作为R语言的初学者,你是否也曾觉得看书看教程觉得so easy,但到了实际操作却无从下手了呢?没(hu)关(you)系(ni)……那都是假的,哈哈哈,好啦,我们还是多多实战才是硬道理。
本文引用的数据集 - - Titanic Machine Learning from Disaster(被誉为五大最适合数据分析练手项目之一)就非常适合我们进行练手,当然我们接下来要讲的并不是“you jump, I jump”的感人故事,而是“you dead I survived”的分析故事,那么我们就要看看到底怎样的乘客才能成为幸运女神的宠儿呢?
1. 读取数据

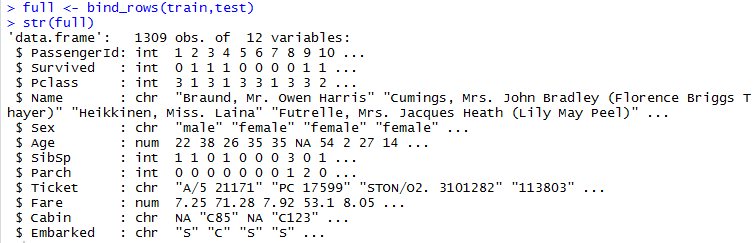
训练集train与测试集test有11变量是相同的,而唯一不同的地方是test里面没有Survived变量,为了方便接下来的数据处理,我们将两数据集进行合并。
2. 加载所需程序包
- library(dplyr)
- library(stringr)
- library(VIM)
- library(mice)
- library(ggplot2)
- library(caret)
- library(randomForest)
3. 缺失值探索
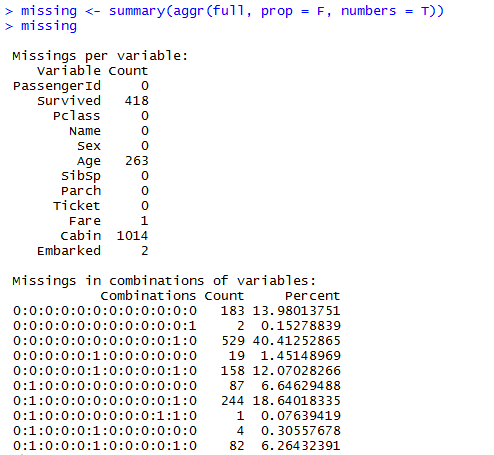
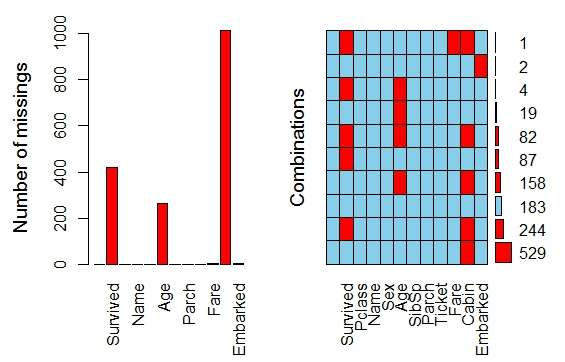
合并后的full数据集里Survived变量含有481个缺失值(test集里不含有Survived变量,因此合并后使得full集有481个缺失值),Age变量有263个缺失值(多重插补法处理),Fare变量有1个缺失值(均值填补),Embarked变量有2个缺失值(众数填补),Cabin变量含有1014个缺失值(缺失值太多,删除处理)。
4. 缺失值处理

我们观察到Age变量的缺失值高达263个,用均值替代或者删除都会对结果产生较大的影响,因此我们将通过mice包对Age变量的缺失值进行插补,结果如上图所示,插补后Age均值为29.57岁,最小的为0.17岁,最老的为80岁。

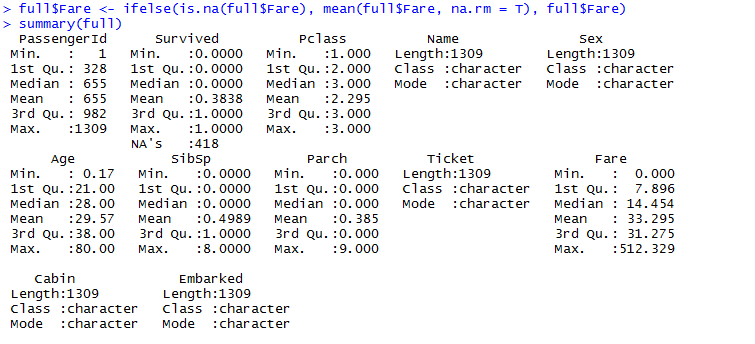
对Embarked变量和Fare变量的缺失值进行填补,因为只有两个和1个的缺失值,因此我们考虑用众数(Embarked变量为chr)和均值(Fare变量为int)的方式直接填补。Embarked变量的众数为S,因此直接用S替代缺失值,结果如上图所示。Fare变量在用均值填补时,要注意的一点是在进行均值处理是时,”na.rm = TRUE”不能忘,不然得出来的均值会是na值。最后我们用summary看一下处理过后的数据,除了Survived变量的481个缺失值外,其他的变量都漂漂亮亮的了,当然Cabin变量的1014个缺失值并没有进行处理,因为待会我们会直接删掉它,结果如下图所示。
5. 特征值选取与描述性分析

- Title VS Survived
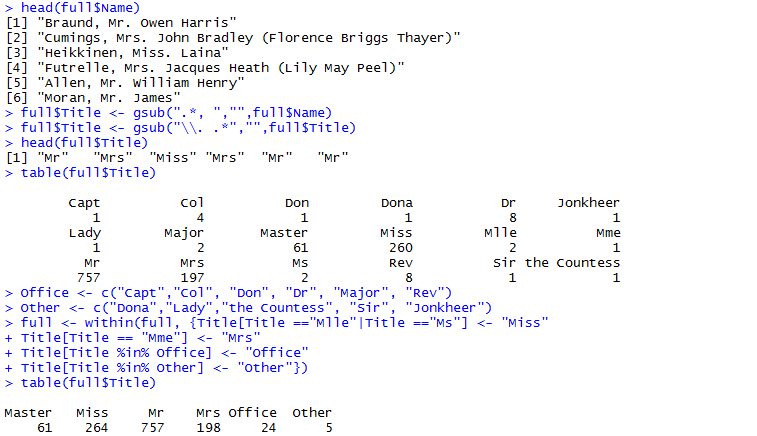
Title变量是从Name变量中提取出来的,因为我们观察到Name变量除了中间的称呼外,没有太多的共同点,对分析没有太多价值,因此将称呼提取出来进行分析。结果如下图所示,可以发现不同的Title的幸存率还是有很大差距。

- Pclass,Sex,Pclass&Sex VS Survived


Pclass变量对幸存率的影响还是挺大的,一等舱和二等舱的幸存率挺高的,而三等舱的死亡率却高达 75 %,由此我们不得不说“天下武功,唯富不破”,我们还是要努力赚钱啊!
Sex变量对幸存率的影响就不用说太多了,女士优先,因此我们可以看到女性的死亡率只有25%左右,而男性的死亡率却高达75%。
分析完Pclass变量与Sex变量对幸存率的影响,小文突发奇想,会不会幸存率比较高的女性都在一二等舱呢?因此将Pclass与Sex进行合并分析,结果还是很令人满意的,一二等舱的女士幸存率都接近100%,连死亡率较高的三等舱的女士生存率也接近50%。
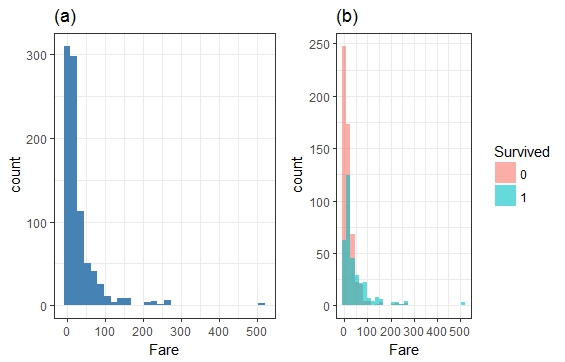
- Fare VS Survived
(a)图是Fare变量的分布,可以看到大部分人的票价都在100以下,其中还有很大一部分是免费上船的;(b)图是Fare变量对幸存率的影响,可以看到票价高的乘客幸存率也较高,这与上面Pclass对幸存率的影响趋势一致。
- Age VS Survived
Age变量的分布比较广,由 0岁到80岁不等,直接分析没太大意义,因此将其分为未成年人与成年人两组进行统计分析。结果表明,未成年人的幸存率比成年人的高。


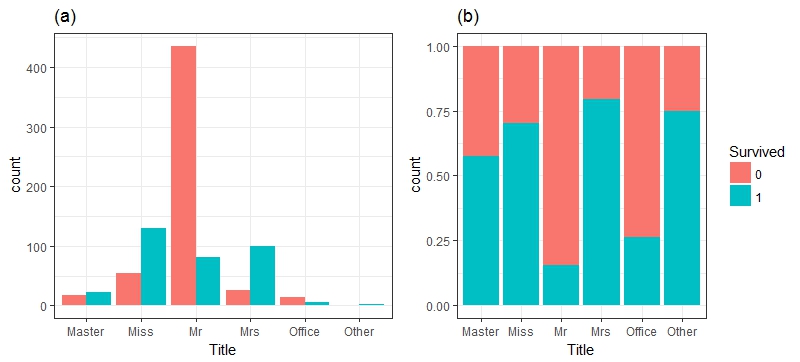
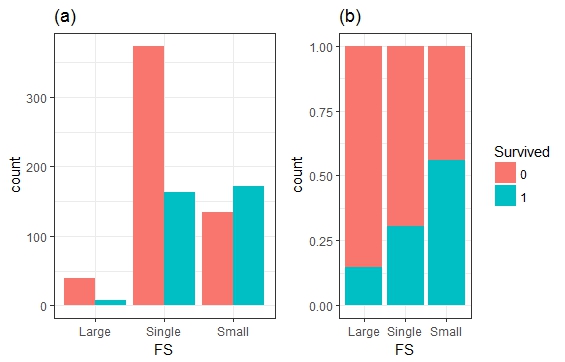
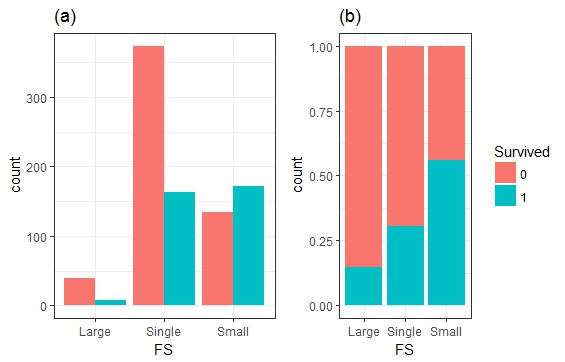
- Familysize(FS)VS Survived
一开始小文对数据集中的SibSp变量与Parch变量搞不清楚,怒小文的英语水平有限,查看了字典之后才发现原来是兄弟姐妹老婆孩子的意思,那好办,我们建立一个新的变量,命名为Fsize,Fsize = SibSp + Parch + 1,并将家庭的人数分为单身,小家庭,大家庭进行分组统计分析。结果表明,家庭人数对幸存率的影响还是比较明显的。

- Embarked VS Survived


6. 建模
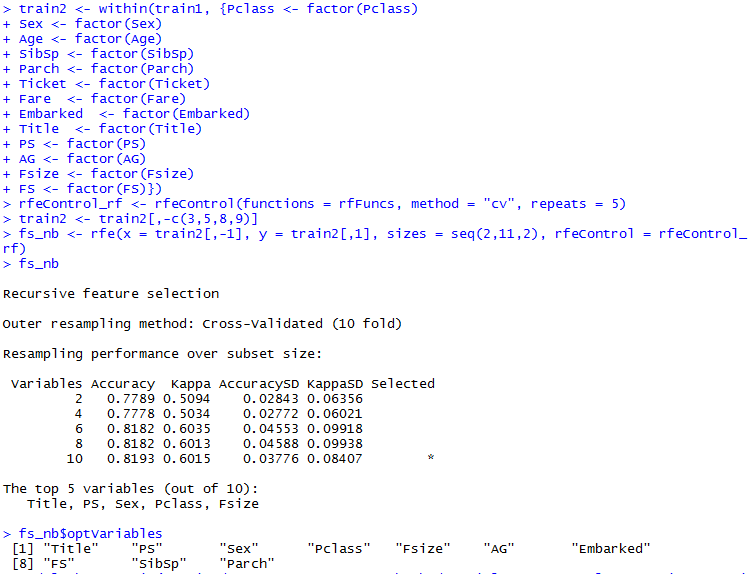
通过上述的特征值提取与描述性分析,我们知道Title,Pclass,Sex,PS,FS,AG,Fare,Emarked变量对幸存率的影响还是比较明显的,因此在建模预测之前,先用randomForest进行特征变量分析,看看其中哪些变量影响力更大。(在特征变量分析之前,需将所有的变量转化为因子变量,不然会出错)
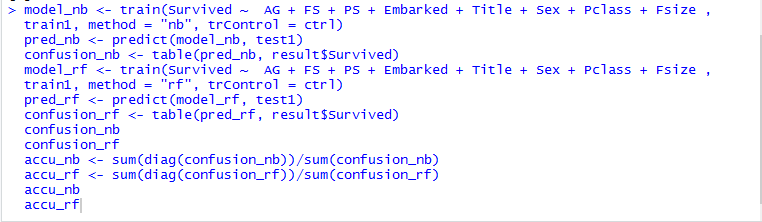

特征变量提取之后,分别用朴素贝叶斯算法与随机森林算法对测试集进行预测,结果表明,朴素贝叶斯分类器的正确率为98.80%,在418个测试集中只有5个乘客预测错误,分别是两个未幸存者错误归类到幸存者当中,3个幸存者错误归类到未幸存者中;而随机森林分类器的预测正确率比朴素贝叶斯要低一点点,为97.61%,有10个乘客预测错误,其中有4个未幸存者错误归类到幸存者当中,6个幸存者错误归类到未幸存者中。
总体而言两个模型表现得还不错,有兴趣的读者可以继续探讨各种变量之间的关系,塑造更多有意思的变量组合,提高正确率,不说了,小文要赶紧把结果上传到kaggle,看看能不能排得上号……