摘要
由于PCA对噪声和离群点敏感,很多后来提出的鲁棒PCA都是利用L2范数求均值后得到的中心化数据,但是由于在先前的目标函数的步骤里面是使用的L1范数,所以这样是不对了,这篇文章是基于损失函数利用L2,1范数和Schatten-p范数正则项。在损失函数中使用L_2,1可以移除噪声和离群点,此外,相比利用核范数近似矩阵的秩,Schatten-p范数的效果更好。因此相比其他,这个算法的性能自然更好。
引言
探索和利用(exploiting)高维数据的低维结构是很多领域研究的热点话题,如:image processing(图像处理), web relevancy data analysis and search(网页相关数据分析和检索), bioinformatics(生物信息学), and so on(to name a few)。原始数据在实际应用中通常处在几千维甚至上万维度的空间内,为了缓解维度的困扰,研究者们 utilize(利用)低维子空间,稀疏基,低秩流行能够推导出低本征维度这一事实进行数据近似。最广泛使用的降维方法就是PCA。PCA利用SVD找到一个低维近似子空间来构造低秩近似。但是标准的PCA对于噪声和离群点是脆弱的(brittle)PCA is brittle with grossly cor- rupted variables or observations.随后便提出了很多改进的PCA算法来增强鲁棒性。
encouraging results(可喜的结果)
More precisely(更准确的说)
In effect(实际上)
假定一个矩阵D,D=A+E,其中A是观测对象的低秩矩阵,E数据中的噪声代表噪声
PCA尝试优化通过寻找一个秩k来近似A:
![]()
不同的p范数代表着不同的鲁棒PCA算法
当p=1时,就是RPPGC,这时候E也是一个具有稀疏分布的噪声矩阵。就像图一中的(a),通过L1范数最小化(即:L0范数极小化的凸函数)就可以使一些没有必要的项的系数为0;

当p=1,2时,就是RPOP,E只有在一小部分行的值是非0,如图一(b)所示。由于L21范数使L20范数的凸近似,能够导致行稀疏进而移除噪声和离群点。
rank(A)用来恢复污染数据,由于秩最小化是一个非凸问题,所以常常用秩的凸近似核函数来代替秩的最小化,
但是由利用核范数近似优化模型没有考虑极大地抑制重构数据的奇异值
这时候就提出了一个新的近似方法:Schatten-p范数能够将奇异值抑制在一个较小的范围,而且更加能够近似秩。

现在提出的鲁棒PCA方法在很多情况下表现出很好的鲁棒想,但是他们忽略了最优均值计算问题,实际上,这些鲁棒PCA方法都基于一个假设:数据的均值为0。但是,在大多情况下数据地均值不为0的,所以当去去除最优均值后,PCA是近似给定数据矩阵的最好方法。因此,PCA变为:

其中b为一个均值向量,1是一个全1的列向量。
除此在外,将在标准PCA中基于L2范数的均值应用到在鲁棒PCA中是不正确的,因此,在考虑到最优均值的情况下,可以减小上述提到的鲁棒PCA的重构误差。
为了移除噪声和离群点,极大的抑制奇异值,计算最优均值,基于L21和Schatten-p范数正则化提出了一个优化模型。

但是上述L20和秩都是NP如果![]() 足够行稀疏,最小化2,0范数和2,1范数的结果是一样的,此外,schattenp能够将奇异值极大的一直在一个很小的范围内(0<p<1),
足够行稀疏,最小化2,0范数和2,1范数的结果是一样的,此外,schattenp能够将奇异值极大的一直在一个很小的范围内(0<p<1),
为什么Schattenp相比核范数效果更好,做出来以下解释:

于是就可以得到以下近似:
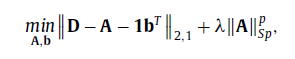
后续便是一些优化过程,这个让我想到,由于Schatten-p范数比核范数能够更好地近似秩,那么先前用秩来近似的方法岂不是都可以用Schatten-p范数来替换,哈哈哈哈。
