---恢复内容开始---
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
先启动Hadoop。

jps查看各个服务已启动,进入hive
把本地文件上传到hdfs文件系统(这里本来是打算把预先准备的英文小说上传上去,但是不知道为什么一直提示找不到文件,然后发现帮助文档和注意文档的内容量也不小,所以直接拿来做词频统计也是不错的。)

建个表docs
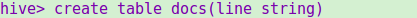
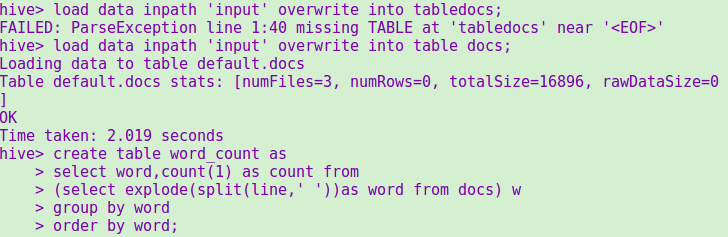
把hdfs文件系统中input文件夹里的文本文件load进去,写hiveQL命令统计
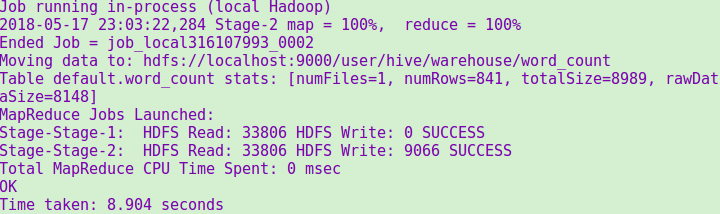
统计成功提示
使用select命令查看结果(这里的词条太多了,windows平台无法截长屏,所以只截了一小部分的结果和统计条数)
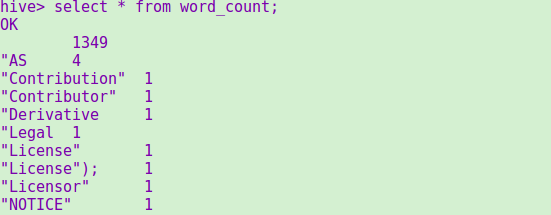

2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
暂时还不会