前言
FP-growth是一个非常好的频繁项集发现算法,广泛应用于搜索引擎中(找出经常在一起出现的词对)相对于Apriori算法,FP-growth算法只用对数据库进行两次扫描,因此更适用于处理大数据。
本文以代码为主。关于FP-growth的理解,请参照这个网址:https://www.cnblogs.com/pinard/p/6307064.html
我自认是没有这个能力写的这么好的哈哈。
FP-growth算法主要分成两部分:FP树的构建和从FP树中挖掘频繁项集。本文主要介绍FP树的构建。
FP树的构建
这里,就假设大家已经了解了FP树是什么玩意了。
那么,就先从创建结点开始吧!
FP树结点
仔细观察上图,发现FP树的结点包括了以下信息:
- name:结点的名字。比如图中的null, A等
- count: 名字对应的计数值
- nodelink:同名字结点之间的link。比如图中的虚线箭头
- parent:父结点
- children:子节点
另外,还需要两个方法:
- inc方法:用来更新该结点的计数值(在向树中插入事务时)
- disp方法:将树以文本形式显示(对调试很有用)
话不多说,直接上代码~
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
self.count += numOccur
def disp(self, ind=1):
print(' ' * ind, self.name, self.count)
for child in self.children.values():
child.disp(ind+1)
构建FP树
前文说过,FP-growth算法一共需要遍历两次数据集,那么究竟是哪两次呢
第一步:遍历数据集,获得每个元素项的出现频率,并去掉不满足最小支持度的元素项,生成头指针表。打个比方,假设有以下事务:
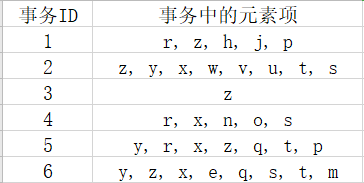
给定最小支持度为3,则生成的头指针表为:

你问还有一些元素项去哪了?它们都因为出现频率小于最小支持度而被删除了。
第二步:遍历数据集,根据头指针表,把数据集中的每一条事务中的元素按照其出现频率重新排序,并且删去没有出现在头指针表中的元素。再举个比方:

以事务1为例,首先元素项h, j, p未出现在头指针表中(也就是出现频率小于最小支持度),故被删除。而在头指针表中z排在r前面,因此处理后的事务1为z, r
第三步,就是将处理后的事务,挨个插入FP树中啦。
接下来就是代码部分。我不想像书上那样,把代码先放上来,再做阐释。我会先解释一下每个方法的作用,再给出代码,这样或许能好理解一点~不想看啰里啰唆的可以直接划到下面看代码哈
FP构建函数一共有三个方法:
方法1:createTree方法
createTree方法有以下几个功能
- 遍历数据集,构建头指针表headerTable和频繁项集freqItemSet
- 遍历数据集,根据头指针表对原事务数据集进行过滤和重排,对处理后的事务oderedItems, 调用updateTree方法来更新树。
代码如下:
# 传入的数据集其实是个字典,key值为事务, value值为数据集中该事务的频次
def createTree(dataSet, minSup=3):
headerTable = {}
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
# 遍历数据集,构建headerTabel。其key为元素,value为元素出现频次
for k in list(headerTable.keys()):
# 如果元素频次小于最小支持度,则删去
if headerTable[k] < minSup:
del headerTable[k]
freqItemSet = set(headerTable.keys())
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
# 拓展头指针表,第二项存储着指向该元素在树中第一次出现位置的指针
headerTable[k] = [headerTable[k], None]
# 建一棵空树
retTree = treeNode('Null Set', 1, None)
for tranSet, count in dataSet.items():
# localD存储过滤后的数据集
localD = {}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
# orderedItems存储过滤并重排序后的数据集
orderedItems = [v[0] for v in sorted(localD.items(),
key=lambda p: p[1], reverse=True)]
updateTree(orderedItems, retTree,
headerTable, count)
return retTree, headerTable
方法2:updateTree方法
(该部分最好一边画FP树再一边看)
updateTree是一个不断迭代的方法,它对orderedItem列表中第一个元素进行处理,最后删去该元素,然后再对新的orderedItem调用updateTree方法。
该函数首先测试第一个元素是否是作为子节点存在(从这里就看出为什么要对事务进行重排序了)。若是存在,则更新该元素的计数;若不存在,则创建一个treeNode并将其作为子节点添加到树中。
之后,头指针表也会更新,调用updateHeader方法。可能你会问为什么要更新头指针表?这个问题在updateHeader方法里面再解释哈。
def updateTree(items, inTree, headerTable, count):
# 如果第一个元素项作为子节点存在,则更新计数值
if items[0] in inTree.children:
inTree.children[items[0]].inc(count)
else:
# 否则创建一个新的子节点
inTree.children[items[0]] = treeNode(items[0], count, inTree)
# 如果在头指针表里该元素还没有指向的指针(即树上还没有出现该元素)
if headerTable[items[0]][1] is None:
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1],
inTree.children[items[0]])
# 如果事务中不止一个元素,则去掉第一个元素,再迭代
if len(items) > 1:
updateTree(items[1::], inTree.children[items[0]],
headerTable, count)
方法3:updateHeader方法
前面说过,头指针表headTable里面不仅存储着频繁元素,还存储着指向树中第一次出现该元素的指针。
同时,大家如果仔细观察FP树的话,会发现树中同一个元素会有虚线相连,结点类中也有对应的属性,叫nodelink。
所以,updateHeader方法的作用就是:
对于结点inTree.children[items[0]]和其对应元素, 此时在头指针表里该元素有指针存在(即树中已经有了该元素的存在),把这个元素所在结点和该元素上一次出现的结点“连”起来
至于怎么找到该元素上一次出现的结点嘛~
代码如下:
def updateHeader(nodeToTeset, targetNode):
while nodeToTeset.nodeLink is not None:
nodeToTeset = nodeToTeset.nodeLink
nodeToTeset.nodeLink = targetNode
简单的数据集
树的构建已经大功告成了,接下来我们只要创建一个数据集就可了。
注意,我们要导入的不是事务的列表,而是一个键为事务,键值为事务出现频次的数据字典。
因此我们需要对原始数据集进行一番处理
代码如下:
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
retDict[frozenset(trans)] = 1
return retDict
完整代码
下面贴出完整代码:
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
self.count += numOccur
def disp(self, ind=1):
print(' ' * ind, self.name, self.count)
for child in self.children.values():
child.disp(ind+1)
# 传入的数据集其实是个字典,key值为事务, value值为数据集中该事务的频次
def createTree(dataSet, minSup=3):
headerTable = {}
for trans in dataSet:
for item in trans:
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
# 遍历数据集,构建headerTabel。其key为元素,value为元素出现频次
for k in list(headerTable.keys()):
# 如果元素频次小于最小支持度,则删去
if headerTable[k] < minSup:
del headerTable[k]
freqItemSet = set(headerTable.keys())
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
# 拓展头指针表,第二项存储着指向该元素在树中第一次出现位置的指针
headerTable[k] = [headerTable[k], None]
# 建一棵空树
retTree = treeNode('Null Set', 1, None)
for tranSet, count in dataSet.items():
# localD存储过滤后的数据集
localD = {}
for item in tranSet:
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
# orderedItems存储过滤并重排序后的数据集
orderedItems = [v[0] for v in sorted(localD.items(),
key=lambda p: p[1], reverse=True)]
updateTree(orderedItems, retTree,
headerTable, count)
return retTree, headerTable
def updateTree(items, inTree, headerTable, count):
# 如果第一个元素项作为子节点存在,则更新计数值
if items[0] in inTree.children:
inTree.children[items[0]].inc(count)
else:
# 否则创建一个新的子节点
inTree.children[items[0]] = treeNode(items[0], count, inTree)
# 如果在头指针表里该元素还没有指向的指针(即树上还没有出现该元素)
if headerTable[items[0]][1] is None:
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1],
inTree.children[items[0]])
# 如果事务中不止一个元素,则去掉第一个元素,再迭代
if len(items) > 1:
updateTree(items[1::], inTree.children[items[0]],
headerTable, count)
def updateHeader(nodeToTeset, targetNode):
while nodeToTeset.nodeLink is not None:
nodeToTeset = nodeToTeset.nodeLink
nodeToTeset.nodeLink = targetNode
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
retDict[frozenset(trans)] = 1
return retDict
simpDat = loadSimpDat()
initSet = createInitSet(simpDat)
myFPtree, myHeaderTab = createTree(initSet, 3)
myFPtree.disp()
生成的结果如下:
Null Set 1
z 5
r 1
x 3
s 2
t 2
y 2
r 1
t 1
y 1
x 1
s 1
r 1
其中每个缩进表示所处的树的深度
FP树的构建到此结束。至于怎么从树中挖掘频繁项集,请听下回分解~
本文的代码来自《机器学习实战》的第12章
