论文
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
简述:
由于训练过程中各层输入的分布随前一层参数的变化而变化,会导致训练速度的下降(低学习率和注意参数初始化)且很难去训练模型。为此作者提出Batch Normalization,解决在训练过程中,中间层数据分布发生改变的情况。将规范化(normalization)作为模型体系结构的一部分,对每个训练小批执行规范化,即在网络的每一层输入的时候,先做一个归一化处理,再进入网络的下一层。该方法与当时最高水平的model相比,达到相同精度的效果减少了14倍的速度,提高了训练的速度和精度。
背景or动机:
神经网络学习过程本质是为了学习数据分布,一旦训练数据与测试数据的分布不同,则网络的泛化能力也大大降低;其次,一旦每批训练数据的分布各不相同(batch梯度下降),那么网络就要在每次迭代都去学习适应不同的分布(新的数据分布),这样将会大大降低网络的训练速度。
神经网络训练,参数就会发生变化,除了输入层,后面网络每一层的输入数据分布是一直在发生变化的,因为在训练的时候,前面层训练参数的更新将导致后面层输入数据分布的变化。作者将这种数据分布的改变称之为:“Internal Covariate Shift”。
问题or相关工作:
尽管随机梯度下降法(SGD)对于训练深度网络是简单且有效的,但需要人为的设定(浪费时间调参)一些如学习率、权重衰减系数,参数初始化、Dropout比例等,且每个层的输入都受到前面所有层的参数的影响,导致层需要不断地适应新的分布,即深度网络内部节点在训练过程中的分布变化(Internal Covariate Shift),如果训练过程中,训练数据的分布一直在发生变化,这将减慢训练速度,且网络越深越明显。
作者提出Batch Normalization,具体提出的方案及解决的问题如下:
- 通过一个标准化步骤(后续介绍),固定了层输入的平均值和方差。
- 允许使用更大的学习率。通过减少梯度对参数或其初始值的依赖关系,对网络中的梯度流产生有益的影响。
- 提高了网络泛化能力的特性,减少了Dropout的需要,减少L2权重的正则化。
- 不需要使用局部响应归一化层(Alexnet网络中的LRN),因为BN本身就是一个归一化网络层.
- 可以把训练数据彻底打乱(防止每批训练的时候,某一个样本都经常被挑选到,文献说这个可以提高1%的精度)
算法描述:
补充:数据预处理:最好的是白化算法,经过白化处理后,数据满足:1.特征之间的相关性降低,这个就相当于PCA(主成分分析);2.数据均值、标准差归一化,使得每一维特征均值为0,标准差为1。而要实现白化的第1个要求,需要计算特征向量,计算量非常大。但白化算法运算量过大,且不是处处可微的。
作者为了简化计算,不对层输入和层输出的特征进行联合白化(即忽略第1个要求),仅独立的使每个标量特征进行标准化,即均值为0,方差为1.即使不去相关,同样加快了收敛速度。公式如下:(E(x)k指每一批训练数据神经元xk的平均值,分母为每一批数据神经元xk激活度的一个标准差)
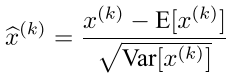
如果仅对层的每个输入进行标准化可能会改变层所能表示的内容。例如作者举的例子:对一个sigmoid的输入进行归一化会将其约束为非线性的线性形式。(即学习后的特征数据分布在S激活函数的两侧,归一化处理后,数据变换成分布于S函数的中间部分,把学习到的特征分布损坏了),所以要确保为恒等变换。
作者运用变换重构,引入了可学习参数γ、β,如下式:
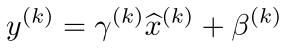
其中当:
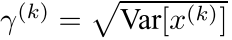 ,
, 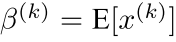
是可以恢复原来的某一层所学到的特征。Batch Normalization网络层的前向传导过程公式如下图:

即BN层的计算流程: 1.计算样本均值。2.计算样本方差。3.样本数据标准化处理。4.进行平移和缩放处理。引入了γ和β两个参数。
通过下面的变换来反向传播损耗梯度,并计算出与BN变换参数相关(γ和β)的梯度。使用链式法则,如下(在简化之前):
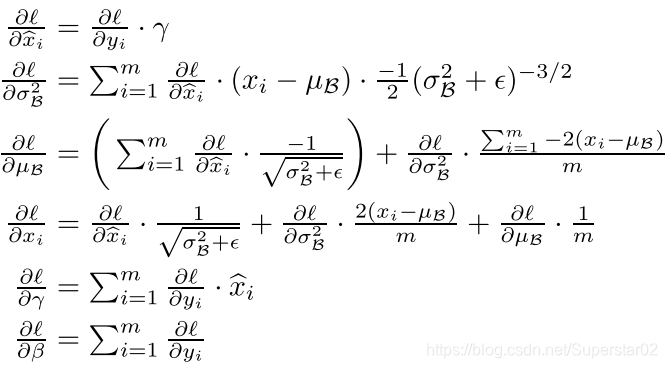
整个训练过程:

1.K个激活函数前的输入要K个循环。计算均值与方差。通过γ,β与输入x的变换求出BN层输出。
2.在反向传播时利用γ与β求得梯度从而改变训练权值(变量)。
3.通过不断迭代直到训练结束,得到γ与β,以及记录的均值方差。
4.在预测的正向传播时,使用训练时最后得到的γ与β,以及均值与方差的无偏估计(均值为直接计算所有batch u值的平均值;标准偏差采用每个batch σB的无偏估计),通过图中11:所表示的公式计算BN层输出。
Batch Normalization can be applied to any set of activations in the network.将BN变换加在非线性之前(add the BN transform immediately before the nonlinearity)。即前向传导公式:z = g(BN(Wu + b)),因b在均值减法中被抵消,且偏执归入γ,故不需要b,变成:。z = g(BN(Wu ))。
实验&结果:

(a)图,训练的MNIST网络的测试精度与训练步骤的数量的关系,可以看出加入BN层提高了网络的速度和精度。(b)(c)图展示了每个网络最后一个隐藏层的典型激活,可以看出BN层网络分布更稳定,有利于训练。
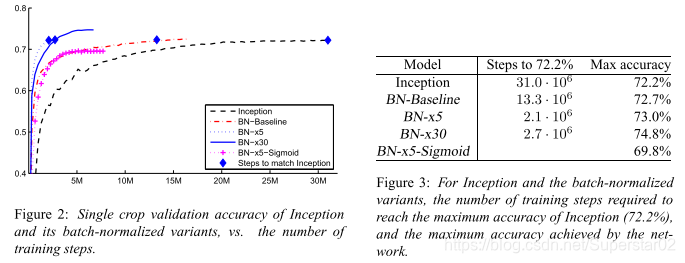
上图展示了原始与加入BN层、且增加学习率为原来的倍数等之间的关系,可以看出随着学习率的提高,加入BN层精度逐步提高。
总结:
本文提出的BN层显著加快了深度网络的速度,同时提高了网络的精度,在现有的网络框架上广泛使用。
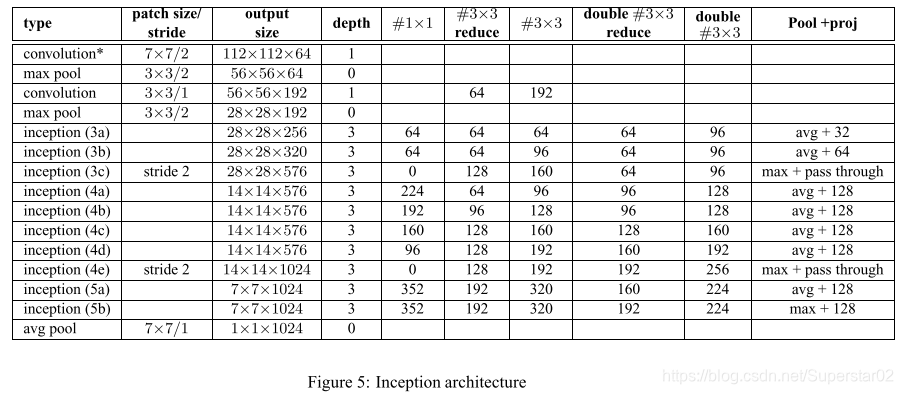
注:在文章最后作者附录了对Inception-v1的改进,用两个3×3代替一个5×5,感受野相同,参数变少了。还增加了一些其他的层及相关的平均池化/最大池化。具体结构如下: