通常,我们会使用selenium来获取页面的元素,百度音乐(千千音乐)的爬取音乐,并下载下来。
这里,我们依然使用selenium来换取页面歌单信息,经过分析,歌单列表获取后,可以获取歌曲的song_id 和 title,获取 之后,通过开发者工具的NetWork里查看到获取音乐url的api:
http://musicapi.taihe.com/v1/restserver/ting?method=baidu.ting.song.playAAC&songid=SONGID&from=web
songid:song_id
返回值: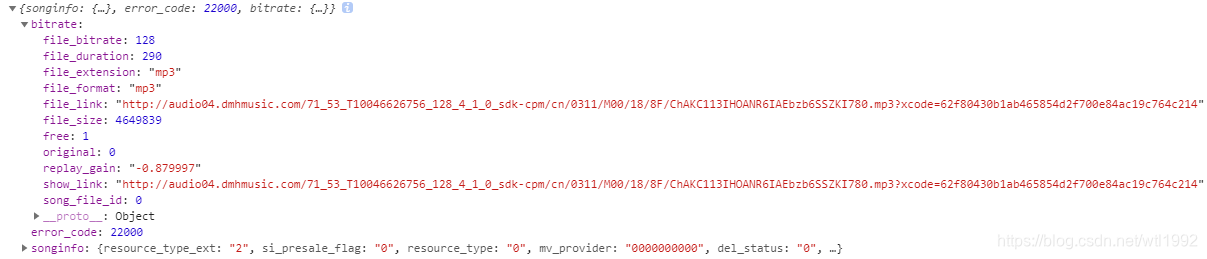
file_link就是音乐下载url。
附上代码:
import requests
from selenium import webdriver
import time
import json
if __name__ == "__main__":
list_url = "http://musicapi.taihe.com/v1/restserver/ting?method=baidu.ting.song.playAAC&songid=SONGID&from=web"
browser = webdriver.Chrome()
browser.implicitly_wait(5)
browser.get("http://music.taihe.com/top/dayhot")
elements = browser.find_elements_by_css_selector("#songListWrapper > div > ul > li.song-item-hook div.song-item span.song-title a")
for e in elements:
id = str(e.get_attribute("href")).split("/")[-1]
title = e.get_attribute("title")
result = requests.get(list_url.replace("SONGID",id))
_json_result = json.loads(result.text,encoding="utf-8")
file_link = _json_result["bitrate"]["file_link"]
content = requests.get(file_link)
with open("D:/resources/music/" + str(title).replace("/","") + ".mp3","wb") as fp:
fp.write(content.content)