论文地址: https://arxiv.org/abs/1612.08242
或者:https://pjreddie.com/media/files/papers/YOLO9000.pdf
代码地址: http://pjreddie.com/yolo9000/
相关内容: YOLO_v1论文详解You Only Look Once,Unified, Real-Time Object Detection
目录
Dataset combination and WordTree
Joint classification and detection
一、概览
1.1 贡献点
YOLO9000,可以检测超过9000个物体的目标检测模型。
- 在YOLO的基础上,引入了各种改进。
- 在PASCAL VOC与COCO数据集上达到了SOTA
- 可以实现速度与准确率的trade off
- 模型可以进行多尺度训练,并且可以对任意尺寸的图片进行检测。
- 比目前最佳的SSD或者faster RCNN更快且准确率更佳。
- 在VOC数据集上,67FPS的时候达到76.8mAP,40FPS的时候达到78.6mAP
1.2 创新点
改进训练方法,训练模型时不仅使用目标检测的数据,也使用大量的目标分类数据。
- 引入了数据集结合的方法
- 创建了目标检测SOTA的实时模型。
- 从COCO数据集与ImageNet数据集结合模型可以分类9000样本的目标检测模型。
二、方法
2.1 Better
从之前的模型中引入了一系列新的方法

Batch Norm
BatchNorm的作用详见:
批归一化Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift论文详解
- BN的引入使得YOLO的mAP提升了2%
- BN可以有效的对模型进行正则化,避免过拟合。
High Resolution Classifier
YOLO是以224*224分辨率训练分类器网络,随后将分辨率提高到448*448进行检测,意味着网络需要可以将较低分辨率的图片泛化到较高分辨率。所以前期训练用224*224的图像,最终的10个epoch用448*448的图像进行微调。
- 提升了4%的mAP
- 所有的SOTA目标检测模型均需要通过ImageNet预训练。
- 初始YOLO训练时候用224*224大小的图像,然后需要将尺寸增加到448*448.相当于需要用大尺寸高分辨率的图像对模型进行Fine-tune。
- 对于YOLOv2,作者将ImageNet的448*448的图像在ImageNet上进行了10个epoch的fine-tune
- 我们产生了一个疑问,如果一开始直接用448*448的图像对模型进行训练,会产生什么样的结果呢?
Ancher Box
Ancher box即先验框,即网络在先验框的基础上进行预测,
- 借鉴了Faster-RCNN的做法。
- 对于Faster-RCNN来讲,region proposal network(RPN) 用于生成相应的offset与confidence。因此,作者经过改进,将YOLOv1中的全连接层删掉,运用ancher box预测相应的备选框。YOLO通过图像提取,输入图像经过缩放系数是32的尺寸缩小到feature上,例如416的图片会被缩小为13 (416/32=13).
- 无ancher box的模型,mAP 69.5,recall 81%,加入ancher box之后,mAP 69.2,recall 88%。即mAP少量降低,但是recall大量增加。
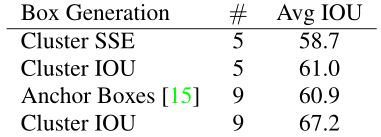
Dimension Clusters
先验框的尺寸可以手动来选择,也可以通过聚类的方法选择,作者引入聚类的方法针对ancher box的尺寸进行选择。
(聚类是否只聚类了box的尺寸,对box的位置是否有聚类?)
- 关于ancher box的尺寸,可以通过手动选择,选择较好的尺寸可以提升网络性能。作者通过K-means的聚类来选取ancher box。
聚类的距离d的衡量
k-means聚类需要有一个衡量样本之间的距离的距离度量d
- 之前采用的聚类距离d,采用几何距离,这样就会使得聚类的中大边框的聚类距离更大。
- 为了更好的平衡上面说的大边框的聚类距离d过大的问题,作者引入了IOU来实现距离d的衡量。
![]()

运用IOU作为衡量标准之后,模型精度确实得到了提升,下图是实验证明了这一点。在VOC2007上,聚类采用IOU距离取得了更高的mAP:
聚类的k值
k值表示聚类数量的个数,即备选框聚类为几类。
- 此值表示聚类出的备选框的尺寸的个数,比如k=1表示聚类结果只有一个尺寸的备选框。
- k越大则聚类的框的大小数量越多,因此准确率越高。
- 但是k值过大,运算量会增加,因此作者取了一个trade-off 的结果,k=5,相对平衡运算量和IoU精度。
Direct location prediction
此方法用于对模型的先验框的范围进行约束,可以提升5%的mAP
对于模型而言,主要的非稳定性来自于备选框的中心位置(x,y), 特别是初始的几个epoch,预测结果很不稳定。
按照原始的做法:
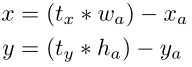
- x,y是预测边框的中心,模型需要将此结果作为最终的预测边框
- xa, ya是先验框ancher box的中心,是确定的量
- wa,ha是先验框的宽和高,是确定的量
- tx,ty是网络需要预测的参数,即网络根据已知的先验框和输入图片,预测出tx,ty
- 因为tx,ty没有任何约束,导致中心可能出现在任何位置,不确定性很高,因此需要加以约束。
约束后的公式如下:
加入限定之后,可以将蓝色区域限制在蓝色框内,预测更为稳定。

限定的公式如下:
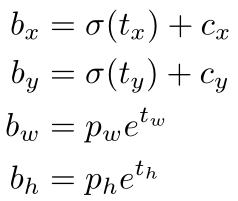
- cx,cy是先验框左上角的坐标
- pw,ph是先验框的宽和高
- tx,ty,tw,th,to是网络需要预测的量。
- 经过上面公式的映射,相应的备选框可以被限定在虚线框内,相对更稳定。
![]()
Multi-scale training
多尺度训练,提升了1.4的mAP
- 原始的YOLO输入图象是448*448大小,加入ancher box之后,输入尺寸变为416*416大小。
- 因为模型有卷积和pooling层,因此可以适应任意大小的图像。(YOLO是可以对任意尺寸的图像进行目标检测。这里的同尺寸是指训练与测试同尺寸且任意尺寸?还是训练与测试可以不同尺寸?)
- 训练每10个batch,YOLO随机选择一个新的图像尺寸。尺寸有{320, 352, ... , 608}
- 因为YOLO可以针对尺寸的图片进行目标检测,因此,YOLO可以用低分辨率的图片实现高帧率。
- 在228*228大小的时候,YOLO可以实现90FPS的帧率,并且具有与fast R-CNN几乎相同的mAP
- 高分辨率模式之下,YOLO在VOC2007数据集上达到了最佳的78.6的mAP,下图即为各个分辨率下YOLO的识别准确率以及同类网络的对比。

2.2 faster
不少目标检测模型将VGG作为基本框架。但是VGG较为耗费运算,例如对于224*224大小的图像,VGG需要进行30.69billion(30.69*10^9)次浮点运算进行一次预测,因此运算量巨大。
DarkNet-19
YOLO在VGG的基础上进行更改,只需要8.52Billion次浮点运算即可进行一次前馈运算。
YOLOv2运用darknet-19结构(如下表),19个conv,5个max_pooling,相比VGG浮点运算量降低1/5,只需要5.58 billion次浮点运算,但是精度并不弱。在ImageNet上可以达到72.9%的top-1准确率与91.2%的top-5准确率。

分类任务训练过程
在ImageNet上,1000类,160次epoch迭代训练,使用随机梯度下降算法,同时用起始的学习率0.1,decay power of 4,weight decay of 0.0005 and momentum of 0.9.
训练过程中,使用相应的训练技巧,包括: random crops, rotations, and hue, saturation, and exposure shifts
训练过程:初始用224*224大小的图像训练,之后改用448*448进行fine-tune,达到了top-1 准确率76.5%和top-5准确率93.3%
目标检测任务的训练过程
删掉最后的卷积层,只保留1024给3*3的卷积核,每个卷积核加一个1*1的卷积。
2.3 Stronger
作者提出一种机制,将分类任务与目标检测任务共同进行训练。
识别对象更多,且分层识别的结构Hierarchical classification。
Dataset combination and WordTree

Joint classification and detection
将分类任务与检测任务共同执行。
三、实验及结论


YOLO2通过一些改进明显提升了预测准确性,同时继续保持其运行速度快的优势。
