。在产生此类异常时,不一定非要采取任何适当操作,编译器不会检查是否已解决了这样一个异常。例如:一个数组为 3 个长度,当你使用下标为3时,就会产生数组下标越界异常。这个异常 JVM 不会进行检测,要靠程序员来判断。有两个主要类定义非检测异常:RuntimeException 和 Error。
Error 子类属于非检测异常,因为无法预知它们的产生时间。若 Java 应用程序内存不足,则随时可能出现 OutOfMemoryError;起因一般不是应用程序的特殊调用,而是 JVM 自身的问题。另外,Error 一般表示应用程序无法解决的严重问题。
RuntimeException 类也属于非检测异常,因为普通 JVM 操作引发的运行时异常随时可能发生,此类异常一般是由特定操作引发。但这些操作在 Java 应用程序中会频繁出现。因此,它们不受编译器检查与处理或声明规则的限制。总结:已检查异常,指的是一个函数的代码逻辑没有错误,但程序运行时会因为IO等错误导致异常,你在编写程序阶段是预料不到的。如果不处理这些异常,程序将来肯定会出错。所以编译器会提示你要去捕获并处理这种可能发生的异常,不处理就不能通过编译。
未检查异常,指的是你的程序逻辑本身有问题,比如数组越界、访问null对象,这种错误你自己是可以避免的。编译器不会强制你检查这种异常。也检查不过来,太多了。
代码调试中的问题和解决过程
- 问题1:程序在什么时候会自动产生异常
- 问题1解决方案:
代码如下:
public class ExceptionDemo1_2{ public static void main(String []args){ //testTryFinally("张三");//输出2 end testTryFinally(null);//空指针异常 } public static void testTryFinally(String name){ try{ System.out.println(name.length()); }finally{ System.out.println("end"); } } }- 分别输出的两个testTryFinally时候结果


可以看到这个程序中并没有出现有关异常的语句,但是依旧抛出了异常。原因在哪?首先这就是刚才的可检测异常,而程序可以发现问题,回顾异常的子类
 可以知道,这种就属于运行异常,所以,程序就可以自动抛出。当然,程序中有finally子句,可以继续执行。
可以知道,这种就属于运行异常,所以,程序就可以自动抛出。当然,程序中有finally子句,可以继续执行。问题2:IO流的一些问题

问题2解决方案:我们知道,
当在程序中创建一个IO流对象的时候,同时系统也会创建
一个叫做流的东西,在这种情况下,计算机内存中实际产生了两个事物,一个是java程
序中类的实例对象,一个是系统本身产生的某种资源,而java垃圾回收器只能管理程序
中类的实例对象,没办法去管理系统产生的资源,所以程序需要调用close方法,去通
知系统释放其自身产生的资源但是,close对于一个程序来说,就好比按下了电脑的电源键,一但按下,别的都会关闭,所以,当时我在第一次写入后执行close语句,相当于将输入流直接关闭,而后续的自然午饭写入。所以,对于一个程序,一个close足矣。
代码托管
上周考试错题总结
错题1

- 理解:异常的处理有三种。第一种忽略异常;第二种处理使用try和catch语句产生的异常;第三种将异常传递到上一级,或者在程序的某一位置集中处理它。
错题2

理解:以这个图为例,
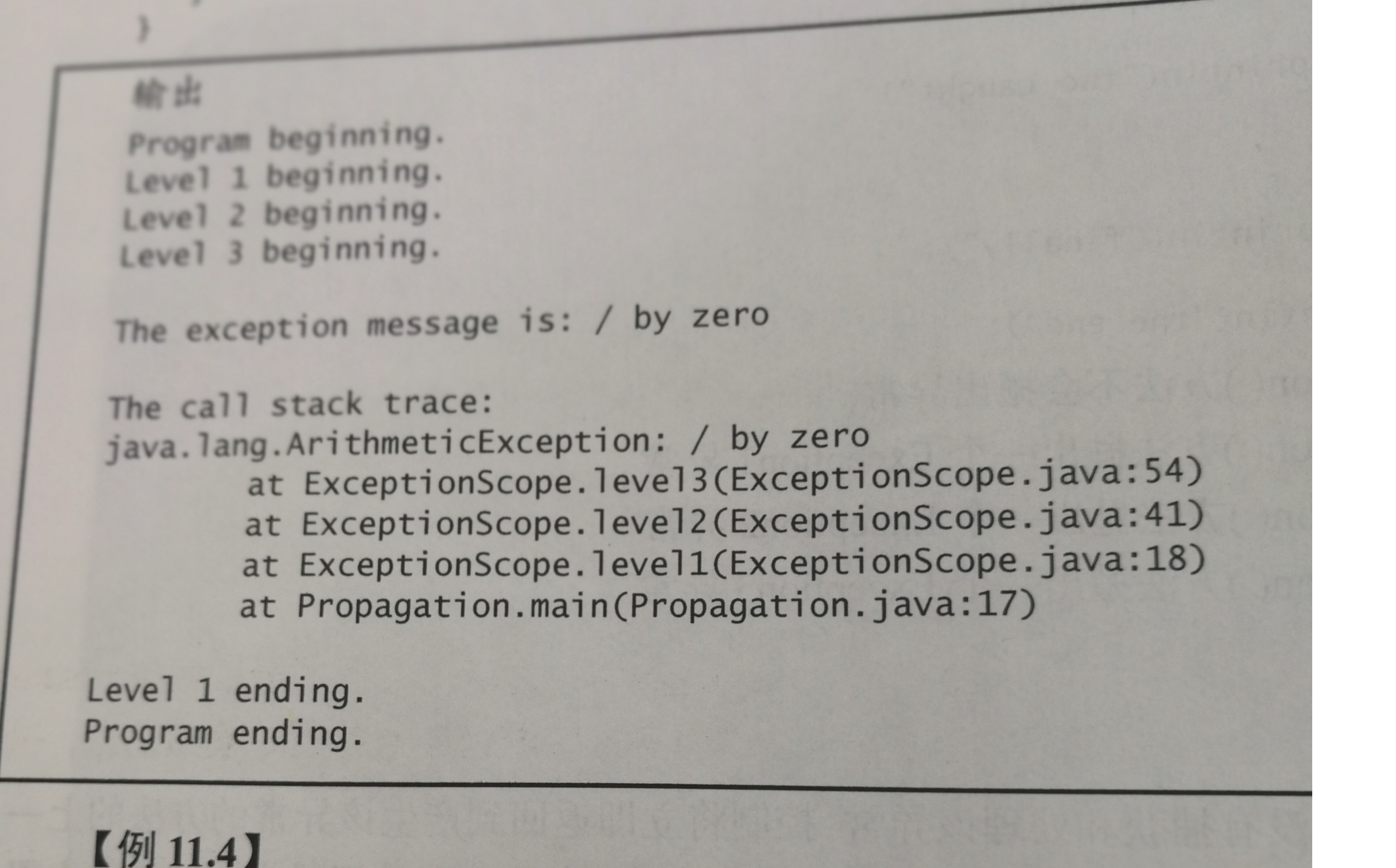
可以看到,它的行号是由高到低的,所以是逆序。
错题3

- 理解,JDK上查到:指示索引或者为负,或者超出字符串的大小。对诸如 charAt 的一些方法,当索引等于字符串的大小时,也会抛出该异常
错题4

- 理解:RuntimeException是非检测异常,所以不需要抛出
错题5

理解:在jdk中可以查到
 也就说,Scanner中拥有自己的解决异常的方法
也就说,Scanner中拥有自己的解决异常的方法错题六

理解:不带缓冲的流的工作原理:它读取到一个字节/字符,就向用户指定的路径写出去 读一个写一个 所以就慢了;带缓冲的流的工作原理:读取到一个字节/字符,先不输出,等凑足了缓冲的最大容量后一次性写出去,从而提高了工作效率。写入效率增高自然提高了运行效率。
其他(感悟、思考等,可选) xxx xxx
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 110/110 | 1/1 | 20/20 | |
| 第二周 | 315/425 | 1/2 | 18/38 | |
| 第三周 | 475/900 | 2/4 | 22/60 | |
| 第四周 | 600/1500 | 1/5 | 30/90 | |
| 第五周 | 1215/2715 | 1/6 | 20/110 | |
| 第六周 | 382/3097 | 1/7 | 20/130 | |
| 第七周 | 721/3818 | 1/8 | 15/145 | |
| 第八周 | 771/4589 | 2/10 | 15/160 | |