(接上文)
为了对神经网络的分类(拟合)效果进行测试,我们可以使用另一组训练样本,进行试分类,评价其代价函数的收敛程度。
1. 模型测试
该测试程序读取测试数据,并应用当前训练好的模型,进行分类,计算代价函数。如果模型奇异,则代价函数相较训练集会较高,反之,较低(一致):
运行结果:
Testing...
1024 0.0035852
2048 0.00231017
3072 0.00157589
4096 0.00172059
5120 0.00321012
6144 0.00346273
7168 0.00267906
8192 0.00247223
9216 0.00233935
10240 0.00288214
11264 0.002231
12288 0.00120241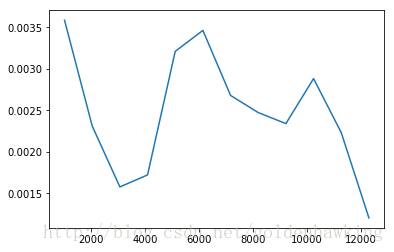
测试程序的完整代码:
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 26 15:24:50 2017
gn_test_model.py
@author: goldenhawking
"""
from __future__ import print_function
import tensorflow as tf
import numpy as np
import configparser
import re
import matplotlib.pyplot as mpl
trainning_task_file = 'train_task.cfg'
testing_file = 'test_set.txt'
model_path = './saved_model/'
#读取配置
config = configparser.ConfigParser()
config.read(trainning_task_file)
n = int(config['network']['input_nodes']) # input vector size
K = int(config['network']['output_nodes']) # output vector size
lam = float(config['network']['lambda'])
#隐层规模 用逗号分开,类似 ”16,16,13“
hidden_layer_size = config['network']['hidden_layer_size']
#分离字符
reobj = re.compile('[\s,\"]')
ls_array = reobj.split(hidden_layer_size);
ls_array = [item for item in filter(lambda x:x != '', ls_array)] #删空白
#隐层个数
hidden_layer_elems = len(ls_array);
#转为整形,并计入输出层
ns_array = []
for idx in range(0,hidden_layer_elems) :
ns_array.append(int(ls_array[idx]))
#Output is the last layer, append to last
ns_array.append(K)
#总层数(含有输出层)
total_layer_size = len(ns_array)
#--------------------------------------------------------------
#create graph
graph = tf.Graph()
with graph.as_default():
with tf.name_scope('network'):
with tf.name_scope('input'):
s = [n]
a = [tf.placeholder(tf.float32,[None,s[0]],name="in")]
W = []
b = []
z = []
punish = tf.constant(0.0)
for idx in range(0,total_layer_size) :
with tf.name_scope('layer'+str(idx+1)):
s.append(int(ns_array[idx]))
W.append(tf.Variable(tf.random_uniform([s[idx],s[idx+1]],0,1),name='W'+str(idx+1)))
b.append(tf.Variable(tf.random_uniform([1],0,1),name='b'+str(idx+1)))
z.append(tf.matmul(a[idx],W[idx]) + b[idx]*tf.ones([1,s[idx+1]],name='z'+str(idx+1)))
a.append(tf.nn.tanh(z[idx],name='a'+str(idx+1)))
with tf.name_scope('regular'):
punish = punish + tf.reduce_sum(W[idx]**2) * lam
#--------------------------------------------------------------
with tf.name_scope('loss'):
y_ = tf.placeholder(tf.float32,[None,K],name="tr_out")
loss = tf.reduce_mean(tf.square(a[total_layer_size]-y_),name="loss") + punish
with tf.name_scope('trainning'):
optimizer = tf.train.AdamOptimizer(name="opt")
train = optimizer.minimize(loss,name="train")
init = tf.global_variables_initializer()
#save graph to Disk
saver = tf.train.Saver()
#--------------------------------------------------------------
### create tensorflow structure end ###
sess = tf.Session(graph=graph)
check_point_path = model_path # 保存好模型的文件路径
ckpt = tf.train.get_checkpoint_state(checkpoint_dir=check_point_path)
saver.restore(sess,ckpt.model_checkpoint_path)
#--------------------------------------------------------------
file_deal_times = int(config['performance']['file_deal_times'])
trunk = int(config['performance']['trunk'])
train_step = int(config['performance']['train_step'])
iterate_times = int(config['performance']['iterate_times'])
print ("Testing...")
#testing
x_test = np.zeros([trunk,n]).astype(np.float32)
#read n features and K outputs
y_test = np.zeros([trunk,K]).astype(np.float32)
total_red = 0
plot_x = []
plot_y = []
with open(testing_file, 'rt') as testfile:
while 1:
lines = testfile.readlines()
if not lines:
break
line_count = len(lines)
for lct in range(line_count):
x_arr = reobj.split(lines[lct]);
x_arr = [item for item in filter(lambda x:x != '', x_arr)] #remove null strings
for idx in range(n) :
x_test[total_red % trunk,idx] = float(x_arr[idx])
for idx in range(K) :
y_test[total_red % trunk,idx] = float(x_arr[idx+n])
total_red = total_red + 1
#the trainning set run trainning
if (total_red % train_step == 0):
#print loss
lss = sess.run(loss,feed_dict={a[0]:x_test[0:min(total_red,trunk)+1],y_:y_test[0:min(total_red,trunk)+1]})
print(total_red,lss)
plot_x.append(total_red)
plot_y.append(lss)
mpl.plot(plot_x,plot_y)
2. 模型应用
下面这个程序,读取给定的特征,产生分类结果。我们把分类器的输出,存为一个文本文件。
这个文本文件每一行为一个结果,由两部分组成,特征、分类(或者拟合)结果。
[-0.24751600623130798, -0.9268109798431396] [0.9986907243728638, -0.000654876115731895, -0.00044381615589372814]
[0.045763999223709106, 0.5164780020713806] [0.9986994862556458, -0.0026147901080548763, -0.001965639414265752]
[-0.6250460147857666, -0.8338379859924316] [-0.00046735999058000743, -0.0015115130227059126, 0.9921404719352722]
[0.6993309855461121, -0.042775001376867294] [0.9986986517906189, -0.0005539059056900442, -0.00046229359577409923]
[0.9839800000190735, 0.19465599954128265] [0.9986998438835144, -0.0009445545147173107, -0.0008026955765672028]
[-0.12072400003671646, 0.5291630029678345] [0.9986990690231323, 6.365776062011719e-05, -4.45246696472168e-05]
[0.11185800284147263, 0.20474199950695038] [0.9986990690231323, -0.00044244524906389415, -0.0004038810438942164]
可以使用最大值判决,来对输出的浮点型判决结果进行分类。同时,通过比值,可以看出分类的区分度。
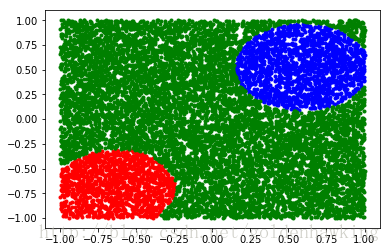
附带源代码:
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 26 15:24:50 2017
gn_run_model.py
@author: goldenhawking
"""
from __future__ import print_function
import tensorflow as tf
import numpy as np
import configparser
import re
import matplotlib.pyplot as mpl
trainning_task_file = 'train_task.cfg'
input_file = 'test_set.txt'
output_file = 'result.txt'
model_path = './saved_model/'
#读取配置
config = configparser.ConfigParser()
config.read(trainning_task_file)
n = int(config['network']['input_nodes']) # input vector size
K = int(config['network']['output_nodes']) # output vector size
lam = float(config['network']['lambda'])
#隐层规模 用逗号分开,类似 ”16,16,13“
hidden_layer_size = config['network']['hidden_layer_size']
#分离字符
reobj = re.compile('[\s,\"]')
ls_array = reobj.split(hidden_layer_size);
ls_array = [item for item in filter(lambda x:x != '', ls_array)] #删空白
#隐层个数
hidden_layer_elems = len(ls_array);
#转为整形,并计入输出层
ns_array = []
for idx in range(0,hidden_layer_elems) :
ns_array.append(int(ls_array[idx]))
#Output is the last layer, append to last
ns_array.append(K)
#总层数(含有输出层)
total_layer_size = len(ns_array)
#--------------------------------------------------------------
#create graph
graph = tf.Graph()
with graph.as_default():
with tf.name_scope('network'):
with tf.name_scope('input'):
s = [n]
a = [tf.placeholder(tf.float32,[None,s[0]],name="in")]
W = []
b = []
z = []
punish = tf.constant(0.0)
for idx in range(0,total_layer_size) :
with tf.name_scope('layer'+str(idx+1)):
s.append(int(ns_array[idx]))
W.append(tf.Variable(tf.random_uniform([s[idx],s[idx+1]],0,1),name='W'+str(idx+1)))
b.append(tf.Variable(tf.random_uniform([1],0,1),name='b'+str(idx+1)))
z.append(tf.matmul(a[idx],W[idx]) + b[idx]*tf.ones([1,s[idx+1]],name='z'+str(idx+1)))
a.append(tf.nn.tanh(z[idx],name='a'+str(idx+1)))
with tf.name_scope('regular'):
punish = punish + tf.reduce_sum(W[idx]**2) * lam
#--------------------------------------------------------------
with tf.name_scope('loss'):
y_ = tf.placeholder(tf.float32,[None,K],name="tr_out")
loss = tf.reduce_mean(tf.square(a[total_layer_size]-y_),name="loss") + punish
with tf.name_scope('trainning'):
optimizer = tf.train.AdamOptimizer(name="opt")
train = optimizer.minimize(loss,name="train")
init = tf.global_variables_initializer()
#save graph to Disk
saver = tf.train.Saver()
#--------------------------------------------------------------
### create tensorflow structure end ###
sess = tf.Session(graph=graph)
check_point_path = model_path # 保存好模型的文件路径
ckpt = tf.train.get_checkpoint_state(checkpoint_dir=check_point_path)
saver.restore(sess,ckpt.model_checkpoint_path)
#--------------------------------------------------------------
print ("Running...")
with open(input_file, 'rt') as testfile:
with open(output_file, 'wt') as resultfile:
while 1:
lines = testfile.readlines()
if not lines:
break
line_count = len(lines)
x_test = np.zeros([line_count,n]).astype(np.float32)
for lct in range(line_count):
x_arr = reobj.split(lines[lct]);
x_arr = [item for item in filter(lambda x:x != '', x_arr)] #remove null strings
for idx in range(n) :
x_test[lct,idx] = float(x_arr[idx])
#the trainning set run trainning
result = sess.run(a[total_layer_size],feed_dict={a[0]:x_test})
for idx in range(line_count):
print(x_test[idx].tolist(),result[idx].tolist(),file = resultfile)
mpl.plot(x_test[result[:,1]>=0.9,0],x_test[result[:,1]>=0.9,1],'b.');
mpl.plot(x_test[result[:,2]>=0.9,0],x_test[result[:,2]>=0.9,1],'r.');
mpl.plot(x_test[result[:,0]>=0.9,0],x_test[result[:,0]>=0.9,1],'g.');
