目录
XML简介
- e
XtensibleMarkup Language: 可扩展标记型语言.- 标记型语言: html是标记型语言, 也就是使用标签来操作
- 可扩展: html中标签固定, 每个标签都有特定的含义. xml中的标签可以自定定义, 也可以写中文标签.
- 用途
html用于显示数据,xml也可以用于显示数据(不是主要功能)xml主要用于 存储数据.
XML的应用
- 不同系统之间传输数据
- 用来表示生活中有关系的数据
常用于配置文件- 比如连接数据库, 要将数据库用户名密码存储到xml中, 以后要修改数据库信息, 不需要修改源码, 只需要修改配置文件即可.
XML的语法
- xml的文档声明
- 创建一个文件,后缀名为
.xml - 文档声明:写 xml 文件时必须要有文档申明,表示为 xml 文件:
<?xml version="1.0" encoding="gbk"?>文档申明必须写在第一行第一列 - 属性:
version:xml 的版本
encoding:xml 编码,有 gbk、utf-8、iso8859-1(不包含中文)
standalone:是否需要依赖其他文件 yes/no - 乱码问题:保存时的编码要和设置打开时的编码一致,不然会出现乱码
<?xml version="1.0" encoding="utf-8"?> <person> <name>张三</name> <age>20</age> </person>
- 定义元素(标签)
- 标签定义有开始也要有结束: <person></person>
- 标签没有内容,可以在标签内结束: <zy/>
- 标签必须合理嵌套: <person><name></name></person>
- 一个xml中,只能有一个
根标签,其他标签都是这个标签的子标签. - xml中把
空格和换行会当成内容来解析,下面代码在html中相同,在xml中不同.<age>20</age> <age> 20 </age>
- 定义属性
- 一个标签上可以有多个属性
<person id ="a" id2="b"></person> - 属性名不能相同
- 属性名称和属性值之间用 =,属性值用引号(单引号/双引号)
- 注释
注意: 注释不能嵌套且不能放在第一行.<!-- --> - 特殊字符(替代符号后加
;)
| 特殊字符 | 代替符号 |
|---|---|
| < | < |
| < | > |
- CDATA区
- 解决多个字符都需要转义的操作
- 把内容放到 CDATA 里面,可以直接按 文本输出
<![CDATA[ 内容 ]]>
- PI指令
- 在 xml 中设置样式
- 写法:<?xml-stylesheet type="text/css" href="css的路径"?>
- 设置样式,只能对英文标签起作用,对中文不起作用
XML约束
- 为什么要有约束?
在xml技术中,编写一个文档/文件来约束一个xml文档的书写规范、称为xml约束。因为没有约束 编写的xml文件格式就不统一.
DTD约束
跳转到目录
一、 编写步骤
- 创建一个文件 .dtd
- 看xml中有多少个元素, 有几个元素,就在dtd文件中写几个<!ELEMENT>
- 判断元素是简单元素还是复杂元素
-复杂元素: 有子元素的元素
<!ELEMENT 元素名称 (子元素)>
- 简单元素: 没有子元素
<!ELEMENT 元素名称 (#PDDATA)> - 在xml中引入dtd文件
二、 dtd的引入方式
跳转到目录
- 引入外部dtd约束
<!DOCTYPE person SYSTEM "user.dtd"> - 内部的dtd约束
<!DOCTYPE person[ <!ELEMENT person (name, age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> ]> - 使用外部的dtd文件(网络上的)
<!DOCTYPE 根元素 PUBLIC "dtd名称" "dtd文档的url"> - Demo
<?xml version="1.0" encoding="utf-8"?> <!--引入外部dtd约束--> <!--<!DOCTYPE person SYSTEM "user.dtd">--> <!--内部的dtd约束--> <!DOCTYPE person[ <!ELEMENT person (name, age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> <!ATTLIST person number ID #REQUIRED> ]> <!--使用外部的dtd文件--> <!--<!DOCTYPE 根元素 PUBLIC "dtd名称" "dtd文档的url">--> <person number="p1"> <name>zhangsan</name> <age>20</age> </person>
三、 使用dtd定义元素
-
语法:<!ELEMENT 元素名 约束>
-
简单元素:<!ELEMENT name (#PCDATA)>
(#PCDATA):约束 name 是字符串类型
EMPTY:约束元素为空
ANY:约束任意元素 -
复杂元素:<!ELEMENT student (name+,age?,sex*)>
- 表示元素出现的次数:
+:表示一次或者多次
?:表示零次或者一次
*:表示零次或者多次 -
子元素直接使用逗号隔开
表示元素出现的顺序 -
子元素直接使用 | 隔开
表示元素只能出现其中的任意一个
- Demo
<?xml version="1.0" encoding="utf-8"?>
<!--内部的dtd约束-->
<!DOCTYPE person[
<!ELEMENT person (name+, age, sex, hobby)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT sex EMPTY>
<!ELEMENT hobby ANY>
<!ATTLIST person number ID #REQUIRED>
]>
<person number="p1">
<name>zhangsan</name>
<name>zhangsan</name>
<age>20</age>
<sex></sex>
<hobby>basketball</hobby>
</person>
四、使用dtd定义属性
跳转到目录
- 语法:<!ATTLIST 元素名称 属性名称 属性类型 属性的约束>
- 属性类型
CDATA: 字符串
<!ATTLIST name ID1 CDATA #REQUIRED>枚举: (aa|bb|cc)
<!ATTLIST age ID2 (19|20|21) #IMPLIED>ID: 值只能是字母或者下划线开头
<!ATTLIST name ID3 ID #FIXED "n1"> - 属性的约束
#REQUIRED: 属性必须存在#IMPLIED: 属性可有可无#FIXED: 表示一个固定值.- 属性的值必须是设置的这个固定值.
直接值:- 不写属性,使用直接值
- 写了属性, 使用设置的那个值
五、定义实体
- 语法:<!ENTITY 实体名称 "实体的值"> eg:<!ENTITY NAME "zy">
- 使用实体:&NAME;
- 注意: 定义实体要写在内部的dtd中.
- Demo
<?xml version="1.0" encoding="utf-8"?>
<!--引入外部dtd约束-->
<!--<!DOCTYPE person SYSTEM "user.dtd">-->
<!--内部的dtd约束-->
<!DOCTYPE person[
<!ELEMENT person (name+, age, sex, hobby, learn)>
<!ELEMENT name (#PCDATA)>
<!ATTLIST name text CDATA #REQUIRED>
<!ELEMENT age (#PCDATA)>
<!ATTLIST age a (19|20|21) #REQUIRED>
<!ELEMENT sex EMPTY>
<!ATTLIST sex s (男|女) #IMPLIED>
<!ELEMENT hobby ANY>
<!ATTLIST person number ID #REQUIRED>
<!ELEMENT learn (#PCDATA)>
<!ATTLIST learn l CDATA "s123">
<!ENTITY NAME "zy">
]>
<!--使用外部的dtd文件-->
<!--<!DOCTYPE 根元素 PUBLIC "dtd名称" "dtd文档的url">-->
<person number="p1">
<name text="zy">zhangsan</name>
<name text="gzy">zhangsan</name>
<name text="gcy">&NAME;</name>
<age a="20">20</age>
<sex s="男"></sex>
<hobby>basketball</hobby>
<learn l="s2"></learn>
</person>
schema约束
跳转到目录
一、概述
- schema符合xml的语法
- 一个xml中可以有多个schema, 多个schema使用名称空间区分(类似java包名)
- dtd里有有PCDATA类型, 但是在schema可以支持更多的数据类型.
- schema更加麻烦, 限制更加严格.
- 以.xsd为后缀名
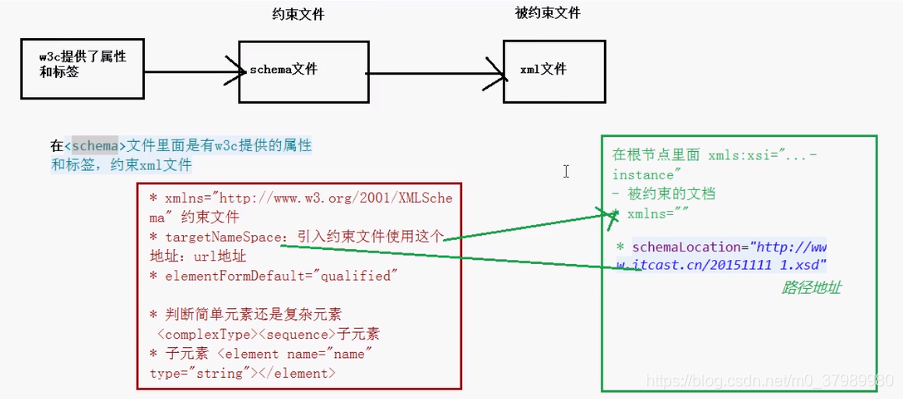
二、 schema 文件里面开头有几个属性
- xmlns=“http://www.w3.org/2001/XMLSchema”
表示当前xml是一个约束文件 - targetNamespace=“http://www.sunny.com/20191229”
使用schema约束文件,直接通过这个地址引入约束文件,可以是个随意的地址 - elementFormDefault=“qualified”>
表示质量良好
三、编写步骤
-
看 xml 中有多少个元素,有多少个元素就写多少个
-
看是简单元素还是复杂元素
复杂元素:<complexType> <sequence> 子元素 </sequence> </complexType>简单元素:写在复杂元素
<sequence>里面<sequence> <element name="name" type="string"></element> </sequence> -
在 xml 中引入 xsd 约束文件
- <zy xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
表示该文件时被约束文件 - xmlns="http://www.sunny.com/20191229 "
是约束文件里面的 targetNamespace - xsi:schemaLocation=“http://www.sunny.com/20191229 zy.xsd”>
targetNamespace + 空格 + 约束文档的地址路径
- <zy xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
zy.xsd约束文件
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.sunny.com/20191229"
elementFormDefault="qualified">
<element name="zy">
<complexType>
<sequence>
<element name="name" type="string"></element>
<element name="age" type="int"></element>
</sequence>
</complexType>
</element>
</schema>
zy.xml被约束文件
<?xml version="1.0" encoding="utf-8"?>
<zy xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.sunny.com/20191229"
xsi:schemaLocation="http://www.sunny.com/20191229 zy.xsd">
<name>gzy</name>
<age>21</age>
</zy>
四、复杂元素指示器
跳转到目录
- <sequence>:表示元素的出现顺序
- <all>:表示元素只能出现一次
- <choice>:表示元素只能出现其中一个
- <maxOccurs=“unbounded”>:表示元素出现的次数,unbounded表示不限制次数
- <any>:表示任意元素
五、约束属性
- 位置:写在复杂元素里面的 </complexType> 之前
<attribute name="id1" type="int" use="required"></attribute>- name:属性名称
- type:属性类型 int string
- use:属性是否必须出现 required
xml解析简介
跳转到目录
一、
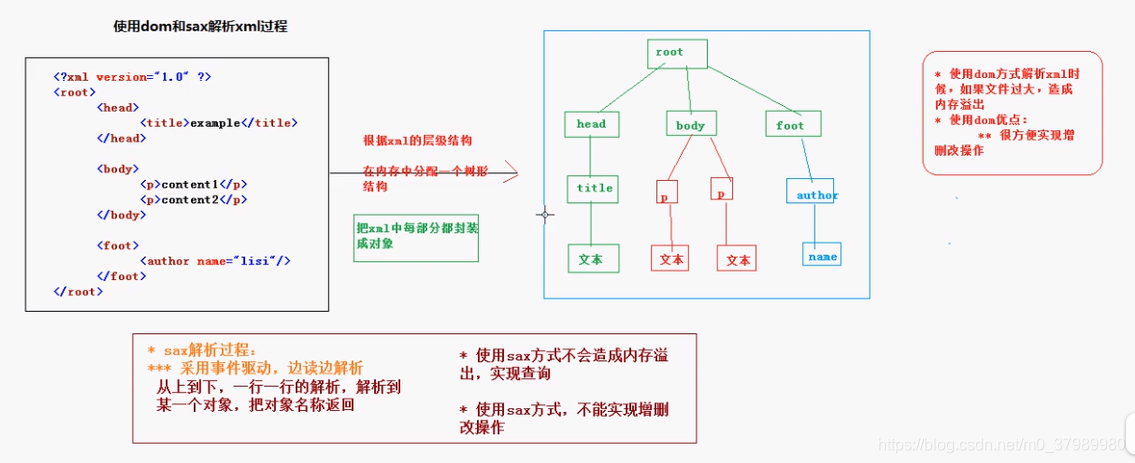
- xml是标记型文档.
- js使用dom解析标记型文档
- 根据html的层级结构, 在内存中分配一个树形结构,把html的
标签,文本,属性都封装成对象. - document对象、element对象、属性对象、文本对象、Node节点对象.
- xml的解析技术:
DOM和SAX
- 根据html的层级结构, 在内存中分配一个树形结构,把html的
DOM和SAX解析对比
- DOM 解析:
- 根据 xml 的层级结构在内存中分配一个树形结构,
把 xml 的标签,属性和文本都封装成对象. - 优点:很方便实现增、删、改操作
- 缺点:消耗内存,会造成内存溢出
- SAX 解析
- 采用事件驱动,边读边解析
从上到下,一行一行的解析,解析到某个对象就返回对象名称 - 优点:不占内存,方便实现查询操作
- 缺点:只能读取,不能实现增、删、改操作
解析器
跳转到目录
不同的公司和组织提供了针对 DOM和 SAX 方式的解析器,都是通过 api 方式提供的,主要有:
- sun 公司提供的针对 dom 和 sax 解析器:Jaxp
- dom4j 组织提供的针对 dom 和 sax 解析器:
dom4j(开发中用的最多) - jdom 组织提供的针对 dom 和sax 解析器:Jdom
- Java的HTML解析器,可以直接解析URL地址、HTML 文本内容:
Jsoup
