前面我们讨论了如何在神经网络中使用前向传播和反向传播来计算导数,但是反向传播算法含有许多细节,因此实现起来比较困难,并且它有一个不好的特性,很容易产生一些微妙的bug,当它与梯度下降或是其他算法一同工作时,看起来它确实能正常运行,并且代价函数J(θ)在每次梯度下降的迭代中也在不断减小。
在反向传播的实现中存在一些bug,但运行情况看起来确实不错,然而虽然J(θ)在不断减小,但是到了最后,你得到的神经网络,其误差将会比无bug的情况下高出一个量级,并且你很可能不知道你得到的结果是由bug导致的。
我们应该如何应对呢?
有一种思想叫做梯度检验,它能解决几乎所有这种问题。
建议每次在神经网络或是其他复杂模型中实现反向传播或者类似梯度下降算法时,都做梯度检验。
具体讲一下梯度检验,看下面这个例子:
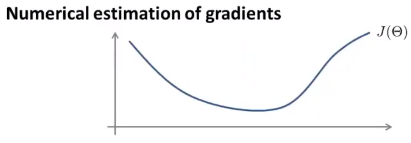
假设有一个代价函数J(θ),并且有这样一个θ值,且θ是一个实数,我们想估计函数在这一点上的导数:
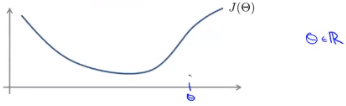
该点的导数就是图像在该点上切线的斜率,现在要从数值上来逼近它的导数,或者说这是一种从数值上来求近似导数的方法。
首先计算出θ+ε,然后再计算出θ-ε。现在要做的是,把这两个值对应的点用直线连起来:

红线的斜率就是所求的该点导数的近似值,它真正的导数是蓝色切线的斜率,看起来是一个不错的近似。数学上,红线的斜率等于该段的垂直高度除以该段的水平宽度:
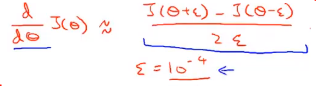
(上面那个好像叫双侧差分)
然后这个好像叫单侧差分:
双侧差分能得到更加准确的结果,所以通常用双侧差分。
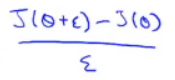
具体来说,你需要在Octave中执行这样的计算:

gradApprox就是该点导数的近似值。
在刚才的分析中,只考虑了θ是实数的情况,现在要考虑更普遍的情况,也就是当θ为向量参数的时候:

设θ是一个n维向量,它可能是神经网络中参数的展开式,所以θ是一个有n个元素的向量。
我们可以用类似的思想来估计所有的偏导数项:

上面这些等式能够从数值上去估算代价函数J关于任何参数的偏导数。
具体来说,一个代价函数关于第一个参数θ_1的偏导数可以通过增加J中的θ _1和减去J中的θ_1,最后除以2ε得到:
就像这样计算下去,直到θ_n为止。

具体地,你需要实现以下这些东西:

这是在Octave里为了估算导数所要实现的东西,假设i的值为1到n,这里的n是参数向量θ的维度,通常用它来计算展开形式的参数,因为θ是神经网络中所有参数的集合。
分析一下上面那个for循环:

这一步就是使所有的 thetaPlus 项都赋上 theta 值,而 thetaPlus(i) 还要加上ε。

这两行代码是对thetaMinus进行类似的操作。
最后计算出

就能近似地得到J(θ)关于θ_i这一点的偏导数:

我们在神经网络中使用这种方法时,使用了for循环来完成我们对神经网络中代价函数的所有参数的偏导数的计算,然后与我们在反向传播中得到的梯度进行比较:

DVec是我们从反向传播中得到的导数,我们知道反向传播是计算代价函数关于所有参数的导数或者偏导数的一种有效方法。
接下来通常要做的是验证这个计算出的导数 gradApprox 是否相等于,或者说在数值上非常地接近于用反向传播所计算出的导数 DVec。
如果这两种方法所计算出来的导数是一样的,或者说非常接近(只有几位小数的差距),那么就可以确信反向传播的实现是正确的。当我们把向量 DVec 用到梯度下降中,或者其他高级优化算法中时,就可以确信所计算的导数是正确的,那么代码也能够正确地运行,并且能很好地优化J(θ)。
最后,把整个过程总结在一起,整理一下如何实现数值上的梯度检验:
- 通过反向传播来计算 DVec。
DVec 可能会是矩阵展开的形式。
-
接下来要做的是计算出 gradApprox,即实现数值上的梯度检验。
-
然后需要确保 DVec 与 gradApprox 都能得出相似的值,即确保它们只有几位小数的差距。
-
最后也是最重要的一步,在使用你的代码进行学习或者说训练网络之前,关掉梯度检验,不再使用前面所讲的导数计算公式来计算导数 gradApprox。
这是因为梯度检验的代码是一个计算量非常大的,也是非常慢的计算导数的程序。
相对地,反向传播算法,即计算DVec的方法,它是一个高性能的计算导数的方法。
一旦你通过检验确定反向传播的实现是正确的,就应该关掉梯度检验,不再去使用它。
在运行算法之前,比如多次迭代的梯度下降或是多次迭代来训练分类器的高级优化算法,先禁用梯度检验代码。
具体地,如果在每次梯度下降迭代或者在每次代价函数的内循环里都运行一次梯度检验,程序就会变得非常慢,因为梯度检验代码比反向传播算法要慢很多,而反向传播算法,就是计算δ^ (4)、δ^ (3)、δ^ (2)等等的方法,它比梯度检验要快上很多。
这就是梯度检测,从数值上计算梯度的方法,它能验证反向传播算法的实现是正确的。当实现反向传播或者类似的梯度下降算法来计算复杂模型时,应该使用梯度检验来帮助确保代码是正确的。
参考资料:吴恩达机器学习系列课程
