
Bei der täglichen Entwicklung der Internet-Back-End-Schnittstelle, unabhängig davon, ob Sie C, Java, PHP oder Golang verwenden, können Sie nicht vermeiden, dass Sie MySQL, Redis und andere Komponenten aufrufen müssen, um Daten abzurufen. Möglicherweise müssen Sie auch eine RPC-Fernbedienung ausführen ruft an oder ruft eine andere erholsame Apis an. Am Ende dieser Aufrufe wird im Wesentlichen das TCP-Protokoll für die Übertragung verwendet. Dies liegt daran, dass das TCP-Protokoll im Transportschichtprotokoll die Vorteile einer zuverlässigen Verbindung, einer erneuten Fehlerübertragung und einer Überlastungskontrolle bietet und daher derzeit häufiger als UDP verwendet wird.
Ich glaube, Sie müssen gehört haben, dass TCP auch einige Mängel aufweist, dh der altmodische Overhead ist etwas größer. In verschiedenen technischen Blogs wird jedoch gesagt, dass die Kosten groß oder klein sind und es selten vorkommt, dass keine spezifische quantitative Analyse angegeben wird. Gern geschehen, das ist alles Unsinn mit wenig Ernährung. Nachdem ich über meine tägliche Arbeit nachgedacht habe, möchte ich besser verstehen, wie viel Overhead ist. Wie lange dauert es, den Aufbau einer TCP-Verbindung zu verzögern, wie viele Millisekunden oder wie viele Mikrosekunden? Kann es überhaupt eine grobe quantitative Schätzung geben? Natürlich gibt es viele Faktoren, die den Zeitverbrauch von TCP beeinflussen, wie z. B. den Verlust von Netzwerkpaketen. Heute teile ich nur die relativ hohe Inzidenz verschiedener Situationen, denen ich in meiner Arbeitspraxis begegnet bin.
Ein normaler TCP-Verbindungsaufbau
Um den zeitaufwändigen Aufbau einer TCP-Verbindung zu verstehen, müssen wir den Verbindungsaufbau im Detail verstehen. Im vorherigen Artikel "Illustrated Linux Network Packet Receiving Process" haben wir vorgestellt, wie Datenpakete auf der Empfangsseite empfangen werden. Das Datenpaket kommt vom Absender und erreicht die Netzwerkkarte des Empfängers über das Netzwerk. Nachdem die Empfängernetzwerkkarte das Datenpaket an den RingBuffer DMAs gesendet hat, verarbeitet der Kernel es durch Hard-Interrupt, Soft-Interrupt und andere Mechanismen (wenn Benutzerdaten gesendet werden, werden sie schließlich an die Socket-Empfangswarteschlange gesendet und aktivieren den Benutzerprozess). .
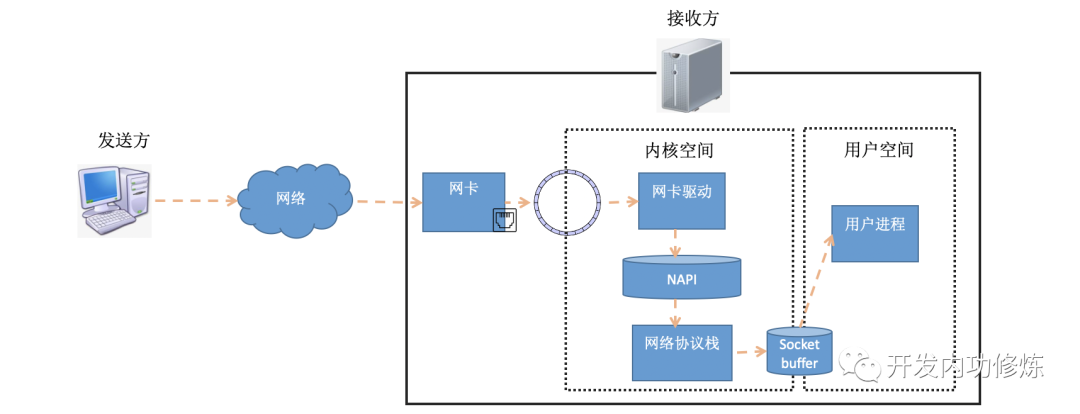
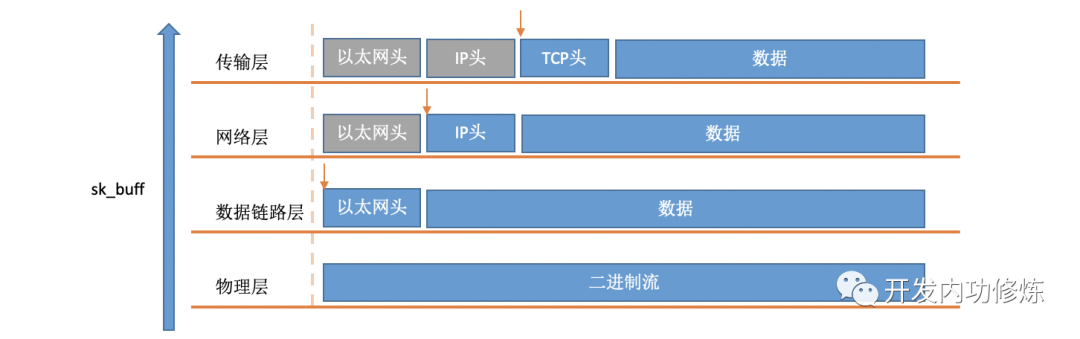
Wenn in weichen Interrupts ein Paket vom Kernel aus dem RingBuffer entnommen wird, wird es durch eine struct sk_buffStruktur im Kernel dargestellt (siehe Kernelcode include/linux/skbuff.h). Das Datenelement sind die empfangenen Daten. Wenn der Protokollstapel Schicht für Schicht verarbeitet wird, können die Daten, um die sich jede Protokollschicht kümmert, gefunden werden, indem der Zeiger so geändert wird, dass er auf verschiedene Datenpositionen zeigt.
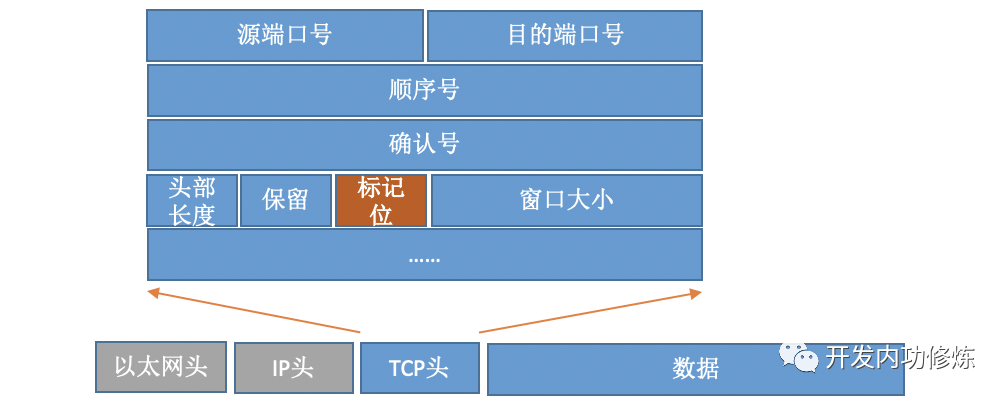
Für TCP-Protokollpakete enthält der Header wichtige Feldflags. Wie nachfolgend dargestellt:
Durch Setzen verschiedener Flags werden TCP-Pakete in SYNC, FIN, ACK, RST und andere Typen unterteilt. Der Client verwendet das Connect-System, um den Befehlskern aufzurufen und SYNC, ACK und andere Pakete zu senden, um eine TCP-Verbindung mit dem Server herzustellen. Auf der Serverseite können viele Verbindungsanforderungen empfangen werden, und der Kernel muss auch einige zusätzliche Datenstrukturen verwenden - halbverbundene Warteschlangen und vollständig verbundene Warteschlangen. Werfen wir einen Blick auf den gesamten Verbindungsprozess:
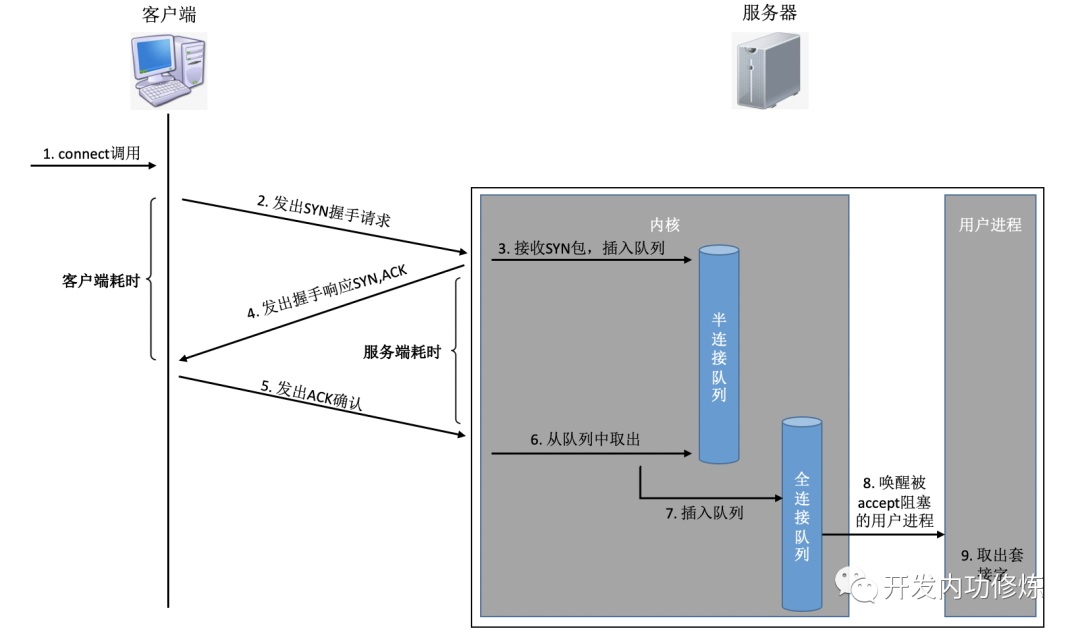
Lassen Sie uns in diesem Verbindungsprozess kurz den Zeitaufwand für jeden Schritt analysieren
Der Client sendet das SYNC-Paket: Der Client sendet SYN im Allgemeinen über den Verbindungssystemaufruf, der den zeitaufwändigen CPU-Overhead des lokalen Systemaufrufs und des Soft-Interrupts beinhaltet
SYN wird an den Server übertragen : SYN wird von der Netzwerkkarte des Clients gesendet und beginnt, "Berge und Meere sowie durch das Meer von Menschen zu überqueren ..." Dies ist eine Netzwerkübertragung über große Entfernungen
Der Server verarbeitet das SYN-Paket: Der Kernel empfängt das Paket über einen Soft-Interrupt, stellt es in die Warteschlange für Halbverbindungen und sendet dann eine SYN / ACK-Antwort. CPU zeitaufwändiger Overhead
SYC / ACK wird an den Client übertragen : Nachdem das SYC / ACK vom Server gesendet wurde, überquert es auch viele Berge und möglicherweise viele Meere zum Client. Noch eine lange Netzwerkwanderung
Der Client verarbeitet SYN / ACK: Nachdem der Client-Kernel das Paket empfangen und das SYN verarbeitet hat, wird es für einige Minuten von der CPU verarbeitet und sendet dann ein ACK. Das Gleiche gilt für den Overhead der Soft-Interrupt-Verarbeitung
ACK wird an den Server übertragen : Wie das SYN-Paket wird es erneut über fast dieselbe Entfernung übertragen. Noch eine lange Netzwerkwanderung
Der Server empfängt die ACK: Der Serverkernel empfängt und verarbeitet die ACK und nimmt dann die entsprechende Verbindung aus der Semi-Verbindungswarteschlange und stellt sie in die vollständige Verbindungswarteschlange. Ein Soft-Interrupt-CPU-Overhead
Aufwecken des serverseitigen Benutzerprozesses: Der Benutzerprozess, der durch den Systemaufruf accpet blockiert wird, wird aktiviert, und die hergestellte Verbindung wird aus der vollständigen Verbindungswarteschlange entfernt. CPU-Overhead eines Kontextwechsels
Die obigen Schritte können einfach in zwei Kategorien unterteilt werden:
Die erste Kategorie besteht darin, dass der Kernel die CPU zum Empfangen, Senden oder Verarbeiten verwendet, einschließlich Systemaufrufen, weichen Interrupts und Kontextwechseln. Ihre zeitaufwändige ist im Grunde ein paar von uns. Informationen zum spezifischen Analyseprozess finden Sie unter " Wie hoch ist der Overhead eines Systemaufrufs?". " , " Wie viel CPU frisst dich sanft unterbrechen? " ", " Prozess / Thread-Schalter können Sie viel CPU verbrauchen? " Diese drei Artikel.
Der zweite Typ ist die Netzwerkübertragung. Wenn das Paket von einem Computer gesendet wird, durchläuft es verschiedene Netzwerkkabel und verschiedene Switch-Router. Daher ist die zeitaufwändige Netzwerkübertragung viel höher als die CPU-Verarbeitung dieser Maschine. Je nach Entfernung des Netzwerks reicht es im Allgemeinen von einigen ms bis zu einigen hundert ms. .
1 ms entspricht 1000 us, daher ist die Netzwerkübertragungszeit etwa 1000-mal höher als der Dual-End-CPU-Overhead und kann sogar 100000-mal höher sein. Daher kann beim normalen TCP-Verbindungsaufbau im Allgemeinen die Netzwerkverzögerung berücksichtigt werden. Eine RTT bezieht sich auf die Verzögerungszeit eines Pakets von einem Server zu einem anderen Server. Aus globaler Sicht benötigt das durch die TCP-Verbindung eingerichtete Netzwerk daher etwa drei Übertragungen plus einen geringen CPU-Overhead für beide Parteien, der insgesamt etwas größer als das 1,5-fache der RTT ist. Aus Sicht des Clients betrachtet der Kernel die Verbindung jedoch als erfolgreich hergestellt, solange das ACK-Paket gesendet wird. Wenn der Client den zeitaufwändigen Aufbau der TCP-Verbindung zählt, sind daher nur zwei Übertragungen erforderlich, dh eine RTT dauert etwas länger. (Aus serverseitiger Sicht gilt das Gleiche. Vom Beginn des SYN-Paketempfangs bis zum Empfang der ACK gibt es in der Mitte auch eine zeitaufwändige RTT.)
2. Abnormale Situation, wenn eine TCP-Verbindung hergestellt wird
Wie Sie im vorherigen Abschnitt sehen können, entspricht aus Sicht des Clients unter normalen Umständen die Gesamtzeit, die eine TCP-Verbindung benötigt, ungefähr der Zeit, die eine Netzwerk-RTT benötigt. Wenn alles so einfach ist, denke ich, dass mein Teilen unnötig sein wird. Die Dinge sind nicht immer so schön, es wird immer Unfälle geben. In einigen Fällen kann dies zu einer längeren Netzwerkübertragungszeit während der Verbindung, einem erhöhten CPU-Verarbeitungsaufwand oder sogar zu einem Verbindungsfehler führen. Lassen Sie uns nun über die verschiedenen Lücken und Hürden sprechen, denen ich online begegnet bin.
1) Der Client Connect-Systemaufruf nimmt die Zeit außer Kontrolle
Normalerweise dauert ein Systemaufruf einige Sekunden (Mikrosekunden). In dem Artikel "Verfolgung des Mörders, der die Server-CPU erschöpft hat!" Stieß ein Server des Autors zu diesem Zeitpunkt auf eine Situation. Ein bestimmter Betriebs- und Wartungsstudent gab an, dass die Service-CPU nicht ausreichte und erweitert werden müsse. Die Serverüberwachung zu diesem Zeitpunkt ist wie folgt:
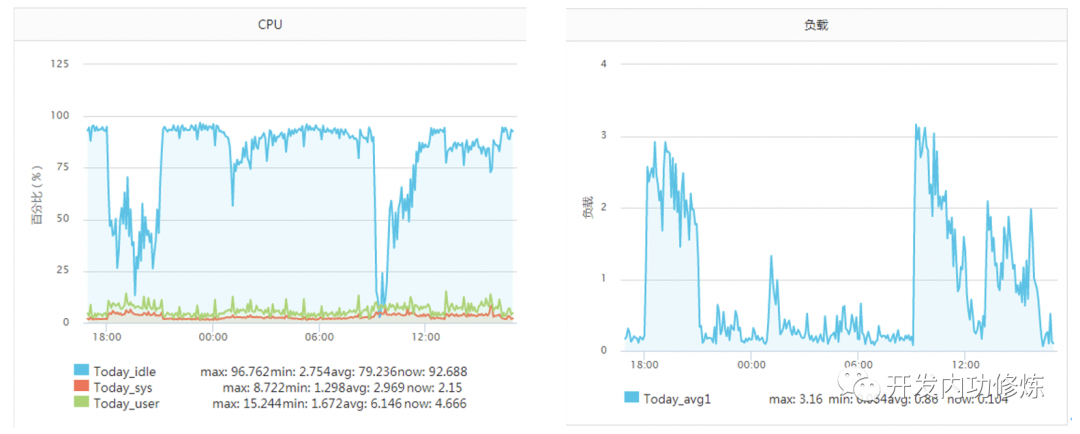
Der Dienst war zuvor bis zu 2000 qps pro Sekunde resistent, und der Leerlauf der CPU betrug immer mehr als 70%. Warum plötzlich die CPU nicht mehr ausreicht. Noch seltsamer ist, dass die Last in der Zeit, in der die CPU den Boden erreichte, nicht hoch war (der Server ist ein 4-Kern-Computer und die Last 3-4 ist normal). Später, nach einer Untersuchung, wurde festgestellt, dass, wenn der TCP-Client TIME_WAIT ungefähr 30.000 war, was dazu führte, dass die verfügbaren Ports unzureichend waren, der CPU-Overhead des Verbindungssystemaufrufs direkt um mehr als das 100-fache anstieg und der Zeitverbrauch 2500us erreichte ( Mikrosekunden) jedes Mal. Millisekundenpegel.
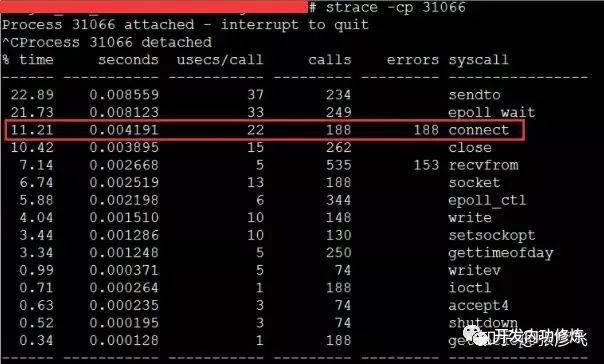
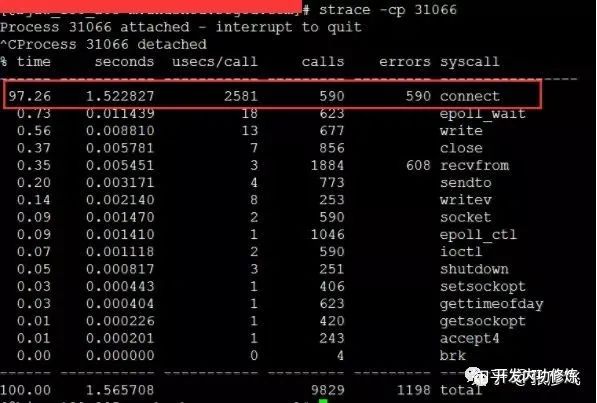
Bei dieser Art von Problem schien die Gesamtzeit für die TCP-Verbindung akzeptabel zu sein, obwohl sich die TCP-Verbindungsaufbauzeit nur um etwa 2 ms erhöhte. Das Problem hierbei ist jedoch, dass die meisten dieser 2 ms CPU-Zyklen verbrauchen, sodass das Problem nicht klein ist. Die Lösung ist auch sehr einfach und es gibt viele Möglichkeiten: Ändern Sie den Kernel-Parameter net.ipv4.ip_local_port_range, um mehr Portnummern zu reservieren, oder wechseln Sie zu einer langen Verbindung.
2) Die halbe / vollständige Verbindungswarteschlange ist voll
Wenn während des Verbindungsaufbaus eine Warteschlange voll ist, wird die vom Client gesendete Synchronisierung oder Bestätigung verworfen. Nachdem der Client lange ohne Erfolg gewartet hat, sendet er eine TCP-Neuübertragung. Nehmen Sie das Beispiel einer Semi-Connection-Warteschlange:
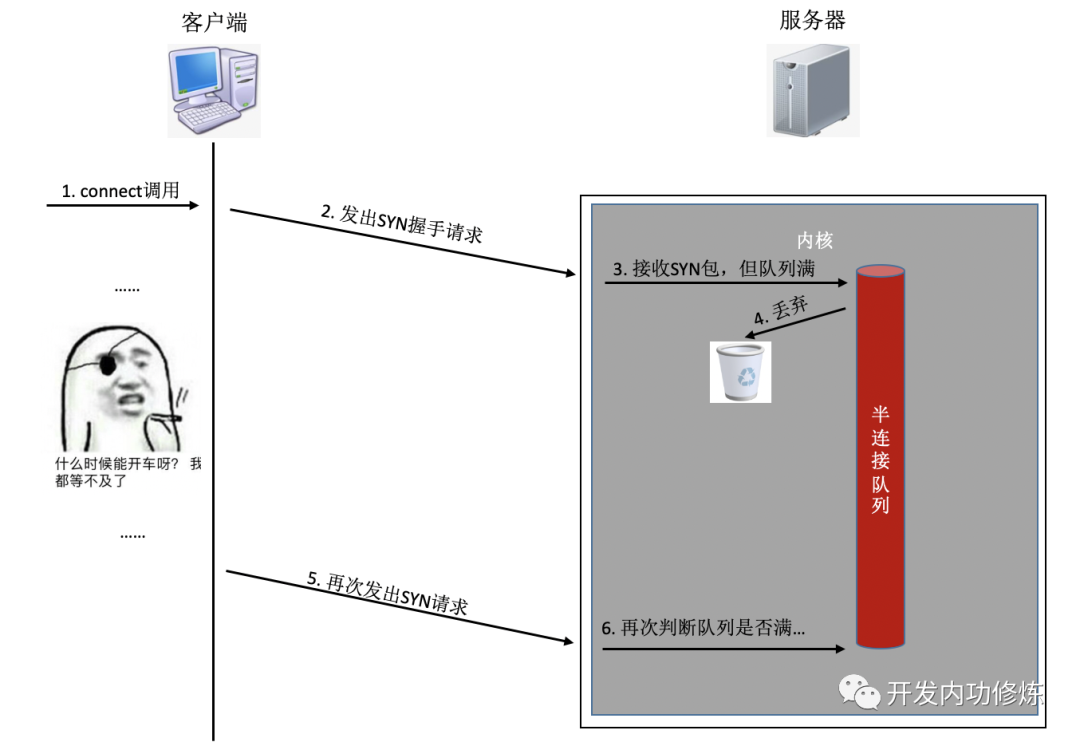
Was Sie wissen müssen, ist, dass die Neuübertragungszeit des obigen TCP-Handshake-Timeouts in Sekunden ist. Das heißt, sobald die Verbindungswarteschlange auf der Serverseite dazu führt, dass die Verbindung nicht erfolgreich hergestellt wird, dauert es mindestens Sekunden, bis die Verbindung hergestellt ist. Normalerweise dauert es im selben Computerraum nur weniger als 1 Millisekunde, was ungefähr 1000-mal höher ist. Insbesondere bei Programmen, die Benutzern Echtzeitdienste bereitstellen, wird die Benutzererfahrung stark beeinträchtigt. Wenn der Handshake selbst für die erneute Übertragung nicht erfolgreich ist, kann der Benutzer wahrscheinlich nicht auf den zweiten erneuten Versuch warten, und der Benutzerzugriff läuft direkt ab.
Es gibt eine andere schlimmere Situation, die auch andere Benutzer betreffen kann. Wenn Sie das Prozess- / Thread-Pool-Modell verwenden, um Dienste wie php-fpm bereitzustellen. Wir wissen, dass der fpm-Prozess blockiert ist. Wenn er auf eine Benutzeranforderung reagiert, kann der Prozess nicht auf andere Anforderungen antworten. Angenommen, Sie haben 100 Prozesse / Threads geöffnet und innerhalb eines bestimmten Zeitraums stecken 50 Prozesse / Threads in der Handshake-Verbindung mit dem Redis- oder MySQL-Server fest ( Hinweis: Zu diesem Zeitpunkt ist Ihr Server die Clientseite der TCP-Verbindung ). . In diesem Zeitraum können nur 50 normale Arbeitsprozesse / Threads verwendet werden. Und diese 50 Mitarbeiter sind möglicherweise überhaupt nicht in der Lage, damit umzugehen, und Ihr Service ist zu diesem Zeitpunkt möglicherweise überlastet. Wenn es etwas länger dauert, kann eine Lawine auftreten und der gesamte Dienst kann betroffen sein.
Wie können wir überprüfen, ob der vorliegende Dienst aufgetreten ist, weil die Warteschlange für die halbe / vollständige Verbindung voll ist, da die Folgen so schwerwiegend sein können? Auf der Clientseite können Sie Pakete erfassen, um zu überprüfen, ob eine SYN TCP-Neuübertragung vorliegt. Wenn gelegentlich TCP-Neuübertragungen durchgeführt werden, liegt möglicherweise ein Problem mit der entsprechenden Serververbindungswarteschlange vor.
Auf der Serverseite ist die Anzeige einfacher. netstat -sSie können die Statistik des Paketverlusts anzeigen, der dadurch verursacht wird, dass die aktuelle System-Halbverbindungswarteschlange voll ist. Diese Nummer gibt jedoch die Gesamtzahl der verlorenen Pakete an. Sie müssen watchBefehle verwenden, um dynamisch zu überwachen. Wenn sich die unten stehende Zahl während Ihrer Überwachung ändert, bedeutet dies, dass der aktuelle Server aufgrund der vollständigen Warteschlange für halbe Verbindungen Pakete verloren hat. Möglicherweise müssen Sie die Länge Ihrer Semi-Connection-Warteschlange erhöhen.
$ watch 'netstat -s | grep LISTEN'
8 SYNs to LISTEN sockets ignoredBei vollständig verbundenen Warteschlangen ist die Anzeigemethode ähnlich.
$ watch 'netstat -s | grep overflowed'
160 times the listen queue of a socket overflowedWenn Ihr Dienst Pakete verliert, weil die Warteschlange voll ist, besteht eine Möglichkeit darin, die Länge der Warteschlange für halbe / volle Verbindungen zu erhöhen. Im Linux-Kernel wird die Länge der Semi-Connection-Warteschlange hauptsächlich von tcp_max_syn_backlog beeinflusst und kann auf einen geeigneten Wert erhöht werden.
# cat /proc/sys/net/ipv4/tcp_max_syn_backlog
1024
# echo "2048" > /proc/sys/net/ipv4/tcp_max_syn_backlogDie Länge der vollständig verbundenen Warteschlange ist die kleinere des Backlogs, das übergeben wird, wenn die Anwendung listen und den Kernelparameter net.core.somaxconn aufruft. Möglicherweise müssen Sie Ihre Anwendung und diesen Kernel-Parameter gleichzeitig anpassen.
# cat /proc/sys/net/core/somaxconn
128
# echo "256" > /proc/sys/net/core/somaxconn改完之后我们可以通过ss命令输出的Send-Q确认最终生效长度:
$ ss -nlt
Recv-Q Send-Q Local Address:Port Address:Port
0 128 *:80 *:*
Recv-Q告诉了我们当前该进程的全连接队列使用长度情况。如果Recv-Q已经逼近了Send-Q,那么可能不需要等到丢包也应该准备加大你的全连接队列了。
如果加大队列后仍然有非常偶发的队列溢出的话,我们可以暂且容忍。如果仍然有较长时间处理不过来怎么办?另外一个做法就是直接报错,不要让客户端超时等待。例如将Redis、Mysql等后端接口的内核参数tcp_abort_on_overflow为1。如果队列满了,直接发reset给client。告诉后端进程/线程不要痴情地傻等。这时候client会收到错误“connection reset by peer”。牺牲一个用户的访问请求,要比把整个站都搞崩了还是要强的。
三TCP连接耗时实测
我写了一段非常简单的代码,用来在客户端统计每创建一个TCP连接需要消耗多长时间。
<?php
$ip = {服务器ip};
$port = {服务器端口};
$count = 50000;
function buildConnect($ip,$port,$num){
for($i=0;$i<$num;$i++){
$socket = socket_create(AF_INET,SOCK_STREAM,SOL_TCP);
if($socket ==false) {
echo "$ip $port socket_create() 失败的原因是:".socket_strerror(socket_last_error($socket))."\n";
sleep(5);
continue;
}
if(false == socket_connect($socket, $ip, $port)){
echo "$ip $port socket_connect() 失败的原因是:".socket_strerror(socket_last_error($socket))."\n";
sleep(5);
continue;
}
socket_close($socket);
}
}
$t1 = microtime(true);
buildConnect($ip, $port, $count);
echo (($t2-$t1)*1000).'ms';在测试之前,我们需要本机linux可用的端口数充足,如果不够50000个,最好调整充足。
# echo "5000 65000" /proc/sys/net/ipv4/ip_local_port_range
1)正常情况
注意:无论是客户端还是服务器端都不要选择有线上服务在跑的机器,否则你的测试可能会影响正常用户访问
首先我的客户端位于河北怀来的IDC机房内,服务器选择的是公司广东机房的某台机器。执行ping命令得到的延迟大约是37ms,使用上述脚本建立50000次连接后,得到的连接平均耗时也是37ms。这是因为前面我们说过的,对于客户端来看,第三次的握手只要包发送出去,就认为是握手成功了,所以只需要一次RTT、两次传输耗时。虽然这中间还会有客户端和服务端的系统调用开销、软中断开销,但由于它们的开销正常情况下只有几个us(微秒),所以对总的连接建立延时影响不大。
接下来我换了一台目标服务器,该服务器所在机房位于北京。离怀来有一些距离,但是和广东比起来可要近多了。这一次ping出来的RTT是1.6~1.7ms左右,在客户端统计建立50000次连接后算出每条连接耗时是1.64ms。
再做一次实验,这次选中实验的服务器和客户端直接位于同一个机房内,ping延迟在0.2ms~0.3ms左右。跑了以上脚本以后,实验结果是50000 TCP连接总共消耗了11605ms,平均每次需要0.23ms。
线上架构提示:这里看到同机房延迟只有零点几ms,但是跨个距离不远的机房,光TCP握手耗时就涨了4倍。如果再要是跨地区到广东,那就是百倍的耗时差距了。线上部署时,理想的方案是将自己服务依赖的各种mysql、redis等服务和自己部署在同一个地区、同一个机房(再变态一点,甚至可以是甚至是同一个机架)。因为这样包括TCP链接建立啥的各种网络包传输都要快很多。要尽可能避免长途跨地区机房的调用情况出现。
2)连接队列溢出
测试完了跨地区、跨机房和跨机器。这次为了快,直接和本机建立连接结果会咋样呢?Ping本机ip或127.0.0.1的延迟大概是0.02ms,本机ip比其它机器RTT肯定要短。我觉得肯定连接会非常快,嗯实验一下。连续建立5W TCP连接,总时间消耗27154ms,平均每次需要0.54ms左右。嗯!?怎么比跨机器还长很多? 有了前面的理论基础,我们应该想到了,由于本机RTT太短,所以瞬间连接建立请求量很大,就会导致全连接队列或者半连接队列被打满的情况。一旦发生队列满,当时撞上的那个连接请求就得需要3秒+的连接建立延时。所以上面的实验结果中,平均耗时看起来比RTT高很多。
在实验的过程中,我使用tcpdump抓包看到了下面的一幕。原来有少部分握手耗时3s+,原因是半连接队列满了导致客户端等待超时后进行了SYN的重传。

我们又重新改成每500个连接,sleep 1秒。嗯好,终于没有卡的了(或者也可以加大连接队列长度)。结论是本机50000次TCP连接在客户端统计总耗时102399 ms,减去sleep的100秒后,平均每个TCP连接消耗0.048ms。比ping延迟略高一些。这是因为当RTT变的足够小的时候,内核CPU耗时开销就会显现出来了,另外TCP连接要比ping的icmp协议更复杂一些,所以比ping延迟略高0.02ms左右比较正常。
四结论
TCP连接建立异常情况下,可能需要好几秒,一个坏处就是会影响用户体验,甚至导致当前用户访问超时都有可能。另外一个坏处是可能会诱发雪崩。所以当你的服务器使用短连接的方式访问数据的时候,一定要学会要监控你的服务器的连接建立是否有异常状态发生。如果有,学会优化掉它。当然你也可以采用本机内存缓存,或者使用连接池来保持长连接,通过这两种方式直接避免掉TCP握手挥手的各种开销也可以。
Außerdem beträgt die Verzögerung der TCP-Einrichtung unter normalen Umständen etwa eine RTT-Zeit zwischen zwei Maschinen, was unvermeidbar ist. Sie können jedoch den physischen Abstand zwischen den beiden Computern steuern, um diese RTT zu verringern, z. B. indem Sie die Redis, auf die Sie zugreifen möchten, so nahe wie möglich an der Back-End-Schnittstellenmaschine bereitstellen, sodass die RTT auch von zehn ms auf reduziert werden kann die niedrigstmögliche Null. Einige ms.
Lassen Sie uns abschließend noch einmal darüber nachdenken, ob es möglich ist, Benutzern in New York Zugriff zu gewähren, wenn wir den Server in Peking bereitstellen. Unabhängig davon, ob wir uns im selben Computerraum oder in mehreren Computerräumen befinden, ist der Zeitverbrauch der elektrischen Signalübertragung im Wesentlichen vernachlässigbar (da die physische Entfernung sehr gering ist), und die Netzwerkverzögerung ist im Wesentlichen die Zeit, die von den Weiterleitungsgeräten benötigt wird. Wenn es jedoch die Hälfte der Erde durchquert, kann die Übertragungszeit des elektrischen Signals berechnet werden. Die sphärische Entfernung von Peking nach New York beträgt ungefähr 15.000 Kilometer. Unabhängig von der Weiterleitungsverzögerung des Geräts bewegt sich dann nur die Lichtgeschwindigkeit hin und her (RTT ist die Umlaufzeit, für die zwei Läufe erforderlich sind), und es dauert 15.000.000 * 2 / Lichtgeschwindigkeit = 100 ms. Die tatsächliche Verzögerung kann größer sein als diese, im Allgemeinen mehr als 200 ms. Aufgrund dieser Verzögerung ist es sehr schwierig, Dienste der zweiten Ebene bereitzustellen, auf die Benutzer zugreifen können. Für Benutzer in Übersee ist es daher am besten, einen lokalen Computerraum zu errichten oder einen Server in Übersee zu erwerben.