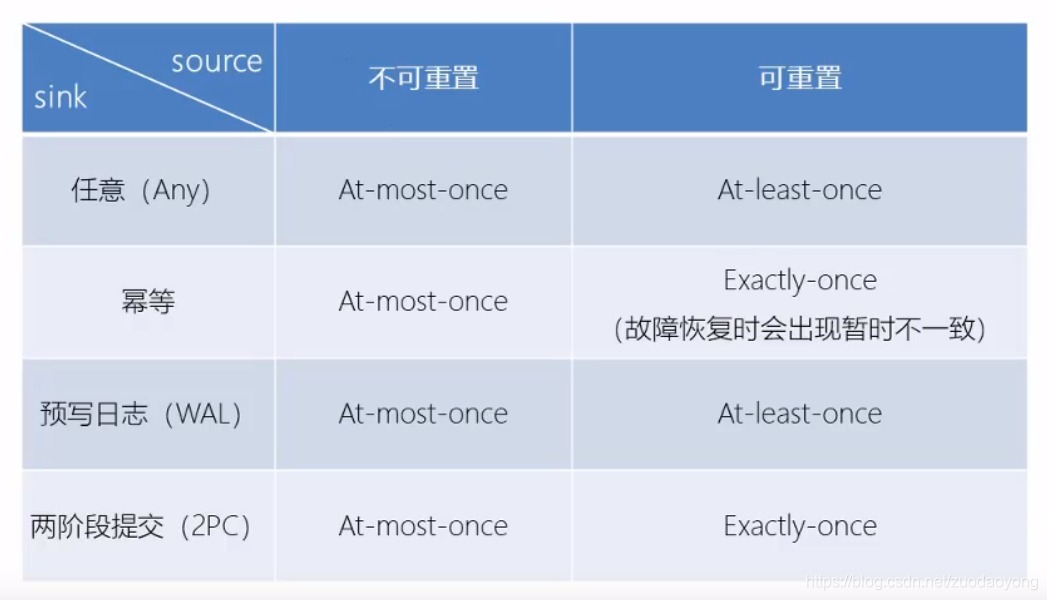
一、状态一致性分类
(1)最多一次(at most once)
当故障发生,什么都不干,既不恢复丢失状态,也不重播丢失的数据。
(2)至少一次(at least once)
所有事件都处理了,有的事件可能被处理多次
(3)精确一次(exactly once)
所有事件仅仅被处理一次
二、端到端的状态一致性
(1)内部保证(checkpoint)
(2)source端(可重设数据的读取位置)
(3)sink端(从故障恢复时数据不会重复写入外部系统,比如幂等写入,事务写入)
事务写入的实现思想:构建的事务对应着checkpoint,等到checkpoint真正完成的时候,才把所有对应的结果写入sink中
实现方式有两种:预写日志,两阶段提交
1)预写日志
把结果数据先当成状态保存,然后在收到的checkpoint完成通知时一次性写入sink
DataStream API提供了一个模板类,GenericWriteAheadSink,来实现事务性sink
注意:checkpoint完成了,但是写入sink只有一半写入成功,则不能保证一致性
2)两阶段提交
i)每个checkpoint,sink任务会启动一个事务,并将接下来的所有接受的数据添加到事务里
ii)然后将这些数据写入外部sink系统,但不是提交,这次是预提交
iii)当收到checkpoint完成通知时,它才会正式提交事务,实现结果的真正写入
Flink提供了TwoPhaseCommitSinkFunction接口
注意:这种机制需要外部sink系统支持事务
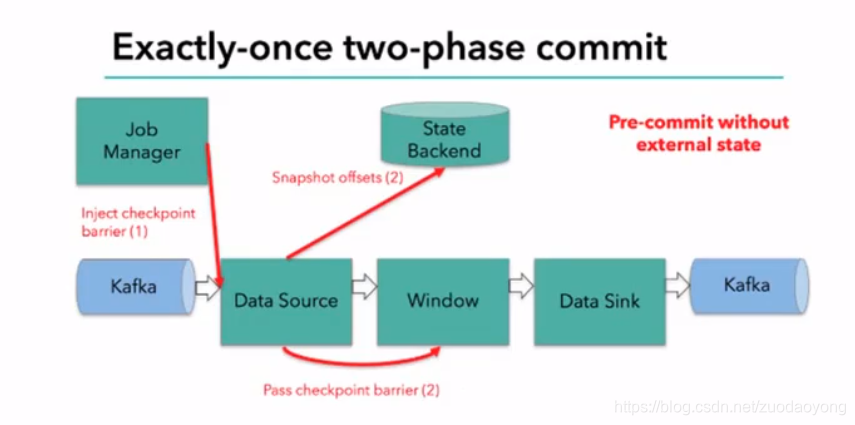
三、kafka+Flink端到端状态一致性保证
内部:利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
source:kafka consumer作为source,可以将偏移量保存下来,故障恢复时可以由连接器重置偏移量,重新消费数据,保证一致性
sink:kafka producer作为sink,采用两阶段提交sink,需要实现一个TwoPhaseCommitSinkFunction

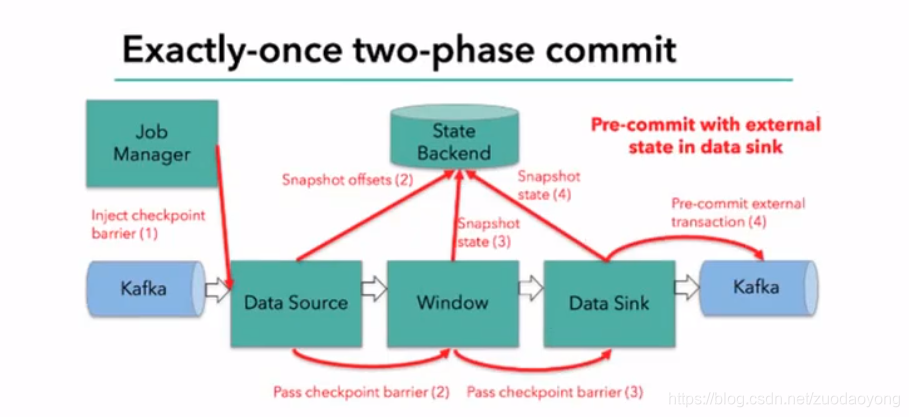
注意:sink任务首先把数据写入外部kafka,这些数据都属于预提交的事务里的,遇到barrier时把状态保存到状态后端,并开启新的预提交事务

当所有算子任务的快照完成,即checkpoint完成,jobmanager会向所有任务发通知,确认这次checkpoint完成
sink任务收到确认通知,正式提交之前的事务,kafka中未确认的数据改为“已确认”
总结两阶段提交步骤:
(1)第一条数据来了之后,开启一个kafka的事务,正常写入kafka分区日志,但标记为未提交,这就是“预提交”
(2)jobmanager触发checkpoint操作barrier从source开始向下传递,遇到barrier的算子将状态存入后端,并通知jobmanager
(3)sink连接器收到barrier,保存当前状态,存入checkpoint,通知jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据。
(4)jobmanager收到所有任务的通知,发出确认信息,表示当前checkpoint完成
(5)sink任务收到jobmanager的确认信息,正式提交这段时间的数据
(6)外部kafka关闭事务,提交的数据可以正常被消费
