centos下Hadoop集群安装
hadoop集群最少需要三台机,因为hdfs副本数最少为3(或5、7、9,必须是单数)。这里我们使用四台机子进行搭建。
环境:
操作环境
- 主机操作系统版本:Windows 10, 64-bit (Build 18362) 10.0.18362;
- 虚拟机:VMware® Workstation 14 Pro;
- 虚拟机操作系统版本:Centos 7 64 位;
- Linux version: 3.10.0-514.el7.x86_64;
- Hadoop version:2.10.0
- jdk version:1.8.0_231(Hadoop3.0最低支持Java8)
集群准备
准备四台虚拟机,一台 master,三台 slaver。master 作为NameNode、DataNode、ResourceManager,slave 均作为DataNode、NodeManager。IP地址按如下分配:
master : 1.1.1.5
slave1 : 1.1.1.6
slave2 : 1.1.1.7
slave3 : 1.1.1.8
在/etc/host文件中添加相关参数,添加完后如下:
cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
1.1.1.5 master
1.1.1.6 slave1
1.1.1.7 slave2
1.1.1.8 slave3
0.0.0.0 locahost
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
配置Java环境变量
编辑/et/profile,在其中添加以下内容
#Java
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_23
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export PATH=$JAVA_HOME/bin:$PATH
#hadoop
export HADOOP_HOME=/root/hadoop-2.10.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
Tips:
PATH中设置JAVA_HOME/bin在前保证java命令搜索路径优先- 修改完后记得用
source /etc/profile命令使得刚才的环境变量生效
验证环境变量
#用which命令查找Java路径
> which java
/usr/lib/jvm/jdk1.8.0_23/bin/java
> which javac
/usr/lib/jvm/jdk1.8.0_23/bin/javac
安装Hadoop
Hadoop安装包获取
直接进入Hadoop官网下载binary文件,下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
或者通过wget命令下载: wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
Hadoop配置
-
通过
tar -zxvf hadoop-2.10.0.tar.gz将下载好的文件解压,也可以在命令后添加指定的目录将解压后的文档存放` tar -zxvf hadoop-2.10.0.tar.gz -C /root/’;解压后的目录位于/root/hadoop-2.10.0 -
将JAVA_HOME配置在Hadoop的运行环境中
> vi /root/hadoop-2.10.0/etc/hadoop/hadoop-env.sh在文件中添加以下变量
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_231 export HDFS_NAMENODE_USER="root" export HDFS_DATANODE_USER="root" export HDFS_SECONDARYNAMENODE_USER="root" export YARN_RESOURCEMANAGER_USER="root" export YARN_NODEMANAGER_USER="root" export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/root/hadoop-2.10.0/lib/native/" export HADOOP_COMMON_LIB_NATIVE_DIR="/root/hadoop-2.10.0/lib/native/" -
自行添加数据存储目录(需要自己mkdir)
-
NameNode 数据存放目录: /root/hadoop-2.10.0/local/data/hadoop/name
扫描二维码关注公众号,回复: 9785310 查看本文章
-
SecondaryNameNode 数据存放目录:
/root/hadoop-2.10.0/local/data/hadoop/secondary -
DataNode 数据存放目录:/root/hadoop-2.10.0/local/data/hadoop/data
-
临时数据存放目录: /root/hadoop-2.10.0/local/data/hadoop/tmp
Tips:
hadoop2和3端口不一样. Namenode ports: 50470 –> 9871, 50070 –> 9870, 8020 –> 9820 . Secondary NN ports: 50091 –> 9869, 50090 –> 9868 . Datanode ports: 50020 –> 9867, 50010 –> 9866, 50475 –> 9865, 50075 –> 9864记得备份
由于是虚拟机操作,建议在进行安装配置时的重要步骤前后保存快照,有利于快速恢复启动,以及文件修改时记得先cp 原文件 原文件.bak进行备份
-
修改 /root/hadoop-2.10.0/etc/hadoop/core-site.xml,设置Hadoop默认文件系统,添加自己的主机名或者IP,我的是
master,可通过hostname查看<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:8020</value> </property>设置HDFS的NameNode的格式化信息存储路径
<property> <name>hadoop.tmp.dir</name> <value>/root/hadoop-2.10.0/local/data</value> <description>缓存目录,可先自建mkdir</description> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> </configuration> -
修改 /root/hadoop-2.10.0/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>4</value> <description>HDFS文件系统Block的复制份数(伪分布配置时应为1)</description> </property> <property> <name>dfs.namenode.name.dir</name> <value>/root/hadoop-2.10.0/local/name</value> <description>本地文件系统DFS NameNode存放Name Ttable的路径</description> </property> <property> <name>dfs.namenode.data.dir</name> <value>/root/hadoop-2.10.0/local/data</value> <description>本地文件系统DFS DateNode存放数据Block的目录</description> </property> <property> <name>dfs.namenode.http-address</name> <value>master:50070</value> </property> <property> <name>dfs.namenode.rpc-address</name> <value>1.1.1.5:9000</value> </property> <property> <name>dfs.name.datanode.registration.ip-hostname-check</name> <value>false</value> </property> </configuration> -
修改 /root/hadoop-2.10.0/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.anme</name> <value>yarn</value> </property> <property> <name>mapreduce.admin.user.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> </configuration> -
修改/root/hadoop-2.10.0/etc/hadoop/yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <description>yarn web 访问地址</description> <value>master:8088</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME.HADOOP_CONF_DIR.CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration> -
配置从节点主机名,slaves文件配置(Hadoop3是workers),在/root/hadoop-2.10.0/etc/hadoop/slaves,如果没有配置主机名的情况下就使用IP:
slave1
slave2
slave3
ssh访问配置
-
安装sshd:
> yum install openssh-server -
修改ssh_config文件,
vi /etc/ssh/sshd_config后找到#Authentication,添加修改为
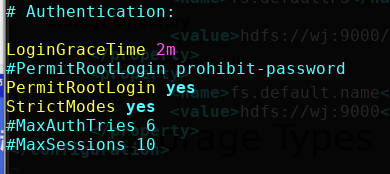
-
启动ssh服务:
> /etc/init.d/ssh start Starting ssh (via systemctl): ssh.service.
以上操作均需在四台机器上重复操作一遍,因为我是虚拟机,直接采用的方式是:
在一台配置好后,用克隆机器的方法克隆三台,再修改每台的IP地址。
- ssh免密钥登录(此步骤需要重复在四台机器操作)
> ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa > cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys > chmod 0600 ~/.ssh/authorized_keys > ssh-copy-id -i ~/.ssh/id_rsa.pub master #输密码过程已略,输入自己之前配置好的密码即可 > ssh-copy-id -i ~/.ssh/id_rsa.pub slave1 > ssh-copy-id -i ~/.ssh/id_rsa.pub slave2 > ssh-copy-id -i ~/.ssh/id_rsa.pub slave3 #测试 > ssh slave1 Last login: Sun Dec 8 23:04:01 2019 from master #测试文件传输 > rsync -av /root/hadoop-2.10.0/ slave:/root/hadoop-2.10.0/
启动Hadoop
-
格式化文件系统
./hdfs namenode -format -
启动NameNode和DataNode
./start-all.sh(用stop-dfs.sh命令可关闭)
启动ResourceManager和NodeManager
start-yarn.sh(命令stop-yarn可关闭)
这里直接执行start-all.sh一次性全部启动即可 -
master执行
jps看是否启动成功> jps 7465 Jps 5627 SecondaryNameNode 5150 NameNode 5443 ResourceManagerslave1:
> jps 18291 Jps 10084 DataNode 12334 NodeManager -
访问NameNode的web界面查看,访问地址是:http://ip:50070或者http://ip:9870(Hadoop2是50070,3则是9870)

5、查看datanodes
文件传输测试
hadoop fs -mkdir /testmaster
hadoop fs -touchz /testmaster/test.sh
或者直接在web页面中测试
YARN测试
- 查看web界面,访问地址是:http://ip:8088;这里我查看了Nodes的相关信息

- 或者用
./yarn node -list查看启动节点

错误总结
-
yarn启动后resourcemanager未启动,nodemanager则在slave启动成功,查看报错日志(http://1.1.1.5:50070/logs/yarn-allen-resourcemanager-master.log)如下

主要是Caused by: java.net.BindException: Port in use: 192.168.1.102:8088即端口被占用,
查看yarn配置文件yarn-site.xml
发现yarn.resourcemanager.webapp.address被我配置成了192.168.1.102:8088,是IP配置为本机IP,Windows端口占用比较多,还是改为虚拟机的较好
解决办法:
1)首先用stop-yarn.sh暂停yarn服务
2)再将yarn.resourcemanager.webapp.address的value换为master:8088
3)把修改后的yarn-site.xml分发到各个slave,替换原有文件> rsync -av /root/hadoop-2.10.0/etc/hadoop/yarn-site.xml slave1:/root/hadoop-2.10.0/etc/hadoop/yarn-site.xml > rsync -av /root/hadoop-2.10.0/etc/hadoop/yarn-site.xml slave2:/root/hadoop-2.10.0/etc/hadoop/yarn-site.xml > rsync -av /root/hadoop-2.10.0/etc/hadoop/yarn-site.xml slave3:/root/hadoop-2.10.0/etc/hadoop/yarn-site.xml4)最后
start-yarn.sh再次启动,jps显示节点启动成功,可在web页面访问
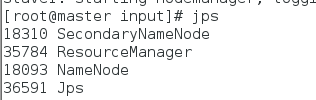
-
datanode和namenode启动成功,但是web页面不展示,datanode数量为零;
且后续停止启动服务后出现无法正常关闭datanode的现象
解决办法:
1)参考文章《HDFS 集群无法启动 DataNode 节点以及管理界面缺少 DataNode 节点的解决方法》,定位问题原因为
datanode(/root/hadoop-2.10.0/local/name/current/VERSION)
和namenode(/root/hadoop-2.10.0/local/data/dfs/namesecondary/current/VERSION)中的
VERSION文件的clusterID不一致引起,如下:其根本原因在于我们使用hdfs namenode -format命令刷新NameNode节点的格式后,会重新生成集群的相关信息,特别是clusterID,每次刷新都会生成一个新的clusterID;但是当我们在NameNode节点所在的虚拟机刷新格式后,并不会影响DataNode节点,也就是说,那2台配置DataNode节点的虚拟机上关于集群的信息并不会刷新,仍保留上一次(未刷新NameNode格式前)的集群信息,这就导致了NameNode节点和DataNode节点的clusterID不一致的情况
2)将两个VERSION文件修改为一致后,重启还是无法看到datanode于web界面
3)检查发现hdfs-site.xml中dfs.nmenode.datanode.registration.ip-hostname-check中的值应为false,我多写了一个符号,修改正常后,将文档分发到各个slaversync -av /root/hadoop-2.10.0/etc/hadoop/hdfs-site.xml slave2:/root/hadoop-2.10.0/etc/hadoop/hdfs-site.xml ``` 4)查看界面显示正常 -
安全模式
NameNode被启动后,文件系统会进入安全模式这种特殊状态,此状态下文件系统可读不可写。设置dfs.safemode.threshold.pct的值大于1时,NameNode被启动后将一直停留在安全模式;或者用HDFS管理用户(即hdfs用户)来实现$hadoop dfsadmin -safemode enter $hadoop dfsadmin -safemode get执行结果如下
Safe mode is ON退出则用
$hadoop dfsadmin -safemode leave
