Hadoop系列文章 Hadoop架构、原理、特性简述

Apache™Hadoop®项目开发用于可靠、可伸缩的分布式计算的开源软件。
Apache Hadoop软件库是一个框架,它允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。它被设计成从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。而每个集群都可能容易出现故障。对于不可预料的异常情况库本身的设计目的是在应用层检测和处理故障,而不是依赖硬件来提供高可用性,因此在计算机集群之上提供高可用性服务.
hadoop大数据处理的意义
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里 。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 。
它主要有以下几个优点 :
1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理 。
2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中 。
3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 ,因为它以并行的方式工作,通过并行处理加快处理速度 。
4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配 。
5.低成本。Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++ 。此外,Hadoop 依赖于社区服务hadoop是开源的,因此它的成本比较低,任何人都可以使用 。项目的软件成本因此会大大降低 。
| 构件 | 版本 |
|---|---|
| Hadoop | 3.2.1 |
| CentOS | 7 |
| Java | 1.8 |
| IDEA | 2018.3 |
| Gradle | 4.8 |
| Springboot | 2.1.2 RELEASE |
Hadoop - 特性
Hadoop可运行于一般的商用服务器上,具有高容错、高可靠性、高扩展性等特点
Hadoop - 适用场景
适合
特别适合写一次,读多次的场景
大规模数据
流式数据(写一次,读多次)
商用硬件(一般硬件)
不适合
低延时的数据访问
大量的小文件
频繁修改文件(基本就是写1次)
Others: 利用YARN的资源管理功能实现其他的数据处理方式
内部各个节点基本都是采用Master-Woker架构
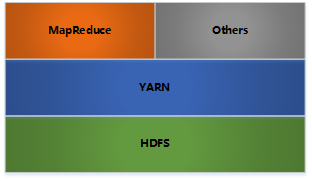
Hadoop有三大核心,四大模块。
- HDFS: 分布式文件存储
- YARN: 分布式资源管理
- MapReduce: 分布式计算
四大模块
- Hadoop Common:支持其他Hadoop模块的公共实用程序。
- Hadoop HDFS:提供对应用程序数据的高吞吐量访问的分布式文件系统。
- Hadoop yarn:一个用于作业调度和集群资源管理的框架。
- Hadoop MapReduce:一个基于yarn的大型数据集并行处理系统。
其它模块
Hadoop Ozone:用于Hadoop的对象存储。
Hadoop Submarine:adoop的机器学习引擎。
这是Apache Hadoop 3.2系列的第二个稳定版本。它包含自3.2.0以来的493个bug修复、改进和增强
Hadoop HDFS
HDFS介绍
Hadoop分布式文件系统(HDFS)是一个设计用于在普通硬件上运行的分布式文件系统。它与现有的分布式文件系统有许多相似之处。但是,与其他分布式文件系统的区别非常明显。HDFS是高度容错的,设计用于部署在低成本的硬件上。HDFS提供对应用程序数据的高吞吐量访问,适用于具有大数据集的应用程序。HDFS放宽了对POSIX的一些要求,允许对文件系统数据进行流访问。HDFS最初是作为Apache
Nutch web搜索引擎项目的基础架构构建的。HDFS是Apache Hadoop Core项目的一部分。
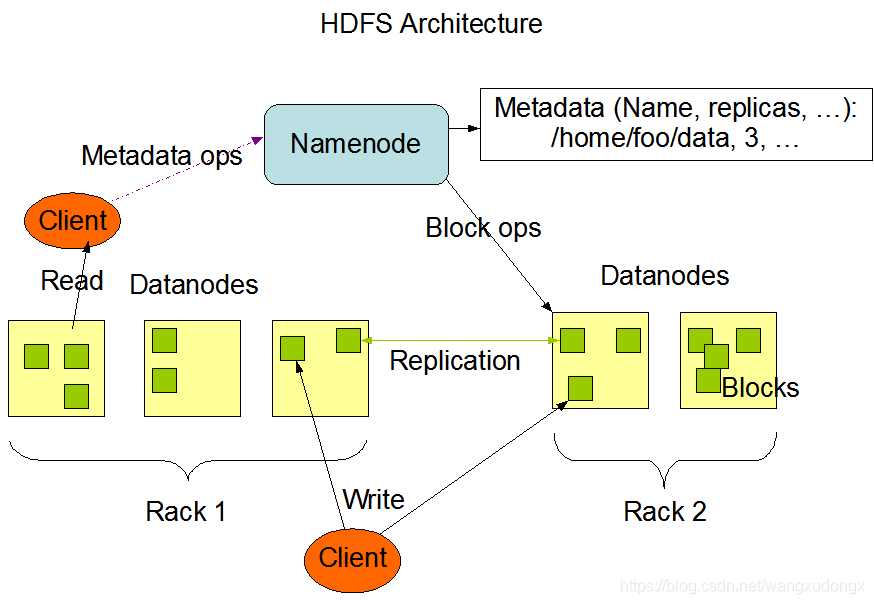
HDFS架构图
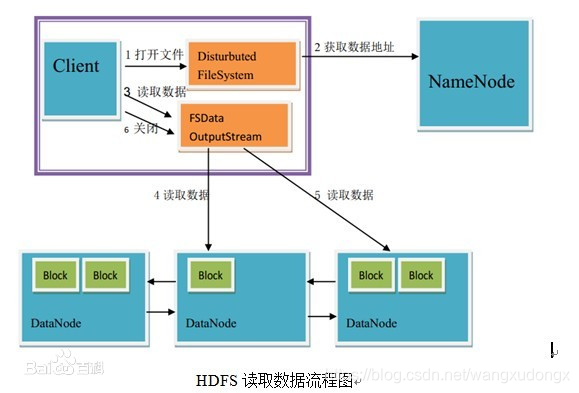
HDFS写入数据流程图

HDFS读取数据流程图
数据块的副本集
HDFS被设计成在大型集群中的机器之间可靠地存储非常大的文件。它将每个文件存储为块序列。复制文件的块是为了容错。每个文件都可以配置块大小和复制因子。
除了最后一个块之外,文件中的所有块大小都是相同的,而用户可以在append和hsync中添加可变长度块支持之后,不需要按照配置的块大小填写最后一个块,就可以启动一个新块。
应用程序可以指定文件的副本数量。复制因子可以在文件创建时指定,以后可以更改。HDFS中的文件只写一次(附加和截断除外),并且任何时候只有一个写器。
NameNode做出关于复制块的所有决定。它定期从集群中的每个datanode接收一个心跳和一个块报告。接收到心跳意味着DataNode功能正常。块报告包含DataNode上的所有块的列表。
一般一个block的副本为3个。

Hadoop YARN
yarn的基本思想是将资源管理和作业调度/监视的功能划分为单独的守护进程。其思想是拥有一个全局的ResourceManager(RM)和每个应用程序的ApplicationMaster (AM)。应用程序可以是单个作业,也可以是一组作业。
ResourceManager和NodeManager构成了数据计算框架。ResourceManager是在系统中的所有应用程序之间仲裁资源的最终权威。NodeManager是每台机器的框架代理,负责容器,监视它们的资源使用(cpu、内存、磁盘、网络),并向ResourceManager/调度器报告相同的情况。
每个应用程序的ApplicationMaster实际上是一个特定于框架的库,它的任务是与ResourceManager协商资源,并与NodeManager一起执行和监视任务。
YARN工作流程图

YARN的原理及目标
ResourceManager(YARN)有两个主要组件:调度程序和应用程序管理器。
调度器负责将资源分配给各种正在运行的应用程序,这些应用程序受到熟悉的容量、队列等约束。调度器是纯调度器,因为它不执行对应用程序状态的监视或跟踪。此外,它也不能保证由于应用程序故障或硬件故障而重新启动失败的任务。调度程序根据应用程序的资源需求执行调度功能;它是基于资源容器的抽象概念来实现的,其中包含了诸如内存、cpu、磁盘、网络等元素。
调度器有一个可插拔的策略,负责在各种队列、应用程序等之间对集群资源进行分区。当前的调度器,如电容调度器和FairScheduler是一些插件的例子。
ApplicationsManager负责接受提交的作业,协商执行特定于应用程序的ApplicationMaster的第一个容器,并在出现故障时提供重新启动ApplicationMaster容器的服务。每个应用程序ApplicationMaster负责从调度器协商适当的资源容器,跟踪它们的状态并监视进度。
在hadoop-2 MapReduce。x与以前的稳定版本(hadoop-1.x)保持API兼容性。这意味着所有的MapReduce作业仍然可以在YARN上运行,而无需修改,只需重新编译即可。
YARN支持通过ReservationSystem来保留资源的概念,该组件允许用户指定资源超时和时间限制(例如,截止日期)的配置文件,并保留资源以确保重要任务的可预测执行。ReservationSystem超时跟踪资源,对预订执行许可控制,并动态指示底层调度器确保预订已满。
为了使YARN的规模超过数千个节点,YARN通过YARN联合特性支持联合的概念。联邦允许透明地将多个YARN(子)簇连接在一起,并使它们作为单个大型簇出现。这可以用于实现更大的规模,并/或允许多个独立集群一起用于非常大的作业,或用于具有跨所有作业容量的租户。
Hadoop通过Yarn与用户程序与Hadoop基础框架完全解耦。
之后Yarn上就可以运行各种类型的分布式运算程序(mapreduce只是其中的一种),比如mapreduce、storm程序,spark程序……
Hadoop MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
Hadoop MapReduce是一个软件框架,用于以可靠的、容错的方式在大型集群(数千个节点)上并行处理大量数据(多tb数据集)的应用程序。
MapReduce作业通常将输入数据集分割成独立的块,这些块由map任务以完全并行的方式进行处理。框架对映射的输出进行排序,然后将其输入到reduce任务中。通常,作业的输入和输出都存储在文件系统中。该框架负责调度任务、监视任务并重新执行失败的任务。
通常,计算节点和存储节点是相同的,也就是说,MapReduce框架和Hadoop分布式文件系统(请参阅HDFS体系结构指南)在同一组节点上运行。这种配置允许框架在数据已经存在的节点上有效地调度任务,从而产生跨集群的非常高的聚合带宽。
MapReduce框架由单个主资源管理器、每个集群节点一个工作节点管理器和每个应用程序的MRAppMaster(参见纱线架构指南)组成。
至少,应用程序通过实现适当的接口和/或抽象类来指定输入/输出位置,并提供映射和reduce功能。这些和其他作业参数组成了作业配置。
然后Hadoop作业客户端将作业(jar/可执行文件等)和配置提交给ResourceManager,
ResourceManager负责将软件/配置分发给工作者,安排任务并监视它们,向作业客户端提供状态和诊断信息。
尽管Hadoop框架是在Java™中实现的,但MapReduce应用程序不需要用Java编写。
Hadoop流是一个实用工具,它允许用户使用任何可执行程序(如shell实用程序)来创建和运行作业,比如映射器和/或减速器。 Hadoop
Pipes是一个与swig兼容的c++ API,用于实现MapReduce应用程序(非基于JNI™)。
MapReduce工作流程
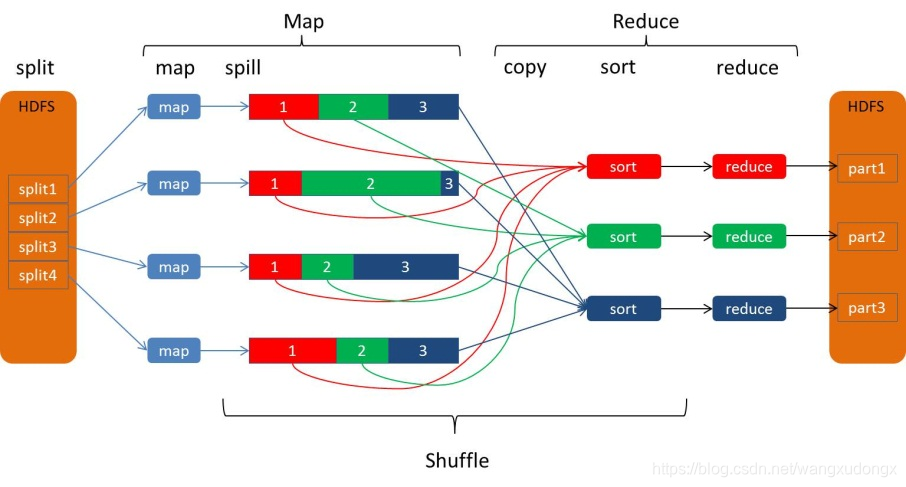
MapReduce编程模型
MapReduce主要的构件有
- Input:分布式计算程序的数据输入源。
- Job:用户的每一个计算请求,为一个作业。
- Task:每一个作业,都需要拆分开来,交由多个服务器来完成,拆分出来的执行单位,就成为任务。(Task分为MapTask和ReduceTask两种,分别进行Map操作和Reduce操作)
- Map:是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对
- Reduce:指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组
- Output:计算之后的结果。
一般来说,大家在写MapReduce程序时就是指定数据输入,实现Map函数,实现Reduce函数,最后指定输出就完了。
