| 作业要求地址 | https://www.cnblogs.com/harry240/p/11524113.html |
|---|---|
| Github地址 | https://github.com/1517043456/WordCount.git |
| 结对伙伴博客 | https://www.cnblogs.com/isHao/ |
一、PSP表格
PSP是卡耐基梅隆大学(CMU)的专家们针对软件工程师所提出的一套模型:Personal Software Process (PSP, 个人开发流程,或称个体软件过程)。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| .Estimate | .估计这个任务需要多少时间 | 400 | 600 |
| Development | 开发 | 300 | 350 |
| .Analysis | .需求分析(包括新技术学习) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 300 | 500 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 30 |
| Reporting | · 报告 | 30 | 60 |
| · Test Report | · 测试报告 | 60 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| ·Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1370 | 1640 |
二、结对过程
首先了解完题目后,我们先讨论了如何去完成这个项目,首先要确定完成的功能有哪些,需求分析好了才能撸起袖子加油干。在我们分析过后,决定开始先以实现功能为目的,等到功能实现过后,再考虑代码的可重用性,代码的效率等。然后我们通过讨论,决定使用阿里巴巴开发手册规范,然后讨论会涉及多少类,会用到哪些函数。在制定完代码规范后,各自开始自己最初的编码设计,两人都完成后根据制定的代码规范互审,最后合并代码,形成了初步版本,再接着调试修改,完善代码,进行单元测试,形成最终版本。下面为结对过程的图片记录:

三、解题思路
1、基本功能
此次题目基本功能分为四步。一是统计文件的字符且不考虑汉字,二是统计整个文件的有效行数,三是通过 -m 指令计算有效词组数,四是统计文件的单词总数并且记录器出现次数并输出。我们在改善后后将不同的功能使用不同的方法来实现,下面是我们创建的类及方法:
- PrintFile类:用于输出出现频率高的的10个单词到 output.txt 文件。
- PrintWord类:用于统计输出频率高的单词以及排序等。
- StatisticsFile类:用于统计输入文件中单词的个数以及该文件又几行组成。
StatisticsWord类:用于统计该文件包含多少个单词。
2、程序流程图
我们在讨论过后,总体设计的流程图如下:

四、部分实现代码
1、正则表达式统计
通过正则表达式统计字符总数以及单词的数量。
/**
* 统计字符总数
* */
public static int signFile(string fileName)
{
string argex2 = "[a-zA-Z]{4,}[a-zA-Z0-9]*";
int signNumber = 0;
int sum = 0;
string allText = File.ReadAllText(fileName);
signNumber = Regex.Matches(allText, @"\d").Count;//统计数字
signNumber = signNumber + Regex.Matches(allText, @"\s").Count;//统计空白字符
signNumber = signNumber + Regex.Matches(allText, @"\w").Count;//统计任何单词字符
sum = Regex.Matches(allText, argex2).Count;
Console.WriteLine("字符数为:" + signNumber);
Console.WriteLine("单词数量为:" + sum);
return signNumber;
}2、统计行数
通过SreamReader的ReadLine方法来统计该文件的行数。
/**
* 统计文件行数
**/
public static int lineFile(string fileName)
{
int rows = 0;//文件行数
StreamReader streamReader = new StreamReader(fileName, Encoding.Default);
while (streamReader.ReadLine() != null)
{
rows++;
}
streamReader.Close();
Console.WriteLine("该文件行数为:" + rows);
return rows;
}3、统计词组数
通过以下方法实现词组的统计。
/**
* 统计词组
* */
public static int sumWord(string fileName, int m)
{
int instructionM = m;
int number = 0;
int last = 0;
Dictionary<string, int> keyValuePairs = new Dictionary<string, int>();
StreamReader reader = new StreamReader(fileName, Encoding.Default);
String path = null;
string s = null;
while ((path = reader.ReadLine()) != null)
{
s += (path + "\n");
}
string[] words = Regex.Split(s, @"\W+");
foreach (string word in words)
{
if (keyValuePairs.ContainsKey(word))
{
keyValuePairs[word]++;
number++;
}
else
{
keyValuePairs[word] = 1;
number++;
}
}
if (number > instructionM)
{
last = number - instructionM;
Console.WriteLine("词组个数为:" + last);
}
else
{
Console.WriteLine("不存在这样的词组");
}
return last;
}4、排序
对单词的出现频率进行排序,并在频率相同时给出字典排序。
foreach (KeyValuePair<string, int> entry in keyValuePairs)//统计单词总量
{
wordKey[i] = entry.Key;
wordValue[i] = entry.Value;
i++;
}
for (int j = 0; j < i; j++)//排序
{
for (int x = j + 1; x < i; x++)
{
if (wordValue[j] < wordValue[x])
{
int value = 0;
value = wordValue[j];
wordValue[j] = wordValue[x];
wordValue[x] = value;
string key = null;
key = wordKey[j];
wordKey[j] = wordKey[x];
wordKey[x] = key;
}
}
}
string[] result = new string[instructionN];
for (int j = 0; j < instructionN; j++)
{
result[j] = wordKey[j] + ":" + wordValue[j];
// Console.WriteLine( ss1[j] );
}
var queryResults = from ni in result//字典序排序并输出
orderby ni
select ni;
foreach (var item in queryResults)
{
//Console.WriteLine(item);
File.AppendAllText(o, item + "\r\n");
}五、代码互审过程
由于一些功能没有实现,所以我们互审主要基于代码的格式和已实现功能的纠错。
1. 命名变量、函数时不要随意取名,最好有相关意思,采用阿里巴巴规范命名法。避免过多地描 述和可要可不要的修饰词。
2. 尽量使代码简明易读,无二义性。
3. 在复杂的表达式中,用括号清楚地表示逻辑优先级。
4. 断行,每个“{” “}”独占一行,一一对应。
5. 给出关键的注释。
代码规范
我们在互审过程中,发现了我们代码不规范带来的烦恼。所以我们决定规定好代码规范。可以给我们带来以下好处。
- 规范的代码可以促进团队合作
- 规范的代码可以减少bug处理
- 规范的代码可以降低维护成本
- 规范的代码有助于代码审查
- 养成代码规范的习惯,有助于程序员自身的成长
代码规范链接:https://www.jianshu.com/p/d7e87107073c
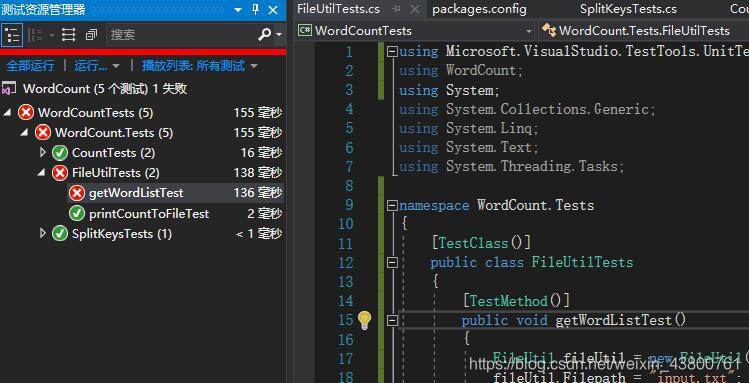
六、建立单元测试
初步单元测试结果如下:
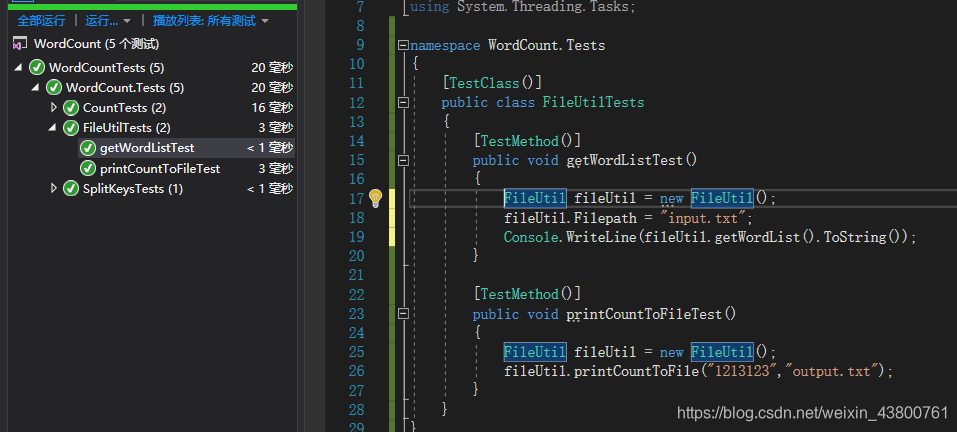
改进后单元测试结果如下:
七、效能测试及性能改进
本次性能分析,主要是从算法入手和设计入手。首先在初步完成项目后,我们就进行了一次项目性能分析,来查看哪里的优化效率和算法。
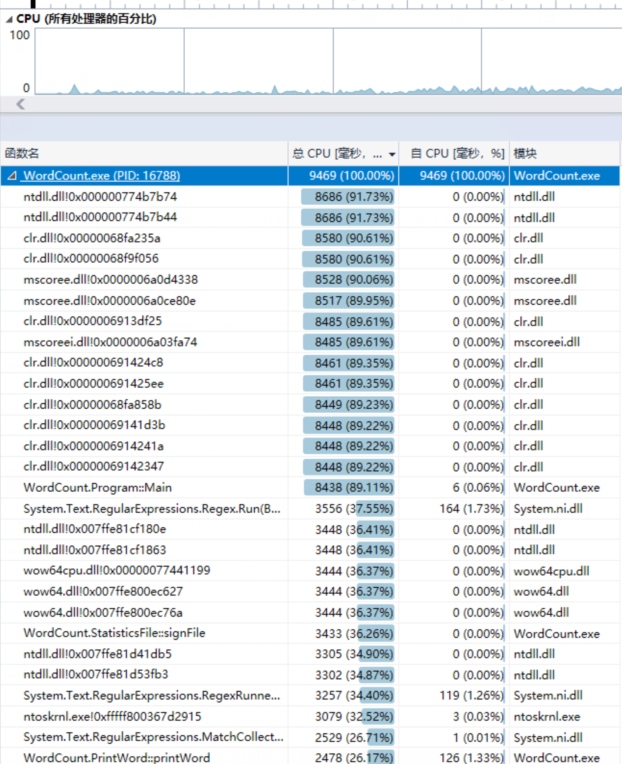
可见,当我们为了完成功能,将所有代码写到一起时,有的代码重复率十分高,消耗也大,耦合度也大。因此我们进行了相应的优化和改进。
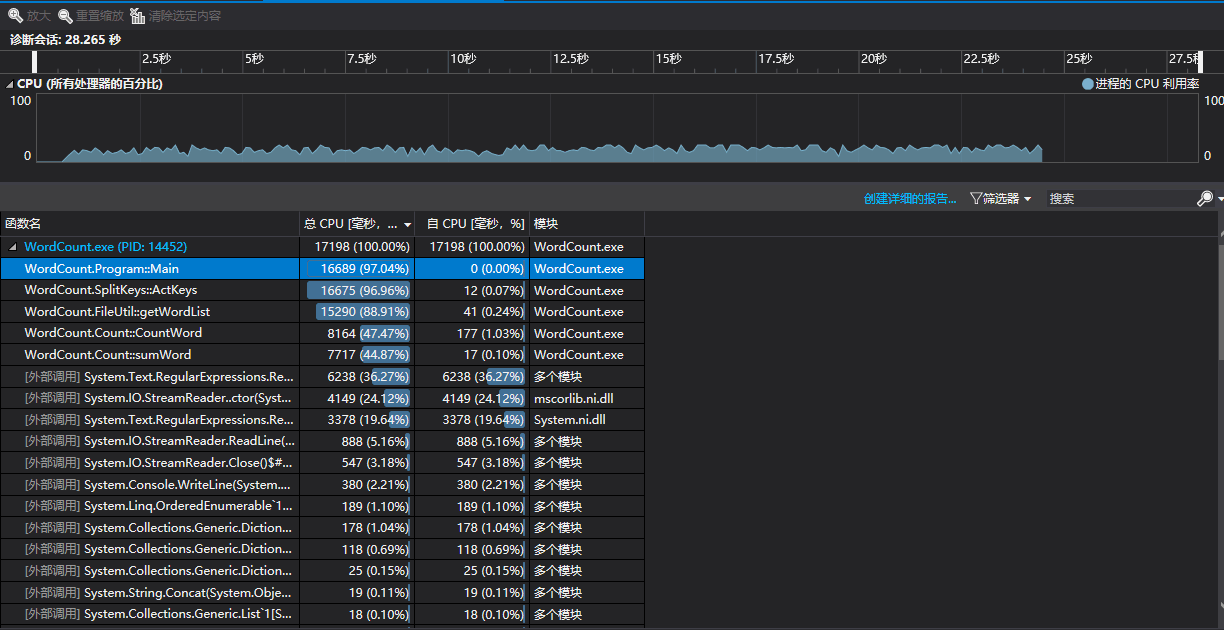
当我们将代码进行整理后,代码的重复率下降,耦合性降低,同时也通过注入对象的方式减少了类实例化的开销。
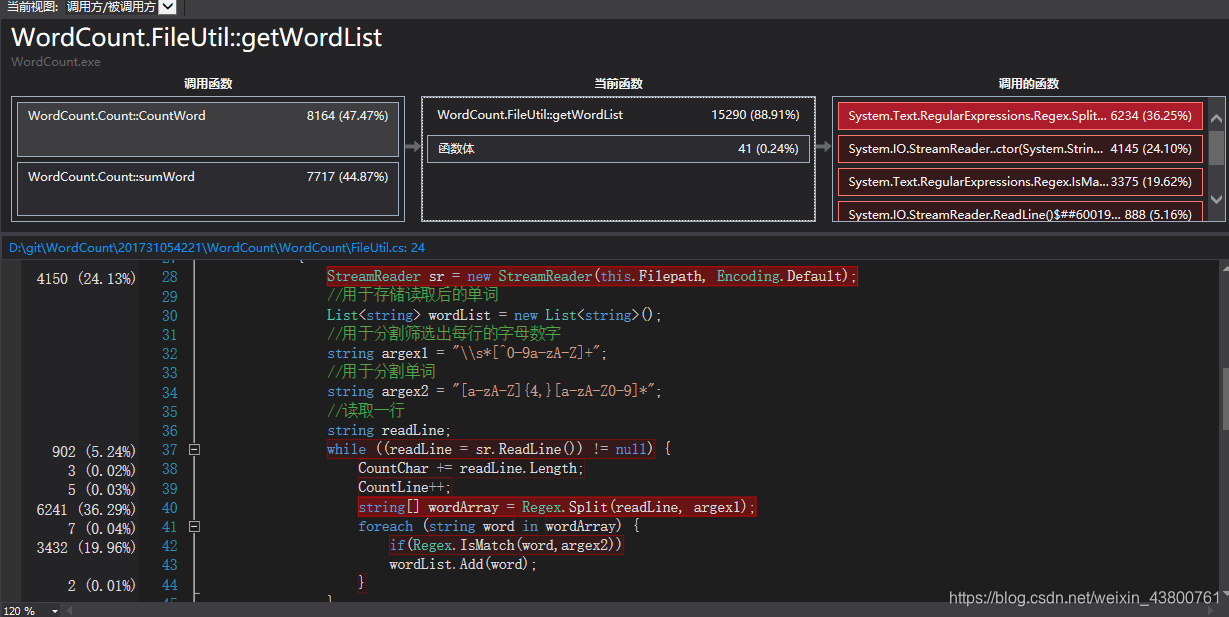
改进后单个类效能测试如下:
总结
本次结对编程的项目我个人感觉还是比较难的,很多东西还是一如既往的不懂,然后一如既往的查资料,虽然做了很多天,仍然有些功能没能实现。在和队友商量后也没有解决,只把自己能做的写了出来。在编程过程中,通过代码互审,互相找到了对方代码的不足,并改正。很多之前不知道的东西在此次作业中出现,由于并不了解,所以做的很粗糙。在此次作业中深刻地认识到了自己的差距,会在之后的学习中更加努力,争取以后的作业不会出现此次情况。
此次结对1+1<2,由于自身的原因,且并没有真正领略到结对编程的含义,导致大多数代码是两个人各自完成,最后再来对照纠错,以及并不熟悉别人的想法导致效率的低下,结对编程比较要求两个人的水平相近。