1、处理模式
数据处理目前有两种常见的处理模式,一种是批处理,一种是流处理。批处理的代表是Spark,流处理的代表则是Storm,两者能兼容的代表则是Flink。在Kafka的不断更新迭代中,Kafka Stream已经在流处理中占据一席之地了。借此机会,先科普一下这两种处理模式。
什么是批处理、流处理?在这里我们提出一个关键词
- 量化
对于处理中心,如果处理的事情是可以量化的,什么是量化?比如信息的大小、处理的时间,那么我们就可以这个称之为批处理,官方给出的说法是:有界、持久、大量;相反,如果处理的事情无法量化,就像富士康流水线一样,你不知道这条流水线上有多少工作、要花多少时间,这些是没有办法做计算和统计的,我们称之为流处理,官方给出的说法是:无界、实时;
对此,我们就能够想到了,批处理一般用于离线统计。比如算出一篇文章中有多少种单词,每种单词出现的次数。
而流处理一般用于实时统计,比如对于每一个时间点,近五分钟内该商品在某宝、某东上的点击量是多少。
当然,不管是批处理,还是流处理,都不在本文的详细概述范畴之内,如果大家有兴趣深入了解,可以关注我之后会写的Flink(先立个flag,逼自己一把,也希望大家能够监督哈)。
回到主题,Kafka的设计是基于流式Stream的,你大可把Kafka想象成一个驿站,,每天(每秒)都会有无数的人流(消息)从这里歇脚(写入/读取)。就目前来看,光是做到这一点的,就已经是非常优秀了。
为什么这么说呢?要像Kafka这样支持高吞吐、低延迟的消息中间件,我们可以从这个设计里挖掘出许多问题。类比于计算机网络中的数据传输,需要考虑Kafka在发送消息的时候,如下的一些问题:
- 对所有主题topic进行轮询监听,生产者producer处理发送数据的请求响应
- 数据的序列化serializer与反序列化unserializer校对
- 主题topic下的数据分区partiton处理
- 传输的时候数据的丢失、乱序
- 集群状态下的ISR集合内数据存储同步
在考虑到解决如上问题的同时,还要保证性能不受很大的影响,那么Kafka中的生产者Proudcer是怎么实现的呢?
2、消息发送
生产者Producer对客户端发来的消息发送请求处理流程如下
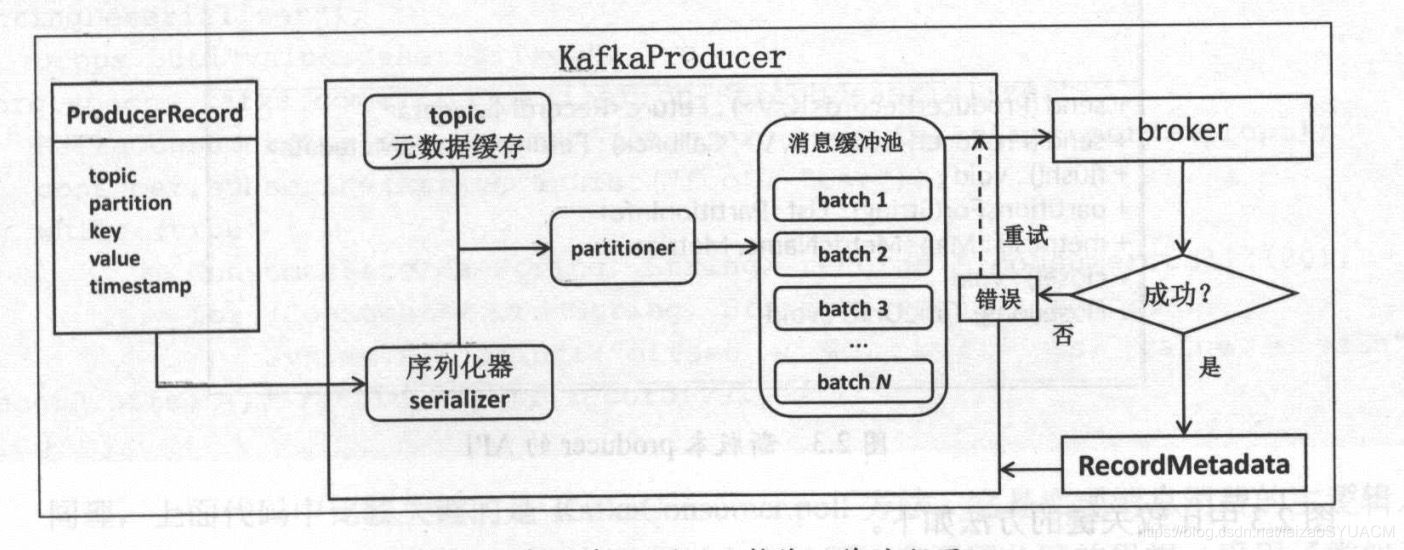
首先会将消息封装成一个ProducerRecord对象,然后进行发送。在进入KafkaProducer中的第一步,就是将消息进行序列化serializer,接着结合本地缓存的元数据信息建立目标分区partition,最后写入缓存区buffer。在此同时,会有一个专门的Sender I/O线程负责将缓冲池memory中的消息分批次发送给给Kafka broker。
在ProducerRecord对象中,有一个key字段,如果这个key非空,则KafkaProducer中的分区器partitioner会根据key的哈希值来选择目标分区,如果这个key值为空,则分区器partitioner会使用轮询的方式确认目标分区。
这样一来,具有相同key的所有消息都会被路由到相同的分区中。这么做有一点好处,就是可以利用局部性原理,将某些生产者Producer发送的消息固定发送到相同机架上分区从而减少网络传输的开销。
接下来我们讨论一下部分细节吧
(1)发送方式和返回结果
- 同步发送
- 异步发送
Kafka生产者Producer同时支持两种消息发送模式,并且返回的结果都是两个变量,一个是数据变量,另一个是异常变量。如果消息发送成功,那么数据变量非空,异常变量为空;相反,如果消息发送失败,那么数据变量为空,异常变量非空。
消息失败的时候,返回的异常变量的值也可以分为可重试异常和不可重试异常两类。
- 可重试异常,顾名思义,就是在Prouducer中设置里重试了次数,多重试几次,消息就能发送成功。如果在重试次数内消息仍然没有发送成功,就需要Producer另外做自行处理。可重试异常之所以会出现,除了网络瞬时故障这种并不常见的情况之外,碰到得最多的可能就是Kafka正在选主了。
我们知道,Kafka中只有leader replica对外提供服务,如果leader replica挂掉了,在一定的短时间内,需要在ISR集合中进行重新一轮的leader选举,那么这个时候Kafka是无法对外提供服务的,因此消息发送会返回异常,相当于告诉你,我们现在正在内部选举,过一会我们选好了leader重试一次吧。
- 不可重试异常,就是无论重试多少次都是无法成功的。通常是消息序列化失败了,或者要发送的消息太大了,超过了参数设置的大小。
(2)参数控制
- acks (控制producer生产消息的持久性)
- buffer.memory (指定producer端用于缓存消息的缓冲池大小)
- compression.type (设置producer端是否压缩消息)
- retries (producer端发送消息时重试的次数)
- batch.size (producer端用于缓存消息)
- linger.ms (producer端发送消息的时延)
- max.request.size (producer端能够发送的最大消息大小)
- request.timeout.ms (producer端处理请求最大响应时间)
(3)关闭资源
因为producer在运行的时候,会占用系统资源,比如会创建线程、申请内存,创建多个Socket连接等等。所以在程序结束的时候,需要关闭producer。关闭的时候有两种:
- 带参数timeout,在timeout时间内允许producer将未处理完的消息处理好,如果超出timeout,不管producer是否已经处理完所有的消息,都会强行退出;
- 不带任何参数,会一直等待producer将所有未处理完的消息都处理好,通常被称为优雅的关闭退出;
