Zeichenfolgen und Tupel sind sehr ähnlich und können nicht einfach geändert werden, sobald sie definiert sind
Wenn Sie es ändern müssen, können Sie Slices und Verkettungen verwenden,
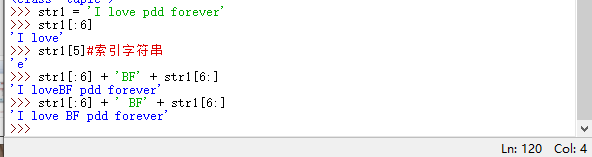
sodass die alte Zeichenfolge str1 noch vorhanden ist und nach der Zuweisung überschrieben wird. Der Garbage Collection-Mechanismus von Python entfernt Zeichenfolgen ohne Tags.

Integrierte Methoden für Strings
| Methode | Bedeutung |
|---|---|
| profitieren() | Ändern Sie das erste Zeichen der Zeichenfolge in Großbuchstaben und alle anderen Zeichen in Kleinbuchstaben |
| casefold () | Alle Buchstaben der neuen Zeichenfolge werden klein geschrieben |
| Mitte (Breite, Füllzeichen = '') | Gibt eine neue Zeichenfolge zentriert zurück (Breite <= Zeichenfolgenlänge, neue Zeichenfolge = ursprüngliche Zeichenfolge; Breite> Zeichenfolgenbreite, alle Zeichen werden zentriert, links und rechts werden mit den durch den Parameter fillchar angegebenen Zeichen gefüllt). |
| count (sub [, start [, end]]) | Gibt die Anzahl der nicht überlappenden Vorkommen von Sub in der Zeichenfolge zurück. Die optionalen Parameter Start und Ende werden verwendet, um die Start- und Endpositionen anzugeben |
| Enden mit (Suffix [, Start [, Ende]]) | Wenn die Zeichenfolge mit dem durch das Suffix angegebenen Teilstring endet, geben Sie True zurück, andernfalls False. Die optionalen Parameter start und end werden verwendet, um die Start- und Endpositionen anzugeben |
| expandtabs ([tabsize = 8]) | Geben Sie eine neue Zeichenfolge mit Leerzeichen zurück, um Tabulatoren zu ersetzen. Wenn der Parameter tabsize nicht angegeben ist, ist standardmäßig 1 Tabulator = 8 Leerzeichen |
| find (sub [, start [, end]]) | Suchen Sie die Teilzeichenfolge in der Zeichenfolge und geben Sie den niedrigsten Indexwert der Übereinstimmung zurück. Die optionalen Parameter start und end werden verwendet, um die Start- und Endpositionen anzugeben. Wenn die Teilzeichenfolge nicht übereinstimmt, geben Sie -1 zurück |
| join (iterable) | Verketten Sie mehrere Zeichenfolgen und geben Sie eine neue Zeichenfolge zurück. Verwenden Sie die Zeichenfolge, die diese Methode aufruft, als Trennzeichen und fügen Sie sie in die Mitte jeder Zeichenfolge ein, die durch den iterierbaren Parameter angegeben wird. |
| encode (encoding = 'utf-8', error = 'strict') | Codieren Sie die Zeichenfolge in dem durch den Codierungsparameter angegebenen Codierungsformat. Der Fehlerparameter gibt die Lösung an, wenn ein Codierungsfehler auftritt: Der Standardwert "strict" bedeutet, dass bei Auftreten eines Fehlers ein UnicodeEncodeError ausgelöst wird. Andere verfügbare Parameterwerte sind'ignore ',' replace 'und' xmlcharrefreplace '. |
| Format (* args, ** kwargs) | Geben Sie eine neue formatierte Zeichenfolge zurück und verwenden Sie zum Ersetzen Positionsparameter (Argumente) und Schlüsselwortargumente (kwargs) |
| format_map (Zuordnung) | Geben Sie eine neue formatierte Zeichenfolge zurück und ersetzen Sie sie durch Zuordnungsparameter (Zuordnung) |
| Index (sub [, start [, end]]) | Suchen Sie die Teilzeichenfolge in der Zeichenfolge und geben Sie den niedrigsten Indexwert der Übereinstimmung zurück. Die optionalen Parameter start und end werden verwendet, um die Start- und Endpositionen anzugeben. Wenn die Teilzeichenfolge nicht übereinstimmt, wird eine ValueError-Ausnahme ausgelöst |
| isalnum () | Wenn die Zeichenfolge mindestens ein Zeichen enthält und alle Zeichen Buchstaben oder Zahlen sind, wird True zurückgegeben, andernfalls False |
| isalpha () | Wenn die Zeichenfolge mindestens ein Zeichen enthält und alle Zeichen Buchstaben sind, wird True zurückgegeben, andernfalls False |
| isascii () | Wenn alle Zeichen in der Zeichenfolge ASCII sind, wird True zurückgegeben, andernfalls wird False zurückgegeben. Der ASCII-Zeichencodierungsbereich ist U + 0000 ~ U + 007F, und die leere Zeichenfolge ist ebenfalls ASCII |
| isdecimal () | Wenn die Zeichenfolge mindestens ein Zeichen enthält und alle Zeichen Dezimalzahlen sind, wird True zurückgegeben, andernfalls wird False zurückgegeben |
| isdigit () | Wenn die Zeichenfolge mindestens ein Zeichen enthält und alle Zeichen Zahlen sind, wird True zurückgegeben, andernfalls False |
| Kennung () | Wenn die Zeichenfolge eine gültige Python-Kennung ist, wird True zurückgegeben, andernfalls wird False zurückgegeben. Rufen Sie keyword.iskeyword (s) auf, um zu überprüfen, ob die Zeichenfolge eine reservierte Kennung ist (z. B. "if" oder "for"). |
| ist tiefer() | Wenn die Zeichenfolge mindestens einen englischen Groß- und Kleinschreibung enthält und diese Buchstaben alle in Kleinbuchstaben geschrieben sind, geben Sie True zurück, andernfalls False |
| isnumerisch () | Wenn die Zeichenfolge mindestens ein Zeichen enthält und alle Zeichen Zahlen sind, wird True zurückgegeben, andernfalls False |
| druckbar () | Wenn die Zeichenfolge druckbar ist, gibt sie True zurück, andernfalls False |
| isspace () | Wenn die Zeichenfolge mindestens ein Zeichen enthält und alle Zeichen Leerzeichen sind, geben Sie True zurück, andernfalls False |
| Liste () | Wenn es sich bei der Zeichenfolge um eine Zeichenfolge mit dem Titel handelt (alle Wörter beginnen mit Großbuchstaben, die restlichen Buchstaben sind Kleinbuchstaben), geben Sie True zurück, andernfalls False |
| isupper () | Wenn die Zeichenfolge mindestens einen englischen Groß- und Kleinschreibung enthält und diese Buchstaben alle in Großbuchstaben geschrieben sind, geben Sie True zurück, andernfalls False |
| join (iterable) | Verketten Sie mehrere Zeichenfolgen und geben Sie eine neue Zeichenfolge zurück. Verwenden Sie die Zeichenfolge, die diese Methode aufruft, als Trennzeichen und fügen Sie sie in die Mitte jeder Zeichenfolge ein, die durch den iterierbaren Parameter angegeben wird. |
| hell (Breite) | Geben Sie eine neue Zeichenfolge mit linksbündigen Zeichen zurück (Breite <= Zeichenfolgenlänge, neue Zeichenfolge = ursprüngliche Zeichenfolge; Breite> Zeichenfolgenbreite, alle Zeichen sind linksbündig und die rechte Seite ist mit den durch den Parameter fillchar angegebenen Zeichen gefüllt). |
| niedriger() | Geben Sie eine neue Zeichenfolge zurück, bei der alle englischen Buchstaben in Kleinbuchstaben konvertiert sind |
| lstrip (Zeichen = Keine) | Geben Sie eine neue Zeichenfolge mit entfernten Leerzeichen zurück. Mit dem Parameter chars können Sie die zu entfernende Zeichenfolge angeben |
| Partition (sep) | Suchen Sie nach dem durch den Parameter sep in der Zeichenfolge angegebenen Trennzeichen. Wenn es gefunden wird, geben Sie ein 3-Tupel zurück ('das Teil vor dem September', 'sep', 'das Teil nach dem September'). Wenn es nicht gefunden wird, geben Sie ('Originalzeichenfolge' zurück ',' ',' ') |
| removeprefix (Präfix) | Wenn die durch den Präfixparameter angegebene Präfix-Teilzeichenfolge vorhanden ist, wird eine neue Zeichenfolge mit entferntem Präfix zurückgegeben. Wenn sie nicht vorhanden ist, wird eine Kopie der ursprünglichen Zeichenfolge zurückgegeben |
| entferntes Suffix (Suffix) | Wenn durch den Suffix-Parameter eine Suffix-Teilzeichenfolge angegeben wird, wird eine neue Zeichenfolge mit entferntem Suffix zurückgegeben. Wenn diese nicht vorhanden ist, wird eine Kopie der ursprünglichen Zeichenfolge zurückgegeben |
| ersetzen (alt, neu, count = -1) | 返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串;count 参数指定替换的次数,默认是 -1,表示替换全部 |
| rfind(sub[, start[, end]]) | 在字符串中自右向左查找 sub 子字符串,返回匹配的最高索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,返回 -1 |
| rindex(sub[, start[, end]]) | 在字符串中自右向左查找 sub 子字符串,返回匹配的最高索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,抛出 ValueError 异常 |
| rjust(width, fillchar=’ ') | 返回一个字符右对齐的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符右对齐,左侧使用 fillchar 参数指定的字符填充) |
| rpartition(sep) | 在字符串中自右向左搜索sep参数指定的分隔符,如果找到,返回一个 3 元组 (‘在sep前面的部分’, ‘sep’, ‘在sep后面的部分’);如果未找到,则返回 (’’, ‘’, ‘原字符串’) |
| rsplit(sep=None, maxsplit=-1) | 将字符串自右向左进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit 参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制 |
| rstrip(chars=None) | 返回一个去除右侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串 |
| split(sep=None, maxsplit=-1) | 将字符串进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制 |
| splitlines(keepends=False) | 将字符串按行分割,并将结果以列表的形式返回;keepends 参数指定是否包含换行符,True 是包含,False 是不包含 |
| startswith(prefix[, start[, end]]) | 如果存在 prefix 参数指定的前缀子字符串,则返回 True,否则返回 False;可选参数 start 和 end 用于指定起始和结束位置;prefix 参数允许以元组的形式提供多个子字符串 |
| strip(chars=None) | 返回一个去除左右两侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串 |
| swapcase() | 返回一个大小写字母翻转的新字符串 |
| title() | 返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串。 |
| translate(table) | 返回一个根据 table 参数转换后的新字符串;table 参数应该提供一个转换规则(可以由 str.maketrans(‘a’, ‘b’) 进行定制,例如 “FishC”.translate(str.maketrans(“FC”, “15”)) -> ‘1ish5’) |
| upper() | 返回一个所有英文字母都转换成大写后的新字符串 |
| zfill(width) | 返回一个左侧用 0 填充的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符右对齐,左侧使用 0 进行填充) |
capitalize():将字符串的第一个字符修改为大写,其他字符全部改为小写

casefold() :新字符串的所有字母变为小写

center(width, fillchar=’ ') : 返回一个字符居中的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符居中,左右使用 fillchar 参数指定的字符填充)

count(sub[, start[, end]]): 返回 sub 在字符串中不重叠的出现次数,可选参数 start 和 end 用于指定起始和结束位置

endswith(suffix[, start[, end]]): 如果字符串是以 suffix 指定的子字符串为结尾,那么返回 True,否则返回 False;可选参数 start 和 end 用于指定起始和结束位置

expandtabs([tabsize=8]) :返回一个使用空格替换制表符的新字符串,如果没有指定 tabsize 参数,那么默认 1 个制表符 = 8 个空格

find(sub[, start[, end]]) :在字符串中查找 sub 子字符串,返回匹配的最低索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,返回 -1

index(sub[, start[, end]]) :在字符串中查找 sub 子字符串,返回匹配的最低索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,抛出 ValueError 异常
join(iterable) :连接多个字符串并返回一个新字符串;以调用该方法的字符串作为分隔符,插入到 iterable 参数指定的每个字符串的中间;
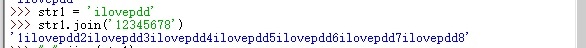
join()方法代替加号来拼接字符串
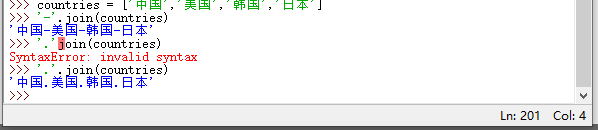
istitle():如果字符串是标题化字符串(所有的单词都是以大写开始,其余字母均小写)则返回 True,否则返回 False

lstrip(chars=None):返回一个去除左侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串
rstrip(chars=None):返回一个去除右侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串

partition(sep) 在字符串中搜索 sep 参数指定的分隔符,如果找到,返回一个 3 元组 (‘在sep前面的部分’, ‘sep’, ‘在sep后面的部分’);如果未找到,则返回 (‘原字符串’, ‘’, ‘’)
replace(old, new, count=-1) 返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串;count 参数指定替换的次数,默认是 -1,表示替换全部

split(sep=None, maxsplit=-1) 将字符串进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制

strip(chars=None) 返回一个去除左右两侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串


swapcase() 返回一个大小写字母翻转的新字符串

translate(table) 返回一个根据 table 参数转换后的新字符串;table 参数应该提供一个转换规则(可以由 str.maketrans(‘a’, ‘b’) 进行定制,例如 “FishC”.translate(str.maketrans(“FC”, “15”)) -> ‘1ish5’)

Task
0. 还记得如何定义一个跨越多行的字符串吗(请至少写出两种实现的方法)?
【1】三重引号字符串
【2】转义字符\n

【3】
>>> str3 = ('待卿长发及腰,我必凯旋回朝。'
'昔日纵马任逍遥,俱是少年英豪。'
'东都霞色好,西湖烟波渺。'
'执枪血战八方,誓守山河多娇。'
'应有得胜归来日,与卿共度良宵。'
'盼携手终老,愿与子同袍。')
1. 三引号字符串通常我们用于做什么使用?
三引号字符串不赋值的情况下,通常当作跨行注释使用
2. file1 = open ('C: \ windows \ temp \ readme.txt', 'r') bedeutet, die Textdatei "C: \ windows \ temp \ readme.txt" im schreibgeschützten Modus zu öffnen, aber tatsächlich Diese Aussage wird einen Fehler melden. Wissen Sie warum? Wie würden Sie es ändern?
"\ T" und "\ r" stehen für "horizontale Registerkarte (TAB)" bzw. "Wagenrücklauf"
>>> file1 = open(r'C:\windows\temp\readme.txt', 'r')
3. Es gibt eine Zeichenfolge: str1 = '<a href="http://www.fishc.com/dvd" target="_blank"> Verpackung von Fisch-C-Ressourcen', wie die Teilzeichenfolge extrahiert wird: 'www.fishc. com '
>>> str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'
>>> str1[16:29]

4. Wenn Sie eine negative Zahl als Indexwert für den Schneidevorgang verwenden, können Sie das Ergebnis gemäß der dritten Frage korrekt visuell erkennen?
>>> str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'
>>> str1[-45:-32]

5. Es ist die Zeichenfolge in Frage 3. Was wird im folgenden Satz angezeigt?
>>> str1[20:-36]
'fishc'
6. Es wird gesagt, dass nur Fischöl mit einem IQ von mehr als 150 diese Zeichenfolge entsperren kann (zurückgesetzt zu einer aussagekräftigen Zeichenfolge): str1 = 'i2sl54ovvvb4e3bferi32s56h; $ c43.sfc67o0cm99'

(Ich weiß nicht viel, ?????)
7. Bitte schreiben Sie einen Code für die Passwortsicherheitsprüfung: check.py (in Gedanken ...)
# 密码安全性检查代码
#
# 低级密码要求:
# 1. 密码由单纯的数字或字母组成
# 2. 密码长度小于等于8位
#
# 中级密码要求:
# 1. 密码必须由数字、字母或特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)任意两种组合
# 2. 密码长度不能低于8位
#
# 高级密码要求:
# 1. 密码必须由数字、字母及特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)三种组合
# 2. 密码只能由字母开头
# 3. 密码长度不能低于16位
