手机App用户输入隐私数据的识别与检测技术研究
1.引言
随着移动设备的普及,智能手机和手机应用已经成为日常生活中必不可少的一部分,与此同时,移动设备中的隐私问题也就变得日益重要。先前手机隐私相关的研究工作主要集中在手机操作系统预定义的已知来源上,例如位置信息、通话记录、短信等,这些内容都是通过预定义的系统API获取的。那些通过UI界面由用户自己输入的隐私信息,则被绝大多数工作所忽略了,但实际上大量的敏感信息都是在程序运行时由用户自己输入的。
Nan等人设计的UIPicker[[1]]和Huang等人设计的SUPOR[[2]]都对用户输入隐私的保护进行了相关研究工作。UIPicker设计旨在检测应用程序框架及代码中的语义信息,并进一步分析安全关键信息可能出现的位置,这种方法能支持现有的各种移动应用安全分析。UIPicker还开发了运行时防护的机制,帮助用户在敏感数据以非预期的形式发送出去时得到通知并决定作何处理。SUPOR系统是一个新颖的静态分析工具,用于自动检测程序界面是否包含敏感的用户输入,譬如用户登录凭证、财务信息、医疗信息等。SUPOR检测的UI组件主要是文本框,UIPicker则不局限于此,能够检测更多的UI组件。两个系统都采用了NLP的技术对UI呈现和架构资源进行了分析,来识别用户输入隐私,UIPicker更进一步采用了机器学习的技术训练分类器,使检测结果更为准确。
2.介绍
据艾媒咨询发布的《2015-2016年中国智能手机市场研究报告》显示[[3]],截至2015年6月底,中国网民规模已经达到6.68亿,其中手机网民规模为5.9357亿,在整体网民中占比88.9%,整体呈逐年上涨趋势,增长率呈下降趋势,而在中国智能手机市场系统覆盖方面,安卓以73.1%的占比位列第一。可以看出,智能手机,尤其是安卓手机,已经在终端用户设备中占据了统治地位。随着各类App数量的增加,智能手机也更能满足用户的各类需要,但与此同时,这些App也获取了越来越多的用户隐私和敏感信息,保护这些用户隐私就成为了一项重要的工作。
先前对智能手机上用户隐私的研究主要集中在那些操作系统预定义的敏感API上[6][7][8][9],如设备标识符(电话号码,IMEI等)、位置信息、通讯录、日历、浏览器信息等,主要采取了权限保护的手段。这些的确是非常重要的用户隐私,但是并没有覆盖所有的用户隐私和敏感数据。这些研究在很大程度上忽视了一个非常重要的用户隐私来源——用户输入隐私。App通常通过用户界面UI让用户输入一些信息,而这些信息就包括了登录凭证、财务信息、医疗信息等敏感数据。因此要在智能手机上保护用户隐私,就必须很好的处理这些用户输入隐私。
如何识别敏感用户输入。有些敏感数据是操作系统给出的,例如位置信息,保护此类称之为系统为中心的隐私数据,可以利用系统API来设置安全标签,对其进行保护。但本文所研究的是用户输入的隐私数据,这就要求在应用程序中理解输入信息的语义,而这是现有技术无法实现的。多篇文献[4][5]记录了当前攻击者通过攻击现有保护机制的薄弱环节来窃取用户隐私。例如,伪装成银行应用的UI来骗取用户的财务信息。除此之外,开发者安全意识缺失也在无意中泄露了用户隐私,例如在公网中明文传输数据。用户隐私泄露的途径十分多,我们发现在谷歌商店排名靠前的17425个应用中,有35.46%涉及敏感的用户输入。
鉴于用户输入隐私的重要性,相应的保护就十分关键。但不同于系统管理的元素可以通过几个API来轻松识别,用户输入隐私只有通过上下文分析和UI语义分析来获得。一种方法是将所有用户输入都标记为敏感,这显然很不合理。先前采用的方法大多是依赖于用户、开发人员或分析师手动标记需要保护的内容,这需要大量的人工干预,而工作跟不上就会导致安全风险存在。这种方式是非常低效的,成本也很高,因此需要一个自动化标记的系统来识别用户输入隐私。
3.问题陈述
图1展示了一个用户输入身份凭证进行登录的程序界面,在这个界面中,用户通过输入用户ID和登录密码,调用身份验证的远程服务。在这个程序中,开发者可能没有意识到泄露用户隐私的潜在风险,将用户身份凭证在一个不安全的通道(HTTP)中传输,这就在无意中损害了用户隐私。
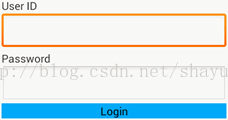
图1 用户输入隐私示例1
登录界面只是一个很简单的例子,在图2中,用户需要输入家庭住址、信用卡号等更为隐私的数据,并且不仅使用了文本输入组件,使用了更多的UI元素。这就使用户输入隐私的检测更为困难。
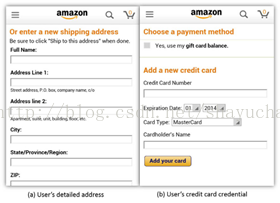
图2 用户输入隐私示例2
挑战。识别用户输入隐私主要有以下挑战:
(1)如何系统地从一个应用程序的用户界面中发现输入字段?
(2)如何确定哪些输入字段是敏感的? 人眼可以很轻易的识别用户输入隐私,但对机器来说大规模识别是很难的。由于用户输入隐私是高度非结构化的数据,因此无法在用户输入过程中用正则表达式来识别。用传统的静态检测技术同样也是不切实际的,因为在代码语义中,隐私输入和其他普通输入并没有显著的区别。
(3)如何将应用程序中敏感的输入字段与存储它们值的对应变量联系起来?
两篇论文的主要工作:
SUPOR系统在设计过程中针对三个挑战分别进行了分析。
第一,如何在程序界面中系统的发现输入字段。研究发现,安卓应用采用可扩展标记语言XML对程序界面进行结构化的描述,因此可以通过静态分析来从应用中发现输入字段。
第二,在需要用户输入数据时,界面上会有一些诸如标签之类的文字来引导用户进行输入,而这些文字就可以帮助判断用户输入是否为隐私信息。例如图1中的“UserID”就描述了第一个文本框要输入的是用户ID。移动设备的特点决定了这些标签通常都很简短,因此采用现在的自然语言处理技术可以很准确的判断出这个输入字段是否是敏感的。
第三,根据安卓的机制,系统会提供API来加载UI框架,并将其与程序代码绑定起来。这样的机制可以帮助我们找到敏感用户输入字段和程序代码中相应变量的关系。
Huang等人主要完成了三项工作。
第一,设计了一个UI敏感的分析方法来判断一个输入字段是否包含敏感信息,这个方法应用了UI呈现、几何布局分析和自然语言处理技术。进一步利用NLP技术从大量App中提取了隐私相关的关键词,并使用这些关键词来分类并识别敏感的用户输入字段。最后对识别准确率进行了实验,结果显示精度达到了97.3%。
第二,设计了一个上下文敏感的方法对敏感的UI输入字段和程序代码中对应的变量进行关联,以此进一步减少了误判。只有在窗口部件和布局标识都和XML布局中的敏感输入字段匹配的时候,我们才认为这个窗口部件和敏感的输入字段是相关联的。
最后,实现了基于SUPOR和静态污点分析的隐私泄漏检测系统,并将系统应用在从谷歌市场收集的16000个流行App上。系统运行在一个8个服务器的集群上,平均每分钟能处理11.1个App。在所有这些应用中,有355个被检测到存在用户隐私泄漏。经过人工验证,发现这些可疑程序的检测精度为91.3%。
UIPciker:Nan等人设计UIPicker可以自动、大规模的在安卓应用中进行用户隐私识别。大多数隐私相关的UI元素都在布局资源文件中很好的描述了,或者在UI屏幕上用相关关键词进行了注释,因此可以通过对这些描述的识别和分类,来进行用户输入隐私的识别。研究结合了自然语言处理,机器学习和程序分析技术。具体来说,UIPicker首先收集隐私相关内容并根据一组关键词和自动标记的数据来训练语料库,然后训练一个分类器用于从布局资源中识别用户敏感输入。最后通过静态分析来过滤掉与隐私无关的内容。基于UIPicker,还研发了一套动态检测机制,在用户隐私离开设备时发出提醒。帮助用户决定是否停止传输。UIPicker不仅能工作在安卓平台,也可以工作于别的移动平台。
UIPicker研究的贡献。(1)通过17425个应用研究了用户输入隐私的分布规律。结果显示在某些应用类别中超过半数的应用都涉及用户输入隐私。因此保护这些隐私显得十分迫切。(2)推出了UIPicker。(3)基于UIPicker研发了动态分析的保护机制。(4)进行了一系列的评估来显示UIPicker的有效性和准确率。
4.系统设计
(1)SUPOR
SUPOR包括三个主要组件:布局分析、UI敏感性分析和变量绑定,如图3所示。布局分析组件接收一个App的APK文件,并呈现包含输入字段的布局文件。基于这一部分的UI呈现,UI敏感性分析组件将输入字段和文本标签联系起来,并通过预定义的关键词数据集来判断输入字段的敏感性。最后,变量绑定组件从程序代码中找出存储敏感输入字段的变量。
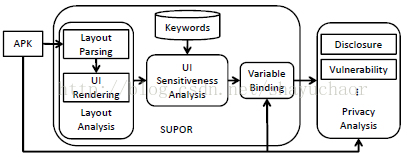
图3 SUPOR总体架构
布局分析组件:布局分析组件的目的是呈现一个安卓应用的用户界面,并从中提取输入字段的信息:类型、提示和绝对坐标,然后将这些信息用于UI敏感性分析。
当类型和提示无法判断这个输入字段是否敏感时,需要找到一个用于描述这个输入字段的标签。从用户的角度看来,在输入字段前面通常有一个文本标签描述此处要输入什么信息,而这个标签就能帮助判断这个字段是否敏感。因此本文提出了一种算法来找出输入字段对应的描述标签。
第一步是通过解析一个应用的APK文件的布局文件来识别哪个文件包含输入字段。这一步工作中,着重关注EditText类型及其子类型,包括自定义部件。每个输入字段代表一个潜在的敏感源。此时还无法判断输入字段是否敏感,因此把所有的输入字段都交付给UI敏感性分析组件来做处理。
第二步是获得输入字段的坐标信息,然后在算法中使用坐标求标签和输入字段的欧式距离,找到与输入字段最近最相关的文本标签。
UI敏感分析组件:基于从布局分析组件收集的信息,UI敏感性分析组件确定一个给出的输入字段是否包含敏感信息。该组件包含三个主要步骤。
首先,如果输入字段的某些属性被指定成类似android:inputType =“textPassword”,那么它直接被视为敏感。
第二,如果输入字段包含任何提示,如“在这里输入密码”,如果提示中包含任何在敏感关键词数据集中的关键词,那么输入字段被认为是敏感的,否则,进入第三步。
第三,SUPOR识别输入字段的描述标签,并分析标签文本是否敏感。
变量绑定:随着敏感输入字段在前面的步骤中的确定,变量绑定组件执行上下文敏感分析来绑定输入字段和代码中相应的的变量。敏感的输入字段使用上下文ID标识,包括布局ID和控件ID,这些上下文ID可用于直接从XML布局文件中定位输入字段。SUPOR利用安卓提供的绑定机制使输入字段与适当的变量联系起来。
(2)UIPicker
总体架构由4部分组成,如图4所示,分为两个阶段:模型训练和识别。1,2,3属于训练阶段,用一些APP来训练分类器,1,3,4为识别阶段,同时使用训练好的分类器和程序表现来识别用户输入隐私数据元素。
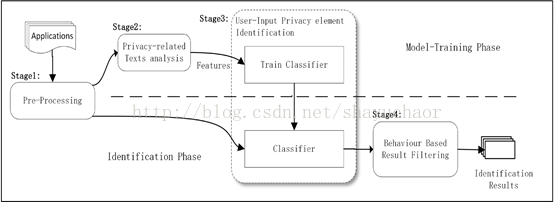
图4 UIPicker总体架构
在预处理模块中,收录布局资源文本并用自然语言处理进行整理以备进一步使用。这一步包括分词、移除冗余内容和词干提取。预处理可以减少程序员不同编程习惯造成的布局资源格式不同。
隐私相关文本分析。为了从布局资源中识别用户输入隐私,第一个挑战是如何获取隐私相关文本。为了整理语义相关单词借用了WordNet字典,但是仍然有很多语义上的内容无法解决。另外,用户输入隐私数据通常都是用单个词汇或很短的短语描述的,NLP中的一些技术很难派上用场。
UIPicker使用了一些基于个体特征抽取的隐私相关种子来对用户输入隐私语义进行扩展。首先通过启发式规则自动标记一组可能包含用户输入隐私数据的布局子集,然后通过聚类算法来从这些布局中提取隐私相关的语义。
UIP数据元素识别。根据上面步骤得到的一组隐私相关文本语义,一个元素包含多少隐私相关的文本应该被定义为敏感?根据之前的工作显示,基于关键词的搜索错误率很高,例如用户地址address还有别的意思,而别的意思可能就完全不是敏感数据了。在这一步中,UIPicker使用一个有监督的机器学习的方法来训练一个基于一组前一阶段产生的语义特征的分类器。除此之外,它完全通过元素在整个布局中的上下文来判断其是否隐私相关。有了这个模型,UIPicker可以判断任何一个有描述的布局元素是否和隐私有关。
基于行为的结果筛选。除了判断是否与隐私相关,还要检查一个元素是否接受用户输入。也就是说,要区别用户输入和其他静态元素。
5.相关工作
文献[1]在相关工作中指出与其最为接近的工作是文献[2],同样关注的是用户输入隐私数据的识别,UIPicker首先收集隐私相关内容并根据一组关键词和自动标记的数据来训练语料库,然后训练一个分类器用于从布局资源中识别用户敏感输入。最后通过静态分析来过滤掉与隐私无关的内容。文献[1]认为,在描述文本的选择上,SUPOR采用的算法选取的标签更接近用户在用户界面看到的样子,不像UIPicker一样容易加入很多不相关元素。但UIPicker在NLP技术上更为优秀,可以借鉴使用。
UIPicker这篇论文的相关工作中提到,与其最为接近的工作就是SUPOR,同样适用了UI呈现,几何布局分析和NLP技术进行自动识别用户输入隐私。SUPOR主要关注了几种特定的UI元素,而UIPicker不局限于此。另外还有安卓应用中的文本分析的相关工作,还有静态分析的相关工作。
参考文献
[1] Huang J, Li Z, XiaoX, et al. Supor: Precise and scalable sensitive user input detection forandroid apps[C]. 24th USENIX Security Symposium (USENIX Security 15). 2015:977-992.
[[2]] NanY, Yang M, Yang Z, et al. Uipicker: User-input privacy identification in mobileapplications[C]. 24th USENIX Security Symposium (USENIX Security 15). 2015:993-1008.
[[3]] 艾媒网:2015-2016年中国智能手机市场研究报告[EB/OL]. [2016-10-15]. http://www.iimedia.cn/41787.html.
[4]Chen Q A, Qian Z, Mao Z M. Peeking into your app without actually seeing it: UIstate inference and novel android attacks[C]. 23rd USENIX Security Symposium(USENIX Security 14). 2014: 1037-1052.
[5] Jiang Y Z X. Detecting passive content leaks andpollution in android applications[C].Proceedings of the 20th Network andDistributed System Security Symposium (NDSS). 2013.
[6] Enck W, Gilbert P, Han S, et al. TaintDroid: aninformation-flow tracking system for realtime privacy monitoring onsmartphones[J]. ACM Transactions on Computer Systems (TOCS), 2014, 32(2): 5.
[7] Enck W, Octeau D, McDaniel P, et al. A Study of AndroidApplication Security[C]. USENIX security symposium. 2011, 2: 2.
[8]Gibler C, Crussell J, Erickson J, et al. AndroidLeaks: automatically detectingpotential privacy leaks in android applications on a large scale[C]. InternationalConference on Trust and Trustworthy Computing. Springer Berlin Heidelberg,2012: 291-307.
[9]Lu K, Li Z, Kemerlis V P, et al. Checking More and AlertingLess: Detecting Privacy Leakages via Enhanced Data-flow Analysis and PeerVoting[C]. NDSS. 2015.
