【论文阅读笔记】Focal Loss for Dense Object Detection
(一)论文地址:
https://arxiv.org/pdf/1708.02002.pdf
(二)核心思想:
这篇论文中作者探究了 one-stage 方法准确率较低的原因,并提出了一个新的 Loss 函数——Focal Loss 来解决 one-stage 方法中正负样本不均衡的问题;并且作者由此设计了一个简单高效的网络
RetinaNet,既保留了 one-stage 的速度快的特点,又保证了更高的准确率;
(三)One-stage 方法的问题:
one-stage 方法(如 YOLO,SSD 等)在不同大小的特征图上,使用不同大小和比率的 anchors 进行密集采样;这种方法获得的预选框远远多于 two-stage 的方法,导致的一个问题就是绝大多数预选框都是负样本(背景类),以至于即使分类器将所有预选框都分成背景,传统分类使用的交叉熵 Loss 依然会很低;
而 two-stage 方法由于使用了 RPN 网络,每次只选取一部分(通常为 256 个)样本参与到 Loss 的计算中,并且首先使用二分类(背景和非背景,即将物体小分类聚类成非背景类)做初步筛选,再通过分类器做分类,这样就很大程度上缓解了样本不均衡的问题;
(四)Focal Loss:
为了在 one-stage 方法中突出小样本,作者设计了一个 Focal Loss:
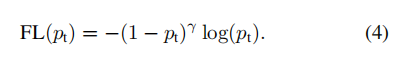
即在原本的交叉熵损失函数前加上了一个权重项: ;
其中:
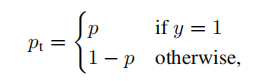
是某一类别 的输出概率, ;
由此带来的直观影响就是:
- 被正确分类时:
1.1 背景类的 Loss 大幅下降;
1.2 物体类的 Loss 正常下降; - 被错误分类时:
2.1 背景类的 Loss 正常下降;
2.2 物体类的 Loss 小幅下降;
因此训练时,更多注意力被放到了精细区分物体类上;
而 Focal Loss 也可以用另一个更复杂的定义:
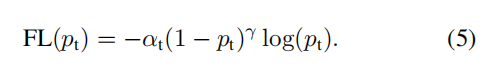
(五)参数选取:

作者在实验中发现,γ=2,α=0.25 时效果最好;
(六)RetinaNet:

RetinaNet 本质上是使用 Resnet 作为 Backbone 提取特征,使用 FPN 的方法提取 3 个特征层构成特征金字塔,再分别使用一个分类子网络和一个回归子网络进行预测;
(七)实验结果:
在原有 one-stage 基础上大大提高了检测的准确率;


