这里不再介绍 mmdetection 的安装和配置,使用 mmdetection 较简单的方法是使用已安装 mmdetection 的 docker 容器。这样直接省去了安装 mmdetection 的过程,让重心放在模型训练上!
如果你对 docker 和 mmdetection 还不是很熟悉,请自行搜索一下,本文就不再赘述了。
这里附上 mmdetection 的 GitHub 地址:
https://github.com/open-mmlab/mmdetection
0. 前期准备
首先默认你的电脑已经做好了下面这些前期准备工作:
- Ubuntu 16.04 或以上
- GPU
- 安装 cuda
- 安装 cudnn
- 安装 docker
- 安装 nvidia-docker
当然,如果你连接的是公司或学校的服务器,且服务器已经做了上面几点准备,那你只需要一个 Xshell 远程登录服务器就行了。
1. 准备工作:下载含 mmdetection 的 docker 镜像
首先,我们需要找到一个已经配置好 mmdetection 环境的 docker 镜像。可以在 dockerhub 上用 “mmdetection” 作为关键词进行搜索,也可以在 terminal 里直接使用命令 docker search 进行搜索:
$ docker search mmdetection
结果显示如下图所示:
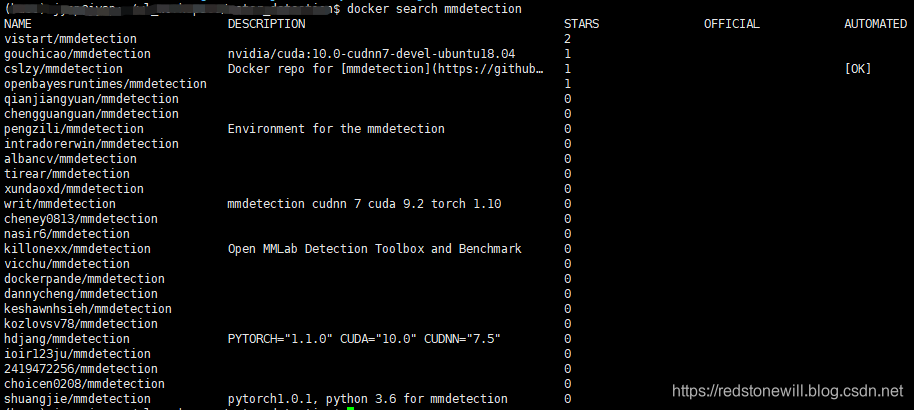
这里,我们选择排第一的 vistart/mmdetection 镜像,下载 docker 镜像的方法也很简单,使用 docker pull 从镜像仓库中拉取指定镜像:
$ docker pull vistart/mmdetection
如果网络没问题,下载会在几分钟之内完成。下载完成之后,我们就可以查看 vistart/mmdetection 镜像是否已经放在本地镜像种了:
$ docker images

可以看到 vistart/mmdetection 镜像已经成功下载了。
2. 新建含 mmdetection 的容器
包含 mmdetection 的镜像已经下载好了,下一步就是新建一个 docker 容器以供使用了:

$ docker run --runtime=nvidia --name mm_prj -i -t vistart/mmdetection /bin/bash
对上面的命令解释一下:--runtime=nvidia 很关键,能使新建的 docker 容器能使用宿主机器的 GPU,不加这个参数则默认使用 CPU;--name mm_prj 是对新建的 docker 容器进行命名,该名称为 mm_prj,读者可自行修改。
新建容器之后的界面如下:

至此,名为 mm_prj 容器已经打开了。可以看到,该目录中已经包含了 mmdetection 目录,表示该 docker 镜像已经安装好了 mmdetection。
补充:
另外,补充一些退出容器、进入容器的操作。
退出容器:
# exit
查看现有容器:
$ docker ps -a

可以看到,名为 mm_prj 的 docker 容器已经在容器列表了。
打开容器:
$ docker start mm_prj
$ docker exec -i -t mm_prj /bin/bash
3. 导入自己的 VOC 数据
这一步,我们需要把自己的数据打包成 Pascal VOC 格式。其目录结构如下:
VOCdevkit
--VOC2007
----Annotations
----ImageSets
------Main
----JEPGImages
简单介绍一下,其中 Annotations 存放的是 .xml 文件,JEPFImages 存放的是 .jpg 图片。
按照此格式放置好自己的训练数据之后,需要切分训练数据和测试数据。在 VOCdevkit 目录下新建一个 test.py 文件。test.py 内容为:
import os
import random
trainval_percent = 0.8
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
上面的代码划分数据集,trainval 占 80%,作为训练集;test 占 20%,作为测试集。
运行 test.py,将会在 VOCdevkit/ImageSets/Main 目录下生成下面三个文件:

打开文件可以看到,trainval.txt 包含训练时所有的样本索引,test.txt 包含测试时所有的样本索引。
自己的 VOC 数据制作完毕之后,从宿主机(Ubuntu)复制到 /mmdetection/data/ 目录下:
$ docker cp VOCdevkit mm_prj:/mmdetection/data/
4. 修改 class_names.py 文件
打开 /mmdetection/mmdet/core/evaluation/class_names.py 文件,修改 voc_classes 为将要训练的数据集的类别名称。如果不改的话,最后测试的结果的名称还会是’aeroplane’, ‘bicycle’, ‘bird’, ‘boat’,…这些。改完后如图:

5. 修改 voc.py 文件
打开 mmdetection/mmdet/datasets/voc.py 文件,修改 VOCDataset 的 CLASSES 为将要训练的数据集的类别名称。

如果只有一个类,要加上一个逗号,否则将会报错。
6. 修改配置文件
mmdetection 中提供了很多目标检测模型可供使用。例如,进入 /mmdetection/config/ 目录,就会看到很多模型:

根据我们选择使用的模型,修改相应的配置文件。本文我们使用的是FasterRCNN 模型,修改的是 faster_rcnn_r50_fpn_1x.py 文件。
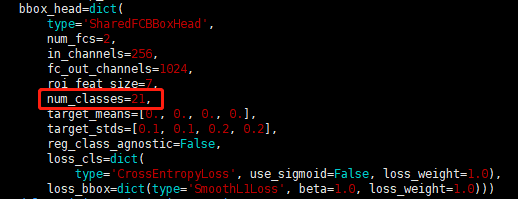
6.1 修改 num_classes 变量
打开 faster_rcnn_r50_fpn_1x.py,将 num_classes 变量改为:类别数 + 1(例如我有 20 类,因此改为 21):
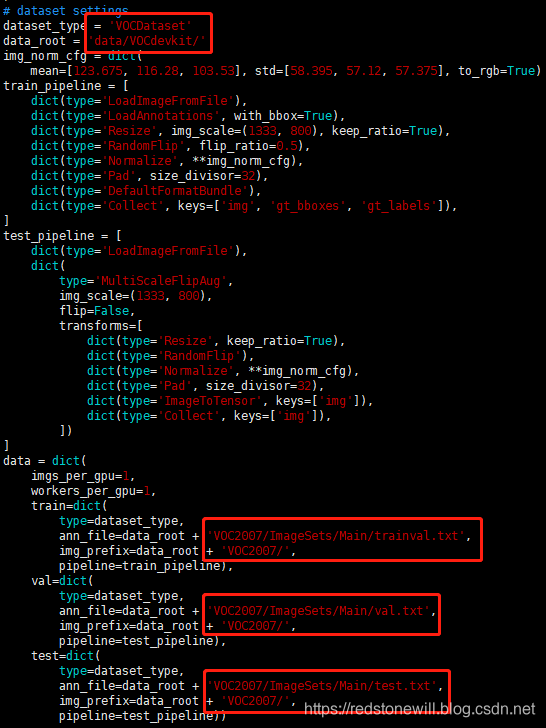
6.2 修改 data_settings
因为 faster_rcnn_r50_fpn_1x.py 默认使用的是 coco 数据集格式,我们要对其修改成相应的 VOC 数据格式。修改后的内容如下图所示:
6.3 调整学习率
本文使用单 gpu 训练,修改 img_per_gpu = 2,workers_per_gpu = 0。
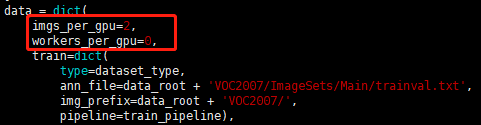
对学习率的调整,一般遵循下面的习惯:
- 8 gpus、imgs_per_gpu = 2:lr = 0.02;
- 2 gpus、imgs_per_gpu = 2 或 4 gpus、imgs_per_gpu = 1:lr = 0.005;
- 4 gpus、imgs_per_gpu = 2:lr = 0.01
这里,我们只使用单 gpu,且 img_per_gpu = 2,则设置 lr = 0.00125。

这里说一下 epoch 的选择,默认 total_epoch = 12,learning_policy 中,step = [8,11]。total_peoch 可以自行修改,若 total_epoch = 50,则 learning_policy 中,step 也相应修改,例如 step = [38,48]。
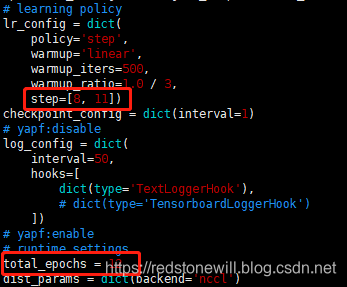
至此,配置文件已修改完毕。
7. 模型训练
模型训练非常简单,只需一行命令:
python3 ./tools/train.py ./configs/faster_rcnn_r50_fpn_1x.py
注意执行上面的命令是在 /mmdetection 目录下。
如果有多个 gpu,例如 0, 1 号 gpu 都可用,则可以全部用起来训练,命令如下:
CUDA_VISIBLE_DEVICES=0,1 python3 ./tools/train.py ./configs/faster_rcnn_r50_fpn_1x.py --gpus 2
上面的 --gpus 2 表示使用的 gpu 个数为 2。如果使用多块 gpu,注意修改学习率 lr。
然后,训练就开始了:

从打印出的信息中,可以看到当前的 epoch 和 loss 值。
每个 epoch 会生成一个模型,并自动保存在 /mmdetection/work_dirs/faster_rcnn_r50_fpn_1x/ 目录下。

训练完成之后,latest.pth 即 epoch_12.pth 就是最终的模型。
8. 模型测试,计算 mAP
下面我们将使用训练好的模型对测试集进行验证,并计算 mAP。
8.1 生成 pkl 文件
首先,生成 pkl 文件:
python3 ./tools/test.py ./configs/faster_rcnn_r50_fpn_1x.py ./work_dirs/faster_rcnn_r50_fpn_1x/latest.pth --out=result.pkl
8.2 计算测试集 mAP
对测试集计算 mAP,只需一行命令:
python3 ./tools/voc_eval.py result.pkl ./configs/faster_rcnn_r50_fpn_1x.py
计算结果如下:
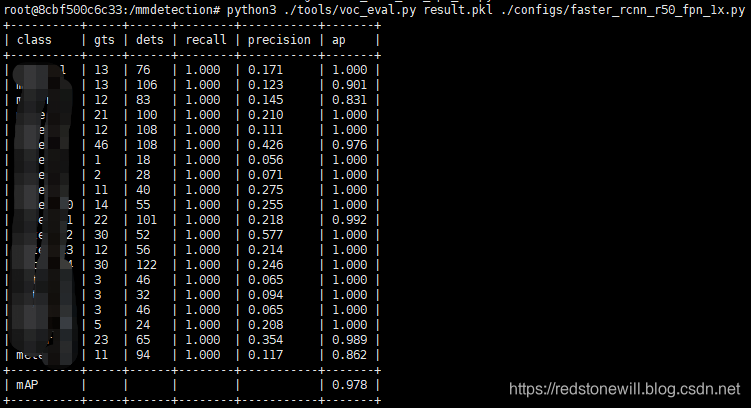
图中可以看到,最后计算的 mAP = 0.978。
