继弄清楚索引底层基础架构之后,我们知道索引是帮助高效查询数据的数据结构,要写出高效查询的SQL语句,就要用到索引,以及我们要调优语句,这里就不得不说到执行计划explain。
首先我们来了解一下SQL的解析顺序,通过具体机制,我们知道,执行大致顺序是 from...on...join...where ...group by...having...select...order by...limit...,与我们编写顺序截然不同,通过了解执行顺序,我们就能更明确知道索引应当如何正确的编写。

一、explain释义

mysql官网,给出了explain每个字段的意义,这里我就不再详细说明,主要对索引优化的时候,我们需要着重关注的几个关键字是:type,possible_keys,key,key_len,Extra。

Extra释义:不在其他列显示的额外信息。
- using index,当前列使用索引,从衍生表中查询信息没有进行额外的去查询实际行,这种策略可被用在列是索引的一部分。
- using where,where从句中限定的行在其他表中相匹配,也就是需要回表查询。
- using tempporary,用到了临时表,一般在groupby或orderby的语句中。
- using filesort,需要额外的一次查找或排序,性能消耗最大。
- using join buff,读取数据在关联查询的时候,需要用到join缓存。
从extra的意思来看,当using index的时候,我们的查询语句命中索引,给我们的查询带来性能提升,有效的节约时间。而最糟糕的using filesort还需要一次额外的查找,导致性能损耗较大。
虽然索引,存在一些弊端,譬如:占用空间大,降低命令执行效率。但我们索引不仅降低了IO消耗,提升查询效率,还降低CPU使用率,使得排序简单,所以我们应当在查询时候,使用using index。
二、优化细则
从Mysql的索引底层原理我们知道,聚集索引和非聚集索引是由于存储引擎的差异,出现不同的效果。在索引类型中,存在着常见的几种索引类型:普通索引(index)、唯一索引(unique)、主键索引(primary key)、复合索引。其中主键索引是唯一索引,且要求主键不为NULL,复合索引中,以最佳左前缀规格,不可以跨列等要求。下面以实际的例子来演示细节。
1. 为查询加索引
当我们没有对student加上索引的时候,type为ALL,也就是进行全表扫描。

现在,我们给student主键加上索引,同时进行限定查询,可以用上了type=ref级别的索引。—— 总结:建立索引。

创建name和age列的组合索引,从第二条SQL语句可以看出,跨列查询,导致索引失效。—— 总结:组合索引不要跨列,尽量使用覆盖索引。
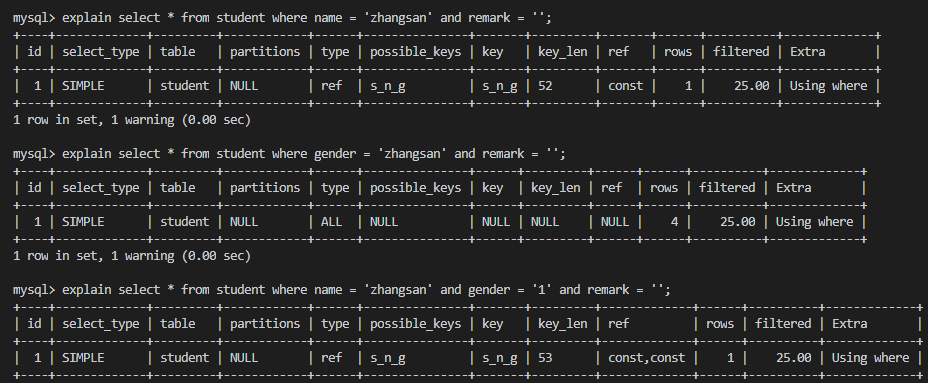
在索引列name上,进行任何运算,会导致无法树节点值无法命中索引,从而使索引失效。—— 总结:索引列上作运算会导致索引列失效。

对于范围查询的<>和!=,也是导致无法命中索引点,进行全表扫描,我们可以用 > < 进行替代。——总结:范围查询中不等于导致索引失效。

like查询的时候,我们有时候也不得不使用左右模糊匹配,可以尝试用es等服务,进行匹配优化。——总结:Like以通配符开头会导致索引失效。

索引匹配使用or无法命中索引。——总结:少用or,会导致索引失效。 
2. 为排序加索引;
Mysql的有两种排序方式,文件排序(using filesort)和扫描有序索引排序,Mysql能为排序和查询使用相同的索引。在Orderby的时候,以最佳左前缀匹配或常量为关键点,则Orderby能够使用索引。如下,三条sql均使用索引s_n_g。—— 总结:最佳左前缀或者常量匹配,则使用索引。
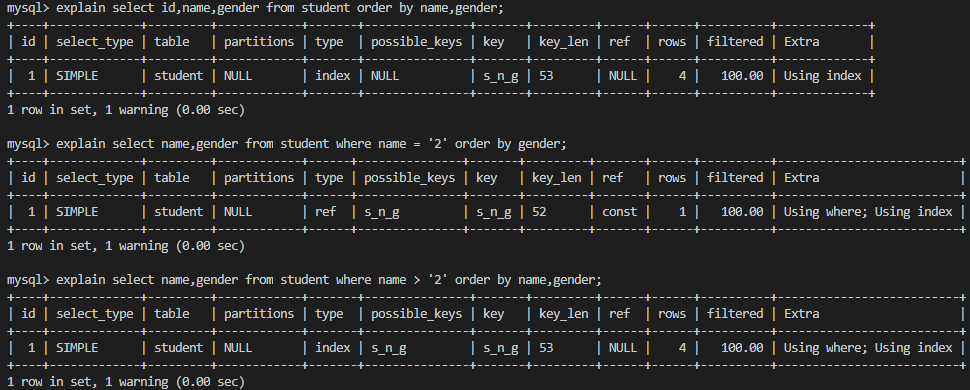
根据最佳左前缀原则,跨节点,排序顺序不一致,或者无关索引字段排序,都会导致一次额外的查询,即using filesort;其实这里有个概念即单路排序和双路排序。双路排序即进行两次IO,导致性能下降。在MySql4.1之后,开始使用单路排序,但是如果一次性取出的数据比较多,超过了sort_buffer存储上限,就会变成变成多路。
——总结:加大sort_buffer的值,且不要用select * 。

group by 则是先排序后分组,基本规则与orderby一置。
3. 多表关联优化;
其实根据我们的数据计算算放,对于3*4*5和5*4*3的结果是一样,但是以3*4的出来的数据仅仅只有12行,而5*4有20行,再进行关联匹配的时候,后者将会循环的次数变多。——总结:小表驱动大表。
explain索引优化仅是查询优化第一环,在MySql的设置中可以开启慢查询日志,记录慢查询SQL语句并进行分析。这次索引优化总结如下:
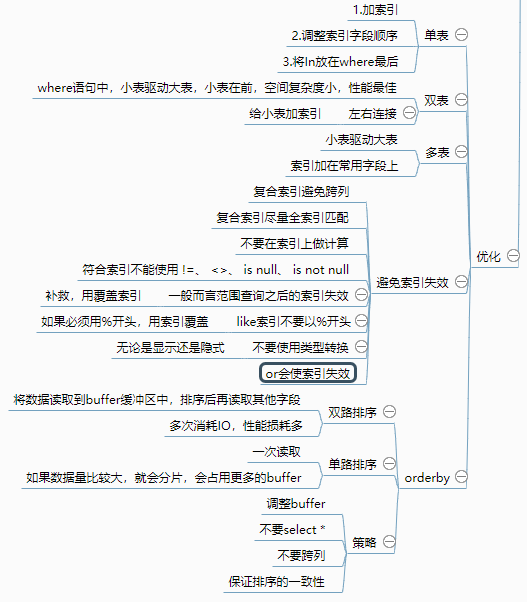
附录:


--学生表 create table student( id int not null auto_increment, name varchar(50) not null default '', gender char(1) not null default '0', primary key(id)); --课程表 create table course( id int not null auto_increment, name varchar(50) not null default '', primary key(id)); --选课表 create table course_c( id int not null auto_increment, studentid int not null default 0, courseid int not null default 0, primary key(id));
insert into student(name,gender) values('zhangsan','1'); insert into student(name,gender) values('lisi','0'); insert into student(name,gender) values('wangwu','1'); insert into student(name,gender) values('zhaoliu','0'); insert into course(name) values('C++'); insert into course(name) values('C#'); insert into course(name) values('JAVA'); insert into course_c(studentid,courseid) values(1,2); insert into course_c(studentid,courseid) values(2,3); insert into course_c(studentid,courseid) values(1,3); insert into course_c(studentid,courseid) values(3,1); insert into course_c(studentid,courseid) values(3,3); insert into course_c(studentid,courseid) values(3,2);