Support Vector Machines -------------------
Step 1: Exploring and preparing the data ----
read in data and examine structure
将输入读入到R中,确认接收到的数据具有16个特征,这些特征定义了每一个字母的案例。
letters <- read.csv("F:\\rwork\\Machine Learning with R (2nd Ed.)\\Chapter 07\\letterdata.csv")
str(letters)

支持向量机学习算法要求所有特征都是数值型的,并且每一个特征需要压缩到一个相当小的区间中。
divide into training and test data
一部分作为训练数据,一部分作为测试数据
letters_train <- letters[1:16000, ]
letters_test <- letters[16001:20000, ]
Step 2: Training a model on the data ----训练模型
begin by training a simple linear SVM
#install.packages(‘kernel’)
为了提供度量度量支持向量机性能的基准,我们从训练一个简单的线性支持向量机分类器开始。
library(kernlab)
letter_classifier <- ksvm(letter ~ ., data = letters_train,
kernel = "vanilladot")
ksvm函数默认使用高斯RBF核函数
vanilladot表示线性函数
look at basic information about the model
letter_classifier

这里没有提供任何信息告诉我们模型在真实世界中运行的好坏,所以想下面我们用测试数据来研究模型的性能。
Step 3: Evaluating model performance ----评估模型性能
predictions on testing dataset
letter_predictions <- predict(letter_classifier, letters_test)
head(letter_predictions)
这里我们用table函数对预测值和真实值之间进行比较
table(letter_predictions, letters_test$letter)
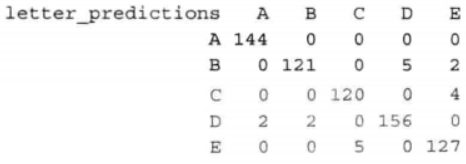
对角线的值144、121.120.156和127表示的是预测值与真实值相匹配的总记录数。同样,出错的数目也列出来了。例如,位于行B和列D的值5表示有5种情况将字母D误认为字母B。
单个地看每个错误类型,可能会揭示一些有趣的关于模型识别有困难的特定字母类型的模式,但这也是很耗费时间的。因此,我们可以通过计算整体的准确度来简化我们的评估,即只考虑预测的字母是正确的还是不正确的,并忽略错误的类型。
look only at agreement vs. non-agreement
construct a vector of TRUE/FALSE indicating correct/incorrect predictions
下面的命令返回一个元素为TRUE或者FALSE值的向量,表示在测试数据集中,模型预测的字母是否与真实的字母相符(即匹配)。
agreement <- letter_predictions == letters_test$letter
使用table()函数,我们看到,在4000个测试记录中,分类器正确识别的字母有3357个:
table(agreement)

以百分比计算,准确度大约为84%
prop.table(table(agreement))

Step 4: Improving model performance ----提高模型性能
之前的支持向量机模型使用简单的线性核函数。通过使用一-个更复杂的核函数,我们可以将数据映射到一个更高维的空间,并有可能获得-一个较好的模型拟合度。
然而,从许多不同的核函数进行选择是具有挑战性的。一个流行的惯例就是从高斯RBF核函数开始,因为它已经被证明对于许多类型的数据都能运行得很好。我们可以使用ksvm()函数来训练-一个基于RBF的支持向量机,如下所示:
set.seed(12345)
letter_classifier_rbf <- ksvm(letter ~ ., data = letters_train, kernel = "rbfdot")
letter_predictions_rbf <- predict(letter_classifier_rbf, letters_test)
最后,与我们的线性支持向量机的准确度进行比较:
agreement_rbf <- letter_predictions_rbf == letters_test$letter
table(agreement_rbf)

prop.table(table(agreement_rbf))
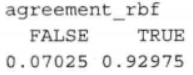
通过简单地改变核函数,我们可以将字符识别模型的准确度从84%提高到93%。如果这种性能水平对于光学字符识别程序仍不能令人满意,那么你可以测试其他的核函数或者通过改变成本约束参数C来修正决策边界的宽度。
欢迎指正哦~(原理百度一下很多,所以就不添加了)
需要数据请私信哦~
