
MTCNN(Multi-task Cascaded Convolutional Networks)算法是用来同时实现face detection和alignment,也就是人脸检测和对齐。
今天详细分析下关键部分程序。
| 系列 | 内容 |
|---|---|
| 深度学习 | MTCNN-人脸识别代码分析 |
DetectFace API 接口
int MtcnnPro::DetectFace() {
if(!mIsInitOk)
return -1;
ImgBuf* buf = GetFreeImgBuffer();
if(buf)
{
//读入图像信息
cv::Mat cv_img = cv::Mat(mVideoHeight, mVideoWidth, CV_8UC1, (void*)buf->buffer);
cv::Mat cv_640x480 = cv_img;
//判断是否大于规定分辨率
if(480 < cv_img.rows || 640 < cv_img.cols) {
//输出分辨率640 480
cv::resize(cv_img, cv_640x480, cv::Size(640, 480), 0, 0, cv::INTER_LINEAR);
}
cv::Mat cv_Resize = cv_640x480;
//将读取的输入图片转化为ncnn::Mat input数据类型
ncnn::Mat img = ncnn::Mat::from_pixels(cv_Resize.data, ncnn::Mat::PIXEL_GRAY2BGR, cv_Resize.cols, cv_Resize.rows);
//人脸识别框信息
std::vector<Bbox> finalBbox;//人脸识别框信息
//人脸的检测
if(!mUseMaxFaceDet)
mtcnn->detect(img, finalBbox);
else
mtcnn->detectMaxFace(img, finalBbox);
...
}
detect 识别程序过程

img_可以是任意大小的图片,用来传入我们要检测的图片
finalBbox_输出分为3部分:
face classification:输入图像为人脸图像的概率bounding box:输出矩形框位置信息facial landmark localization:输入人脸样本的5个关键点位置。
输出结构体如下:
//人脸识别框
struct Bbox
{
float score;//得分
int x1; //坐标值
int y1;
int x2;
int y2;
float area; //面积
float ppoint[10]; //人脸的特征点
float regreCoord[4];//4个坐标的修正信息,返回的是框的比例
Bbox& copy(const Bbox& bbox)
{
if(&bbox == this)
return *this;
this->x1 = bbox.x1;
this->y1 = bbox.y1;
this->x2 = bbox.x2;
this->y2 = bbox.y2;
this->area = bbox.area;
memcpy(this->ppoint, bbox.ppoint, sizeof(bbox.ppoint));
memcpy(this->regreCoord, bbox.regreCoord, sizeof(bbox.regreCoord));
return *this;
}
};

void MTCNN::detect(ncnn::Mat &img_, std::vector<Bbox> &finalBbox_) {
img = img_;
img_w = img.w;
img_h = img.h;
//各个通道均值
const float mean_vals[3] = {127.5, 127.5, 127.5};
const float norm_vals[3] = {0.0078125, 0.0078125, 0.0078125};
//图像减去均值归一化
img.substract_mean_normalize(mean_vals, norm_vals);
PNet();
if (firstBbox_.size() < 1) return;
nms(firstBbox_, nms_threshold[0]);
refine(firstBbox_, img_h, img_w, true);
RNet();
if (secondBbox_.size() < 1) return;
nms(secondBbox_, nms_threshold[1]);
refine(secondBbox_, img_h, img_w, true);
ONet();
if (thirdBbox_.size() < 1) return;
refine(thirdBbox_, img_h, img_w, false);
nms(thirdBbox_, nms_threshold[2], "Min");
LNet();
finalBbox_ = thirdBbox_;
}
P-Net网络代码
P-Net(Proposal Network)是一个全连接卷积神经网络.
在mtcnn算法中的Pnet是为了得到一批人脸框。

过程如下:
- 针对金字塔中每张图,网络
forward计算后都得到了人脸得分以及人脸框回归的结果。 - 人脸分类得分是两个通道的三维矩阵
m* m* 2,其实对应在网络输入图片上m* m个12* 12的滑框,
结合当前图片在金字塔图片中的缩放scale,可以推算出每个滑框在原始图像中的具体坐标。 - 然后要根据得分进行筛选,得分低于阈值的滑框,排除。
- 当金字塔中所有图片处理完后,再利用
nms对汇总的滑框进行合并,然后利用最后剩余的滑框对应的Bbox结果转换成原始图像中像素坐标,也就是得到了人脸框的坐标。 P-net最终能够得到了一批人脸框。
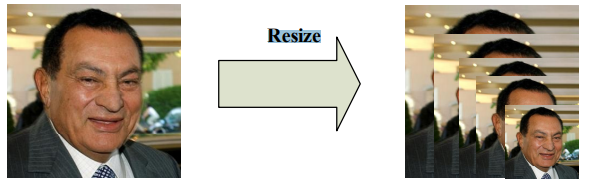
其中缩放过程图如下
扫描二维码关注公众号,回复:
8834139 查看本文章

const int MIN_DET_SIZE = 12; //最小检测尺寸
const float pre_facetor = 0.709f;
void MTCNN::PNet() {
firstBbox_.clear();
float minl = img_w < img_h ? img_w : img_h;
float m = (float) MIN_DET_SIZE / minsize; //图像缩小倍数
minl *= m;
float factor = pre_facetor;
vector<float> scales_;
while (minl > MIN_DET_SIZE) {
scales_.push_back(m);
minl *= factor;
m = m * factor;
}
for (size_t i = 0; i < scales_.size(); i++) {
//计算应缩放的长和宽
int hs = (int) ceil(img_h * scales_[i]);
int ws = (int) ceil(img_w * scales_[i]);
ncnn::Mat in;
//通过双线性插值法将 `images`大小调整
resize_bilinear(img, in, ws, hs);
//实例化Extractor
ncnn::Extractor ex = Pnet.create_extractor();
//设置线程数
ex.set_num_threads(num_threads);
//模型 提取器
ex.set_light_mode(true);
//将'data'节点名称和ncnn::Mat input对应起来
ex.input("data", in);
//执行前向网络,获得计算结果
ncnn::Mat score_, location_, landmarks_;
//分类loss值
ex.extract("prob", score_);
//回归框loss值
ex.extract("bbox_pred", location_);
//面部轮廓loss值
ex.extract("landmark_pred", landmarks_);
std::vector<Bbox> boundingBox_;
//根据Pnet的输出结果,由滑框的得分,筛选可能是人脸的滑框,并记录该框的位置、人脸坐标信息、得分以及编号
//详细内容见下
generateBbox(score_, location_, landmarks_, boundingBox_, scales_[i]);
//非极大值抑制方法
//详细内容见下
nms(boundingBox_, nms_threshold[0]);
//boundingBox 全部插入 firstBbox
firstBbox_.insert(firstBbox.end(), boundingBox_.begin(), boundingBox_.end());
boundingBox_.clear();
}
}
候选框的生成程序

虽然网络定义的时候input的size是12 * 12* 3,由于Pnet只有卷积层,我们可以直接将resize后的图像给网络进行前传,只是得到的结果不是1* 1* 2和1* 1* 4,而是m* m* 2和m* m* 4。
这样就不用先从resize的图上滑动截取各种12* 12* 3的图进入网络,而是一次性送入通过卷积,在根据结果回推每个结果对应的12* 12的图在输入图的什么位置。利用的就是卷积来代替原来的滑动窗口。
然后利用nms非极大值抑制,对剩下的滑框进行合并。
void MTCNN::generateBbox(ncnn::Mat score, ncnn::Mat location, ncnn::Mat landmarks,
vector<Bbox> &boundingBox_, float scale) {
//Pnet中有一次MP2*2,后续转换的时候相当于stride=2;
const int stride = 2;
//人脸的最小检测范围
const int cellsize = 12;
//判定为人脸的概率
float *p = score.channel(1);
//人脸框
Bbox bbox;
//放大倍数
float inv_scale = 1.0f / scale;
for (int row = 0; row < score.h; row++) {
for (int col = 0; col < score.w; col++) {
//人脸的概率大于阈值才生产候选框
if (*p > threshold[0]) {
//记录得分
bbox.score = *p;
//卷积代替滑动窗口过程,所以每一个值,对应的就是图中的一个窗口
//*inv_scale是为了定位在原图中的坐标
bbox.x1 = round((stride * col + 1) * inv_scale);
bbox.y1 = round((stride * row + 1) * inv_scale);
bbox.x2 = round((stride * col + 1 + cellsize) * inv_scale);
bbox.y2 = round((stride * row + 1 + cellsize) * inv_scale);
if((bbox.x2 - bbox.x1) > maxsize)
{
continue;
}
//候选框面积
bbox.area = (bbox.x2 - bbox.x1) * (bbox.y2 - bbox.y1);
const int index = row * score.w + col;
for (int channel = 0; channel < 4; channel++) {
//候选框的修正信息
bbox.regreCoord[channel] = location.channel(channel)[index];
}
for (int k = 0; k < 5; ++k) {
bbox.ppoint[k] =
bbox.x1 + (bbox.x2 - bbox.x1) * landmarks.channel(2 * k)[index];
bbox.ppoint[k + 5] =
bbox.y1 + (bbox.y2 - bbox.y1) * landmarks.channel(2 * k + 1)[index];
}
//boundingBox_用来存放生成候选框的集合
boundingBox_.push_back(bbox);
}
p++;
}
}
}
非极大值抑制(nms)
在人脸识别中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是人脸的概率最大),并且抑制那些分数低的窗口。
- 概念:抑制不是极大值的元素,可以理解为局部最大搜索。
- 目的:用于目标检测中提取分数最高的窗口的
- 输入:检测到的Boxes(同一个物体可能被检测到很多Boxes,每个box均有分类score)
- 输出:最优的Boxes

//其中IoU 的阈值是一个可优化的参数,一般范围为0~0.5,可以使用交叉验证来选择最优的参数。
const float nms_threshold[3] = {0.5f, 0.7f, 0.7f};
bool cmpScore(Bbox lsh, Bbox rsh) {
if (lsh.score < rsh.score)
return true;
else
return false;
}
过程:
- 将所有框的得分排序,选中最高分及其对应的框
- 遍历其余的框,如果和当前最高分框的IoU大于一定阈值,则将框删除
- 从未处理的框中继续选一个得分最高的,重复上述过程
void MTCNN::nms(std::vector<Bbox> &boundingBox_, const float overlap_threshold, string modelname) {
//框信息是否为空
if (boundingBox_.empty()) {
return;
}
//3.1、将候选框按照置信度冒泡排序
sort(boundingBox_.begin(), boundingBox_.end(), cmpScore);
float IOU = 0;
float maxX = 0;
float maxY = 0;
float minX = 0;
float minY = 0;
std::vector<int> vPick;
int nPick = 0;
//有重复键值的STL map类型
std::multimap<float, int> vScores;
const int num_boxes = boundingBox_.size();
//缩放
vPick.resize(num_boxes);
//人脸框得分
for (int i = 0; i < num_boxes; ++i) {
vScores.insert(std::pair<float, int>(boundingBox_[i].score, i));
}
//返回容纳的元素数
while (vScores.size() > 0) {
//返回一个指向mulitmap尾部的逆向迭代器
int last = vScores.rbegin()->second;
vPick[nPick] = last;
nPick += 1;
//遍历整个multimap
for (std::multimap<float, int>::iterator it = vScores.begin(); it != vScores.end();) {
int it_idx = it->second;
//计算剩余 boxes 与当前 box 的重叠程度 IoU
maxX = std::max(boundingBox_.at(it_idx).x1, boundingBox_.at(last).x1);
maxY = std::max(boundingBox_.at(it_idx).y1, boundingBox_.at(last).y1);
minX = std::min(boundingBox_.at(it_idx).x2, boundingBox_.at(last).x2);
minY = std::min(boundingBox_.at(it_idx).y2, boundingBox_.at(last).y2);
//IoU
maxX = ((minX - maxX + 1) > 0) ? (minX - maxX + 1) : 0;
maxY = ((minY - maxY + 1) > 0) ? (minY - maxY + 1) : 0;
//其他框和选出的框的相交面积
IOU = maxX * maxY;
//判断字符串
if (!modelname.compare("Union"))
IOU = IOU / (boundingBox_.at(it_idx).area + boundingBox_.at(last).area - IOU);
//是否是最小
else if (!modelname.compare("Min")) {
IOU = IOU / ((boundingBox_.at(it_idx).area < boundingBox_.at(last).area)
? boundingBox_.at(it_idx).area : boundingBox_.at(last).area);
}
if (IOU > overlap_threshold) {
//清除被抑制的候选框
it = vScores.erase(it);
} else {
//保留 IoU 小于设定阈值的 boxes
it++;
}
}
}
vPick.resize(nPick);
std::vector<Bbox> tmp_;
tmp_.resize(nPick);
for (int i = 0; i < nPick; i++) {
tmp_[i] = boundingBox_[vPick[i]];
}
boundingBox_ = tmp_;
}
剩下几个网络将在后面几篇分析。
