学习笔记|Pytorch使用教程35
本学习笔记主要摘自“深度之眼”,做一个总结,方便查阅。
使用Pytorch版本为1.2
生成对抗网络(GAN) 是什么?
如何训练GAN?
训练DCGAN实现人脸生成
一.生成对抗网络(GAN) 是什么?
- GAN:生成 对抗 网络—— 一种可以生成特定分布数据的模型
- (Generative Adversarial Nets》lan ] Goodfellow-2014

测试代码:
# -*- coding: utf-8 -*-
"""
# @file name : gan_inference.py
# @author : TingsongYu https://github.com/TingsongYu
# @date : 2019-12-05
# @brief : gan inference
"""
import os
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
import imageio
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
from tools.common_tools import set_seed
from torch.utils.data import DataLoader
from tools.my_dataset import CelebADataset
from tools.dcgan import Discriminator, Generator
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def remove_module(state_dict_g):
# remove module.
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict_g.items():
namekey = k[7:] if k.startswith('module.') else k
new_state_dict[namekey] = v
return new_state_dict
set_seed(1) # 设置随机种子
# config
path_checkpoint = os.path.join(BASE_DIR, "checkpoint_14_epoch.pkl")
image_size = 64
num_img = 64
nc = 3
nz = 100
ngf = 128
ndf = 128
d_transforms = transforms.Compose([transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
# step 1: data
fixed_noise = torch.randn(num_img, nz, 1, 1, device=device)
flag = 0
# flag = 1
if flag:
z_idx = 0
single_noise = torch.randn(1, nz, 1, 1, device=device)
for i in range(num_img):
add_noise = single_noise
add_noise = add_noise[0, z_idx, 0, 0] + i*0.01
fixed_noise[i, ...] = add_noise
# step 2: model
net_g = Generator(nz=nz, ngf=ngf, nc=nc)
# net_d = Discriminator(nc=nc, ndf=ndf)
checkpoint = torch.load(path_checkpoint, map_location="cpu")
state_dict_g = checkpoint["g_model_state_dict"]
state_dict_g = remove_module(state_dict_g)
net_g.load_state_dict(state_dict_g)
net_g.to(device)
# net_d.load_state_dict(checkpoint["d_model_state_dict"])
# net_d.to(device)
# step3: inference
with torch.no_grad():
fake_data = net_g(fixed_noise).detach().cpu()
img_grid = vutils.make_grid(fake_data, padding=2, normalize=True).numpy()
img_grid = np.transpose(img_grid, (1, 2, 0))
plt.imshow(img_grid)
plt.show()
输出:
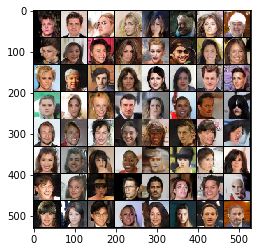

二.如何训练GAN?
训练目的
- 1.对于D:对真样本输出高概率
- 2.对于G:输出使D会给出高概率的数据


step1:训练D - 输入:真实数据加G生成的假数据
- 输出:二分类概率
step2:训练G
- 输入:随机噪声z
- 输出:分类概率一一D(G(z))

训练目的 - 1.对于D:对真样本输出高概率
- 2.对于G:输出使D会给出高概率的数据
- 《Generative Adversarial Nets》-2014

三.训练DCGAN实现人脸生成

数据: CelebA人脸数据
- 数据项目: http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
22万人脸矫正图:
- https://pan.baidu.com/s/1JDrI82vTjgFsmKQ0SPNtzA 密码:4Ig7
查看DCGAN结构:
from collections import OrderedDict
import torch
import torch.nn as nn
class Generator(nn.Module):
def __init__(self, nz=100, ngf=128, nc=3):
super(Generator, self).__init__()
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)
def initialize_weights(self, w_mean=0., w_std=0.02, b_mean=1, b_std=0.02):
for m in self.modules():
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, w_mean, w_std)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, b_mean, b_std)
nn.init.constant_(m.bias.data, 0)
class Discriminator(nn.Module):
def __init__(self, nc=3, ndf=128):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
def initialize_weights(self, w_mean=0., w_std=0.02, b_mean=1, b_std=0.02):
for m in self.modules():
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, w_mean, w_std)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, b_mean, b_std)
nn.init.constant_(m.bias.data, 0)
测试训练代码:
# -*- coding: utf-8 -*-
import os
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
import imageio
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
from tools.common_tools import set_seed
from torch.utils.data import DataLoader
from tools.my_dataset import CelebADataset
from tools.dcgan import Discriminator, Generator
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
set_seed(1) # 设置随机种子
# confg
data_dir = os.path.join(BASE_DIR, "..","..", "..", "data", "img_align_celeba_2k")
# data_dir = ""
out_dir = os.path.join(BASE_DIR, "..", "..", "log_gan")
if not os.path.exists(out_dir):
os.makedirs(out_dir)
ngpu = 0 # Number of GPUs available. Use 0 for CPU mode.
IS_PARALLEL = True if ngpu > 1 else False
checkpoint_interval = 10
image_size = 64
nc = 3
nz = 100
ngf = 128 # 64
ndf = 128 # 64
num_epochs = 20
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
real_idx = 1 # 0.9
fake_idx = 0 # 0.1
lr = 0.0002
batch_size = 64
beta1 = 0.5
d_transforms = transforms.Compose([transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # -1 ,1
])
if __name__ == '__main__':
# step 1: data
train_set = CelebADataset(data_dir=data_dir, transforms=d_transforms)
train_loader = DataLoader(train_set, batch_size=batch_size, num_workers=0, shuffle=True)
# show train img
flag = 0
# flag = 1
if flag:
img_bchw = next(iter(train_loader))
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(img_bchw.to(device)[:64], padding=2, normalize=True).cpu(), (1, 2, 0)))
plt.show()
plt.close()
# step 2: model
net_g = Generator(nz=nz, ngf=ngf, nc=nc)
net_g.initialize_weights()
net_d = Discriminator(nc=nc, ndf=ndf)
net_d.initialize_weights()
net_g.to(device)
net_d.to(device)
if IS_PARALLEL and torch.cuda.device_count() > 1:
net_g = nn.DataParallel(net_g)
net_d = nn.DataParallel(net_d)
# step 3: loss
criterion = nn.BCELoss()
# step 4: optimizer
# Setup Adam optimizers for both G and D
optimizerD = optim.Adam(net_d.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(net_g.parameters(), lr=lr, betas=(beta1, 0.999))
lr_scheduler_d = torch.optim.lr_scheduler.StepLR(optimizerD, step_size=8, gamma=0.1)
lr_scheduler_g = torch.optim.lr_scheduler.StepLR(optimizerG, step_size=8, gamma=0.1)
# step 5: iteration
img_list = []
G_losses = []
D_losses = []
iters = 0
for epoch in range(num_epochs):
for i, data in enumerate(train_loader):
############################
# (1) Update D network
###########################
net_d.zero_grad()
# create training data
real_img = data.to(device)
b_size = real_img.size(0)
real_label = torch.full((b_size,), real_idx, device=device)
noise = torch.randn(b_size, nz, 1, 1, device=device)
fake_img = net_g(noise)
fake_label = torch.full((b_size,), fake_idx, device=device)
# train D with real img
out_d_real = net_d(real_img)
loss_d_real = criterion(out_d_real.view(-1), real_label)
# train D with fake img
out_d_fake = net_d(fake_img.detach())
loss_d_fake = criterion(out_d_fake.view(-1), fake_label)
# backward
loss_d_real.backward()
loss_d_fake.backward()
loss_d = loss_d_real + loss_d_fake
# Update D
optimizerD.step()
# record probability
d_x = out_d_real.mean().item() # D(x)
d_g_z1 = out_d_fake.mean().item() # D(G(z1))
############################
# (2) Update G network
###########################
net_g.zero_grad()
label_for_train_g = real_label # 1
out_d_fake_2 = net_d(fake_img)
loss_g = criterion(out_d_fake_2.view(-1), label_for_train_g)
loss_g.backward()
optimizerG.step()
# record probability
d_g_z2 = out_d_fake_2.mean().item() # D(G(z2))
# Output training stats
if i % 10 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(train_loader),
loss_d.item(), loss_g.item(), d_x, d_g_z1, d_g_z2))
# Save Losses for plotting later
G_losses.append(loss_g.item())
D_losses.append(loss_d.item())
lr_scheduler_d.step()
lr_scheduler_g.step()
# Check how the generator is doing by saving G's output on fixed_noise
with torch.no_grad():
fake = net_g(fixed_noise).detach().cpu()
img_grid = vutils.make_grid(fake, padding=2, normalize=True).numpy()
img_grid = np.transpose(img_grid, (1, 2, 0))
plt.imshow(img_grid)
plt.title("Epoch:{}".format(epoch))
# plt.show()
plt.savefig(os.path.join(out_dir, "{}_epoch.png".format(epoch)))
# checkpoint
if (epoch+1) % checkpoint_interval == 0:
checkpoint = {"g_model_state_dict": net_g.state_dict(),
"d_model_state_dict": net_d.state_dict(),
"epoch": epoch}
path_checkpoint = os.path.join(out_dir, "checkpoint_{}_epoch.pkl".format(epoch))
torch.save(checkpoint, path_checkpoint)
# plot loss
plt.figure(figsize=(10, 5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses, label="G")
plt.plot(D_losses, label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
# plt.show()
plt.savefig(os.path.join(out_dir, "loss.png"))
# save gif
imgs_epoch = [int(name.split("_")[0]) for name in list(filter(lambda x: x.endswith("epoch.png"), os.listdir(out_dir)))]
imgs_epoch = sorted(imgs_epoch)
imgs = list()
for i in range(len(imgs_epoch)):
img_name = os.path.join(out_dir, "{}_epoch.png".format(imgs_epoch[i]))
imgs.append(imageio.imread(img_name))
imageio.mimsave(os.path.join(out_dir, "generation_animation.gif"), imgs, fps=2)
print("done")
输出:
[0/20][0/32] Loss_D: 1.8010 Loss_G: 8.0965 D(x): 0.4317 D(G(z)): 0.3617 / 0.0005
[0/20][10/32] Loss_D: 0.4453 Loss_G: 10.9394 D(x): 0.9243 D(G(z)): 0.0894 / 0.0001
[0/20][20/32] Loss_D: 0.0574 Loss_G: 60.2032 D(x): 0.9688 D(G(z)): 0.0000 / 0.0000
[0/20][30/32] Loss_D: 0.2744 Loss_G: 58.8632 D(x): 0.9741 D(G(z)): 0.0000 / 0.0000
[1/20][0/32] Loss_D: 0.0000 Loss_G: 58.4983 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[1/20][10/32] Loss_D: 0.0000 Loss_G: 58.6147 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[1/20][20/32] Loss_D: 0.0001 Loss_G: 58.4413 D(x): 0.9999 D(G(z)): 0.0000 / 0.0000
[1/20][30/32] Loss_D: 0.0000 Loss_G: 58.4523 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[2/20][0/32] Loss_D: 0.0000 Loss_G: 58.6710 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[2/20][10/32] Loss_D: 0.0002 Loss_G: 58.2906 D(x): 0.9998 D(G(z)): 0.0000 / 0.0000
[2/20][20/32] Loss_D: 0.0000 Loss_G: 57.9813 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[2/20][30/32] Loss_D: 0.0001 Loss_G: 58.5934 D(x): 0.9999 D(G(z)): 0.0000 / 0.0000
[3/20][0/32] Loss_D: 0.0000 Loss_G: 58.7628 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[3/20][10/32] Loss_D: 0.0001 Loss_G: 58.6454 D(x): 0.9999 D(G(z)): 0.0000 / 0.0000
[3/20][20/32] Loss_D: 0.0000 Loss_G: 58.2698 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[3/20][30/32] Loss_D: 0.0000 Loss_G: 58.5990 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[4/20][0/32] Loss_D: 0.0000 Loss_G: 58.1816 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[4/20][10/32] Loss_D: 0.0000 Loss_G: 58.1452 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[4/20][20/32] Loss_D: 0.0000 Loss_G: 58.4853 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[4/20][30/32] Loss_D: 0.0000 Loss_G: 58.4443 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[5/20][0/32] Loss_D: 0.0001 Loss_G: 58.3192 D(x): 0.9999 D(G(z)): 0.0000 / 0.0000
[5/20][10/32] Loss_D: 0.0000 Loss_G: 58.2698 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[5/20][20/32] Loss_D: 0.0000 Loss_G: 58.1979 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[5/20][30/32] Loss_D: 0.0000 Loss_G: 58.5056 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[6/20][0/32] Loss_D: 0.0000 Loss_G: 58.4166 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[6/20][10/32] Loss_D: 0.0000 Loss_G: 58.6855 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[6/20][20/32] Loss_D: 0.0000 Loss_G: 58.6179 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[6/20][30/32] Loss_D: 0.0000 Loss_G: 58.1543 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[7/20][0/32] Loss_D: 0.0000 Loss_G: 58.3324 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[7/20][10/32] Loss_D: 0.0000 Loss_G: 58.5175 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[7/20][20/32] Loss_D: 0.0000 Loss_G: 58.2488 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[7/20][30/32] Loss_D: 0.0000 Loss_G: 58.5782 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[8/20][0/32] Loss_D: 0.0000 Loss_G: 58.3713 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[8/20][10/32] Loss_D: 0.0000 Loss_G: 58.2332 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[8/20][20/32] Loss_D: 0.0000 Loss_G: 57.9329 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[8/20][30/32] Loss_D: 0.0000 Loss_G: 58.1448 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[9/20][0/32] Loss_D: 0.0000 Loss_G: 58.2986 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[9/20][10/32] Loss_D: 0.0000 Loss_G: 58.1899 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[9/20][20/32] Loss_D: 0.0000 Loss_G: 58.2553 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[9/20][30/32] Loss_D: 0.0000 Loss_G: 58.3208 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[10/20][0/32] Loss_D: 0.0000 Loss_G: 58.1400 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[10/20][10/32] Loss_D: 0.0000 Loss_G: 58.2545 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[10/20][20/32] Loss_D: 0.0000 Loss_G: 58.4556 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[10/20][30/32] Loss_D: 0.0000 Loss_G: 58.4457 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[11/20][0/32] Loss_D: 0.0000 Loss_G: 58.1351 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[11/20][10/32] Loss_D: 0.0000 Loss_G: 57.6035 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[11/20][20/32] Loss_D: 0.0000 Loss_G: 58.2834 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[11/20][30/32] Loss_D: 0.0000 Loss_G: 58.2691 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[12/20][0/32] Loss_D: 0.0000 Loss_G: 58.2969 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[12/20][10/32] Loss_D: 0.0000 Loss_G: 58.1955 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[12/20][20/32] Loss_D: 0.0000 Loss_G: 58.3466 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[12/20][30/32] Loss_D: 0.0000 Loss_G: 58.5687 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[13/20][0/32] Loss_D: 0.0000 Loss_G: 58.3651 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[13/20][10/32] Loss_D: 0.0000 Loss_G: 58.4334 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[13/20][20/32] Loss_D: 0.0001 Loss_G: 58.4723 D(x): 0.9999 D(G(z)): 0.0000 / 0.0000
[13/20][30/32] Loss_D: 0.0000 Loss_G: 58.0876 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[14/20][0/32] Loss_D: 0.0000 Loss_G: 58.0525 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[14/20][10/32] Loss_D: 0.0000 Loss_G: 58.1278 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[14/20][20/32] Loss_D: 0.0000 Loss_G: 58.2217 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[14/20][30/32] Loss_D: 0.0000 Loss_G: 58.3428 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[15/20][0/32] Loss_D: 0.0001 Loss_G: 58.3361 D(x): 0.9999 D(G(z)): 0.0000 / 0.0000
[15/20][10/32] Loss_D: 0.0000 Loss_G: 58.3699 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[15/20][20/32] Loss_D: 0.0000 Loss_G: 58.7551 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[15/20][30/32] Loss_D: 0.0000 Loss_G: 57.8655 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[16/20][0/32] Loss_D: 0.0000 Loss_G: 58.4348 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[16/20][10/32] Loss_D: 0.0000 Loss_G: 58.5398 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[16/20][20/32] Loss_D: 0.0000 Loss_G: 58.2676 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[16/20][30/32] Loss_D: 0.0000 Loss_G: 58.5138 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[17/20][0/32] Loss_D: 0.0000 Loss_G: 58.2509 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[17/20][10/32] Loss_D: 0.0000 Loss_G: 58.3572 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[17/20][20/32] Loss_D: 0.0000 Loss_G: 58.5628 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[17/20][30/32] Loss_D: 0.0000 Loss_G: 58.1255 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[18/20][0/32] Loss_D: 0.0000 Loss_G: 58.3526 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[18/20][10/32] Loss_D: 0.0000 Loss_G: 58.1962 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[18/20][20/32] Loss_D: 0.0000 Loss_G: 58.4394 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[18/20][30/32] Loss_D: 0.0000 Loss_G: 58.2893 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[19/20][0/32] Loss_D: 0.0000 Loss_G: 58.0923 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[19/20][10/32] Loss_D: 0.0000 Loss_G: 58.5348 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[19/20][20/32] Loss_D: 0.0000 Loss_G: 58.4733 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
[19/20][30/32] Loss_D: 0.0000 Loss_G: 58.0595 D(x): 1.0000 D(G(z)): 0.0000 / 0.0000
done

查看log_gan文件:




GAN的应用
- https://medium.com/@jonathan_hui/gan-some-cool-applications-of-gans-4c9ecca35900
GAN推荐
- github: https://github.com/nightrome/really- awesome-gan
