Die Anforderungen dieses Experiments sind (im Vergleich zum vorherigen Semester) recht klar. Dieser Blog ist in Python implementiert, die Scientific Computing Library wird verwendet numpy, und die Zeichnung wird verwendet matplotlib.pyplot. Importieren Sie der Einfachheit halber Folgendes am Anfang der Datei:
import numpy as np
import matplotlib.pyplot as plt
Die in diesem Experiment verwendeten numpy-Funktionen
Allgemein numpyabgekürzt als np(import numpy as np). Das Folgende ist eine kurze Einführung in die im Experiment verwendeten numpy-Funktionen. Der folgende Code muss oben hinzugefügt werden import numpy as np.
np.array
Diese Funktion gibt ein numpy.ndarrayObjekt zurück, das als mehrdimensionales Array verstanden werden kann (in diesem Experiment werden nur eindimensionale (kann als Spaltenvektor angesehen werden) und zweidimensionale (Matrix) verwendet). Verwenden Sie den Kleinbuchstaben x unterhalb von \pmb xxx ist ein Spaltenvektor, GroßbuchstabeAAA repräsentiert eine Matrix. A.TbedeutetAATransponieren von A. Die Operationen an Paarenndarraysind im Allgemeinen elementweise.
>>> x = np.array([1,2,3])
>>> x
array([1, 2, 3])
>>> A = np.array([[2,3,4],[5,6,7]])
>>> A
array([[2, 3, 4],
[5, 6, 7]])
>>> A.T # 转置
array([[2, 5],
[3, 6],
[4, 7]])
>>> A + 1
array([[3, 4, 5],
[6, 7, 8]])
>>> A * 2
array([[ 4, 6, 8],
[10, 12, 14]])
np.zufällig
np.randomDas Modul enthält mehrere Funktionen zur Generierung von Zufallszahlen. In diesem Experiment werden zufällige Initialisierungsparameter (Gradientenabstiegsverfahren) verwendet, um den Daten Rauschen hinzuzufügen.
>>> np.random.rand(3, 3) # 生成3 * 3 随机矩阵,每个元素服从[0,1)均匀分布
array([[8.18713933e-01, 5.46592778e-01, 1.36380542e-01],
[9.85514865e-01, 7.07323389e-01, 2.51858374e-04],
[3.14683662e-01, 4.74980699e-02, 4.39658301e-01]])
>>> np.random.rand(1) # 生成单个随机数
array([0.70944563])
>>> np.random.rand(5) # 长为5的一维随机数组
array([0.03911319, 0.67572368, 0.98884287, 0.12501456, 0.39870096])
>>> np.random.randn(3, 3) # 同上,但每个元素服从N(0, 1)(标准正态)
mathematische Funktion
Nur in diesem Experiment verwendet np.sin. Diese mathematischen Funktionen np.ndarrayarbeiten elementweise:
>>> x = np.array([0, 3.1415, 3.1415 / 2]) # 0, pi, pi / 2
>>> np.round(np.sin(x)) # 先求sin再四舍五入: 0, 0, 1
array([0., 0., 1.])
Darüber hinaus gibt es np.logFunktionen np.exp, die der Bibliothek von Python ähneln math(nur für elementweise Operationen auf mehrdimensionalen Arrays).
np.dot
Gibt das Produkt zweier Matrizen zurück. Stimmt mit der Matrixmultiplikation in der linearen Algebra überein. Die Spalten der ersten Matrix müssen gleich der Anzahl der Zeilen der zweiten Matrix sein. Insbesondere wenn eines davon ein eindimensionales Array ist, wird die Form automatisch an n × 1 n\times1 angepasstn×1 oder1 × n. 1\times n.1×n .
>>> x = np.array([1,2,3]) # 一维数组
>>> A = np.array([[1,1,1],[2,2,2],[3,3,3]]) # 3 * 3矩阵
>>> np.dot(x,A)
array([14, 14, 14])
>>> np.dot(A,x)
array([ 6, 12, 18])
>>> x_2D = np.array([[1,2,3]]) # 这是一个二维数组(1 * 3矩阵)
>>> np.dot(x_2D, A) # 可以运算
array([[14, 14, 14]])
>>> np.dot(A, x_2D) # 行列不匹配
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<__array_function__ internals>", line 5, in dot
ValueError: shapes (3,3) and (1,3) not aligned: 3 (dim 1) != 1 (dim 0)
np.auge
np.eye(n)Gibt eine Einheitsmatrix der Ordnung n zurück.
>>> A = np.eye(3)
>>> A
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
Lineare Algebra-Korrelation
np.linalgist eine Bibliothek zur linearen Algebra.
>>> A
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
>>> np.linalg.inv(A) # 求逆(本实验不考虑逆不存在)
array([[1. , 0. , 0. ],
[0. , 0.5 , 0. ],
[0. , 0. , 0.33333333]])
>>> x = np.array([1,2,3])
>>> np.linalg.norm(x) # 返回向量x的模长(平方求和开根号)
3.7416573867739413
>>> np.linalg.eigvals(A) # A的特征值
array([1., 2., 3.])
Daten generieren
Das Erzeugen der Daten erfordert das Hinzufügen von Rauschen (Fehler). Das im Unterricht gegebene Beispiel ist die Sinusfunktion, wir verwenden auch die Standard-Sinusfunktion y = sin x .y=\sin x.Y=Sündex . (Nach dem Hinzufügen von Rauschen ist esy = sin x + ϵ , y=\sin x+\epsilon,Y=Sündex+ϵ , mitϵ ∼ N ( 0 , σ 2 ) \epsilon\sim N(0, \sigma^2)ϵ∼N ( 0 ,p2 ), dasin x \sin xSündeDer Maximalwert von x ist 1 11 setzen wir die Varianz des Fehlers kleiner, hier auf1 25 \frac{1}{25}251).
'''
返回数据集,形如[[x_1, y_1], [x_2, y_2], ..., [x_N, y_N]]
保证 bound[0] <= x_i < bound[1].
- N 数据集大小, 默认为 100
- bound 产生数据横坐标的上下界, 应满足 bound[0] < bound[1], 默认为(0, 10)
'''
def get_dataset(N = 100, bound = (0, 10)):
l, r = bound
# np.random.rand 产生[0, 1)的均匀分布,再根据l, r缩放平移
# 这里sort是为了画图时不会乱,可以去掉sorted试一试
x = sorted(np.random.rand(N) * (r - l) + l)
# np.random.randn 产生N(0,1),除以5会变为N(0, 1 / 25)
y = np.sin(x) + np.random.randn(N) / 5
return np.array([x,y]).T
Der resultierende Datensatz hat einen Punkt auf einer Ebene pro Zeile. Die resultierenden Daten sehen so aus:
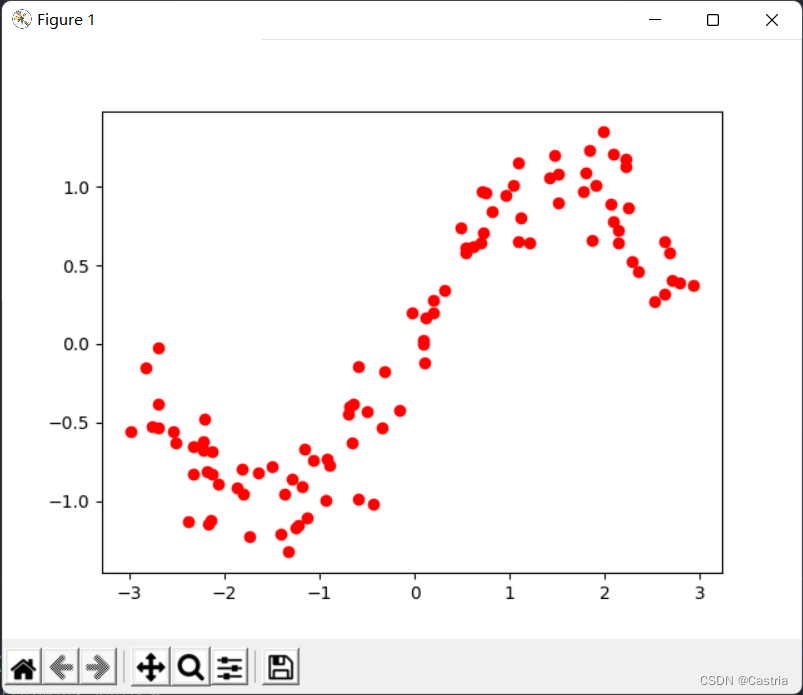
vage in Form einer Sinusfunktion. Der Code, der das obige Bild erzeugt, lautet wie folgt:
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
plt.show()
Kleinste-Quadrate-Anpassung
Unten verwenden wir vier Methoden (kleinste Quadrate, reguläre Term-/Kammregression, Gradientenabstieg, konjugierter Gradient), um die obigen gestörten Sinuskurven mit Polynomen anzupassen.
Analytische Lösungsableitung
Erinnern Sie sich einfach an das Prinzip der Methode der kleinsten Quadrate: Jetzt wollen wir ein mm verwendenPolynom f ( x ) vom Grad m
= w 0 + w 1 x + w 2 x 2 + . . . + wmxmf(x)=w_0+w_1x+w_2x^2+...+w_mx^mf ( x )=in0+in1x+in2x2+...+inmxm
zur Annäherung an die wahre Funktiony = sin x .y=\sin x.Y=Sündex . Unser Ziel ist es, die Datensätze( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) (x_1,y_1),(x_2,y_2), zu minimieren. .,(x_N,y_N)( x1,Y1) ,( x2,Y2) ,... ,( xN,YN) auf den VerlustLLL (Verlust), wobei die Verlustfunktion den quadrierten Fehler nimmt:
L = ∑ i = 1 N [ yi − f ( xi ) ] 2 L=\sum\limits_{i=1}^N[y_i-f(x_i) ]^ 2L=ich = 1∑N[ undich−f ( xich) ]2
Um die Parameterw 0 , w 1 , ..., wm , w_0,w_1,...,w_m zu finden,in0,in1,... ,inm, müssen wir den VerlustLLL bezogen auf w 0 , w 1 , . . . , wm w_0, w_1,...,w_min0,in1,... ,inmAbleitung von . Der Einfachheit halber verwenden wir die Notation der linearen Algebra:
X = ( 1 x 1 x 1 2 ⋯ x 1 m 1 x 2 x 2 2 ⋯ x 2 m ⋮ ⋮ 1 x N x N 2 ⋯ x N m ) N × ( m + 1 ) , Y = ( y 1 y 2 ⋮ y N ) N × 1 , W = ( w 0 w 1 ⋮ wm ) ( m + 1 ) × 1 . X=\begin{pmatrix}1 & x_1 & x_1 ^2 & \cdots & x_1^m\\ 1 & x_2 & x_2^2 & \cdots & x_2^m\\ \vdots & & & &\vdots\\ 1 & x_N & x_N^2 & \cdots & x_N^ m\ \\end{pmatrix}_{N\times(m+1)},Y=\begin{pmatrix}y_1 \\ y_2 \\ \vdots \\y_N\end{pmatrix}_{N\times1}, W= \begin{pmatrix}w_0 \\ w_1 \\ \vdots \\w_m\end{pmatrix}_{(m+1)\times1}.X=⎝
⎛11⋮1x1x2xNx12x22xN2⋯⋯⋯x1mx2m⋮xNm⎠
⎞N × ( m + 1 ),Y=⎝
⎛Y1Y2⋮YN⎠
⎞N × 1,Im=⎝
⎛in0in1⋮inm⎠
⎞( m + 1 ) × 1.
Unter dieser Darstellung ist
( f ( x 1 ) f ( x 2 ) ⋮ f ( x N ) ) = XW . \begin{pmatrix}f(x_1)\\ f(x_2) \\ \vdots \ \ f(x_N )\end{pmatrix}=XW.⎝
⎛f ( x1)f ( x2)⋮f ( xN)⎠
⎞=X W.
Wenn Sie irgendwelche Zweifel haben, können Sie es selbst mit der Matrixmultiplikation überprüfen . Fortfahrend kann die Summe der Fehlerterme ausgedrückt werden als
( f ( x 1 ) − y 1 f ( x 2 ) − y 2 ⋮ f ( x N ) − y N ) = XW − Y . \begin{pmatrix}f (x_1) -y_1 \\ f(x_2)-y_2 \\ \vdots \\ f(x_N)-y_N\end{pmatrix}=XW-Y.⎝
⎛f ( x1)−Y1f ( x2)−Y2⋮f ( xN)−YN⎠
⎞=X W−Y. Daher ist
die Verlustfunktion
L = ( XW − Y ) T ( XW − Y ) .L=(XW-Y)^T(XW-Y).L=( XW _−und )T (XW−Y ) .
(Um den Vektorx = ( x 1 , x 2 , . . . , x N ) T \pmb x=(x_1,x_2,...,x_N)^Txx=( x1,x2,... ,xN)Die Summe der Quadrate der Komponenten von T , die für x \pmb xxx ist das Skalarprodukt, alsox T x .\pmb x^T \pmb x.xxTxx . )
zur Erlangung desLLL kleinsteWWW (diesesWWW ein Spaltenvektor ist), müssenwirFinde die partielle Ableitung von L und sei 0 : 0:0:
∂ L ∂ W = ∂ ∂ W [ ( XW − Y ) T ( XW − Y ) ]] = ∂ ∂ W [ ( WTXT − YT ) ( XW − Y ) ] = ∂ ∂ W ( WTXTXW − WTXTY − YTXW + YTY ) = ∂ ∂ W ( WTXTXW − 2 YTXW + YTY ) ( 容易验证 , WTXTY = YTXW , 因而可以将其合并 ) = 2 XTXW − 2 XTY \begin{aligned}\frac{\partial L}{\partial W} &=\frac{\partial}{\partial W}[(XW-Y)^T(XW-Y)]\\ &=\frac{\partial}{\partial W}[(W^TX^TY^ T)(XW-Y)] \\ &=\frac{\partial}{\partial W}(W^TX^TXW-W^TX^TY-Y^TXW+Y^TY)\\ &=\frac {\partial}{\partial W}(W^TX^TXW-2Y^TXW+Y^TY)(容易验证,W^TX^TY=Y^TXW,因而可以将其合并)\\ &=2X^ TXW-2X^TY\end{aligned}∂ W∂L _=∂ W∂[( X W−und )T (XW−J )]=∂ W∂[( WTX _T−YT )(XW−J )]=∂ W∂( W.TX _T XW−ImTX _TY _−YT XW+YTY )_=∂ W∂( W.TX _T XW−2 JT XW+YT Y)(leicht zu überprüfen,ImTX _TY _=YT XW,somit kombinierbar )=2X _T XW−2X _TY _
Beschreibung:
(1) Von Zeile 3 bis Zeile 4 aufgrund von WTXTYW^TX^TYImTX _T Y和YTXWY^TXWYT XWsind alles Zahlen (oder1 × 1 1\times11×1 -Matrix), die beiden sind gegeneinander transponiert, sodass die Werte gleich sind und zu einem Element kombiniert werden können.
(2) Ableitung der Matrix von Zeile 4 nach Zeile 5, erster Term∂ ∂ W ( WT ( XTX ) W ) \frac{\partial}{\partial W}(W^T(X^TX)W )∂ W∂( W.T (XT X)W)handelt vonWWDie quadratische Form von W , ihre Ableitung ist2 XTXW . 2X^TXW.2X _T XW.(
3) Für den primären Term− 2 YTXW -2Y^TXW− 2 JDie Ableitung von T XW, wenn die Ableitung nach dem reellen Zahlenfeld erfolgt, sollte− 2 YTX .-2Y^TX erhalten.− 2 JT X.überprüfenSie und stellen Sie fest, dass der Typ der Matrix nicht korrekt ist, Sie müssen eine Transposition durchführen, es wird− 2 XTY . -2X^TY.− 2X _TY ._
Matrix-lineare Algebra wurde im Unterricht nicht systematisch gelehrt, nur um zu erklären, was hier erscheint. ( Ich werde nicht, wenn es mehr gibt )
Lassen Sie die partielle Ableitung 0 sein, erhalten
Sie XTXW = YTX, X^TXW=Y^TX,XT XW=YT X,
links multiplizieren( XTX ) − 1 (X^TX)^{-1}( XT X)− 1(XTXX^TXXSiehe den ergänzenden Hinweis unten für die Umkehrbarkeit von T X
W = ( XTX ) − 1 XTY .W=(X^TX)^{-1}X^TY.Im=( XT X)− 1X _T Y.
Das ist derWW,Für die analytische Lösung von W müssen wir nur die Funktion aufrufen, um diesen Wert zu berechnen.
'''
最小二乘求出解析解, m 为多项式次数
最小二乘误差为 (XW - Y)^T*(XW - Y)
- dataset 数据集
- m 多项式次数, 默认为 5
'''
def fit(dataset, m = 5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), Y)
Erklären Sie den Code ein wenig: Die erste Zeile erzeugt das oben vereinbarte XXDie X -Matrix,dataset[:,0]die die 0. Spalte des Datensatzes ist( x 1 , x 2 , . . . , x N ) T (x_1,x_2,...,x_N)^T( x1,x2,... ,xN)T ; die zweite Zeile istYYY -Matrix; die dritte Zeile gibt die obige analytische Lösung zurück. (Wenn Sie mit Python-Syntax oder -Bibliotheken nicht vertraut sindnumpy, ist dies ziemlich unfreundlich.)
Verifizieren Sie einfach das Ergebnis der von uns ausgeführten Funktion: Dazu schreiben wir zunächst eine drawFunktion zur Konvertierung des erhaltenen WWDas Polynomf ( x ) f(x) entsprechend WZeichnen Sie f ( x )pyplot auf das Bibliotheksbild:
'''
绘制给定系数W的, 在数据集上的多项式函数图像
- dataset 数据集
- w 通过上面四种方法求得的系数
- color 绘制颜色, 默认为 red
- label 图像的标签
'''
def draw(dataset, w, color = 'red', label = ''):
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = np.dot(X, w)
plt.plot(dataset[:, 0], Y, c = color, label = label)
Dann die Hauptfunktion:
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 最小二乘
coef1 = fit(dataset)
draw(dataset, coef1, color = 'black', label = 'OLS')
# 绘制图像
plt.legend()
plt.show()
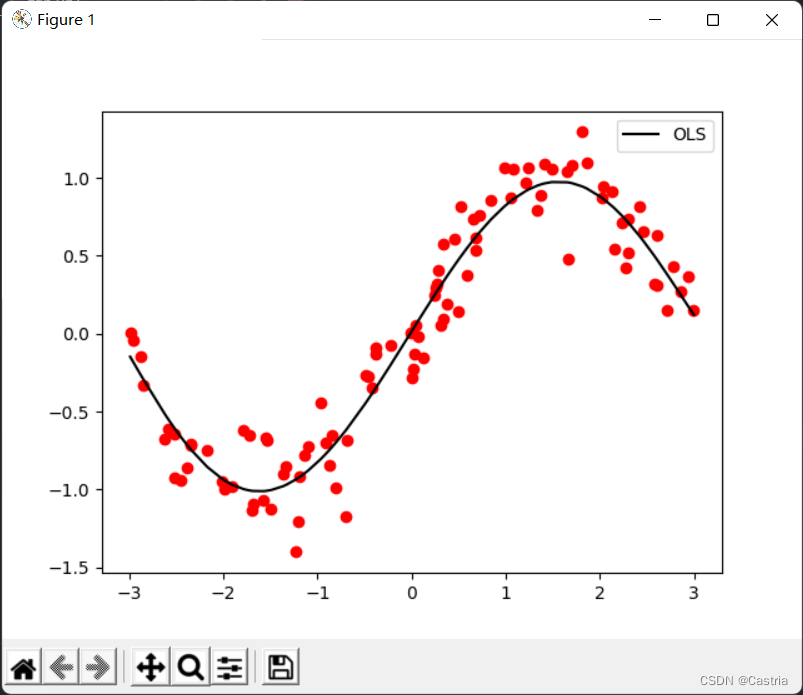
Es ist ersichtlich, dass der Effekt der Polynomanpassung 5. Grades ziemlich gut ist (der Datensatz wird jedes Mal zufällig generiert, unterscheidet sich also vom ersten Bild).
Wie beim gesamten Code in diesem Teil werden die folgenden gleichnamigen Funktionen nicht mehr beschrieben:
import numpy as np
import matplotlib.pyplot as plt
'''
返回数据集,形如[[x_1, y_1], [x_2, y_2], ..., [x_N, y_N]]
保证 bound[0] <= x_i < bound[1].
- N 数据集大小, 默认为 100
- bound 产生数据横坐标的上下界, 应满足 bound[0] < bound[1]
'''
def get_dataset(N = 100, bound = (0, 10)):
l, r = bound
x = sorted(np.random.rand(N) * (r - l) + l)
y = np.sin(x) + np.random.randn(N) / 5
return np.array([x,y]).T
'''
最小二乘求出解析解, m 为多项式次数
最小二乘误差为 (XW - Y)^T*(XW - Y)
- dataset 数据集
- m 多项式次数, 默认为 5
'''
def fit(dataset, m = 5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), Y)
'''
绘制给定系数W的, 在数据集上的多项式函数图像
- dataset 数据集
- w 通过上面四种方法求得的系数
- color 绘制颜色, 默认为 red
- label 图像的标签
'''
def draw(dataset, w, color = 'red', label = ''):
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = np.dot(X, w)
plt.plot(dataset[:, 0], Y, c = color, label = label)
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
coef1 = fit(dataset)
draw(dataset, coef1, color = 'black', label = 'OLS')
plt.legend()
plt.show()
Ergänzende Anweisungen
Oben gibt es ein weniger strenges Stück: für eine Matrix XXFür X ,XTXX^TXXT Xist nicht unbedingt reversibel. In diesem Experiment kann jedoch gezeigt werden, dass es sich um eine invertierbare Matrix handelt. Da diese Klasse keine lineare Algebra-Klasse ist, werden wir nicht zu viel Platz darauf verwenden, nur eine kurze Erinnerung:
(1)XXX ist einN × ( m + 1 ) N\times(m+1)N×( M+1 ) der Matrix. wobei die Anzahl der DatenNNN ist viel größer als der Polynomgradmmm , es gibtN > m + 1, N > m+1;N>m+1 ;
(2) Zur Veranschaulichungvon XTXX^TXXT Xist invertierbar, muss erklärt werden( XTX ) ( m + 1 ) × ( m + 1 ) (X^TX)_{(m+1)\times(m+1)}( XT X)( m + 1 ) × ( m + 1 )Voller Rang, das heißt R ( XTX ) = m + 1 ;R(X^TX)=m+1;R ( XT X)=m+1 ;
(3) In der linearen Algebra haben wir bewiesen, dassR ( X ) = R ( XT ) = R ( XTX ) = R ( XXT ) ; R(X)=R(X^T)=R(X^TX). )=R(XX^T);R ( X )=R ( XT )=R ( XT X)=R ( XX _T );
(4)XXX ist eineVandermonde-Matrix,deren Rang gleichmin { N , m + 1 } = m + 1 ist. min\{N,m+1\}=m+1.mein {
N ,m+1 }=m+1.
Regularisierungsterm hinzufügen (ridge regression)
Die Methode der kleinsten Quadrate ist anfällig für Überanpassung. Um diesen Fehler zu veranschaulichen, verwenden wir die ersten 50 Punkte des generierten Datensatzes zum Training (damit die Abtastung nicht gleichmäßig genug ist, hier nur zur Veranschaulichung der Überanpassung), erhalten die Parameter und zeichnen dann das gesamte Funktionsbild um die Anpassungswirkung zu überprüfen:
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 取前50个点进行训练
coef1 = fit(dataset[:50], m = 3)
# 再画出整个数据集上的图像
draw(dataset, coef1, color = 'black', label = 'OLS')
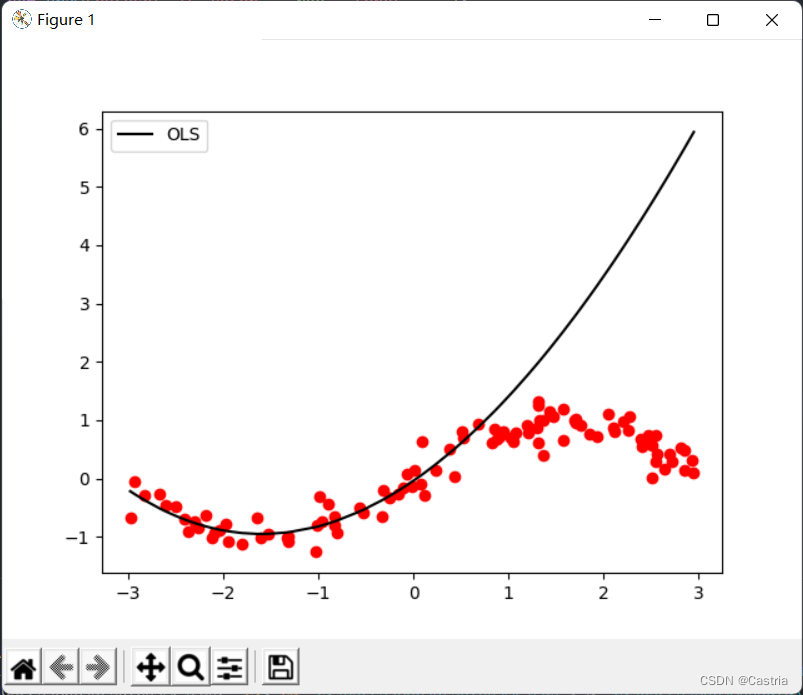
Überanpassung in mmDies ist besonders gravierend, wenn m groß ist ( m = 3 m = 3m=3 Uhr). Wenn der Polynomgrad zunimmt, um dem gegebenen Datensatz so nahe wie möglich zu kommen, wird die Größe der berechneten Koeffizienten größer und größer, und die Leistung bei unsichtbaren Proben wird schlechter. Wie oben gezeigt, können Sie sehen, dass die Anpassung an den ersten 50 Punkten liegt (ungefähr auf der Abszisse[ − 3 , 0 ] [-3,0][ − 3 ,0 ] ) ist sehr gut, auf dem Testset ist die Performance sehr schlecht ([ 0 , 3 ] [0,3][ 0 ,3 ] ). Um eine Überanpassung zu verhindern, kann ein Regularisierungsterm eingeführt werden. Zu diesem Zeitpunkt ist die VerlustfunktionLLL变为
L = ( XW − Y ) T ( XW − Y ) + λ ∣ ∣ W ∣ ∣ 2 2 L=(XW-Y)^T(XW-Y)+\lambda||W||_2^2L=( XW _−und )T (XW−und )+λ ∣∣ W ∣ ∣22
wobei ∣ ∣ ⋅ ∣ ∣ 2 2 ||\cdot||_2^2∣∣⋅∣ ∣22Zeigt L 2 L_2 anL2Das Quadrat der Norm, in diesem Fall WTW ; λ W^TW;\lambdaImT W;λ ist der Regularisierungskoeffizient. Diese Formel wird auch als Ridge-Regression bezeichnet. Seine Idee ist es, die Verlustfunktion und den resultierenden Parameter WWzu berücksichtigenModulo-Länge von W (beiL 2 L_2L2Norm), verhindert WWDer Parameter in W ist zu groß.
Zum Beispiel (Zahlen werden zufällig zusammengesetzt): wenn der Regularisierungskoeffizient 1 1 ist1 , wenn der quadratische Fehler von Schema 1 auf dem Datensatz0,5 , 0,5 ist,0,5 , zu diesem ZeitpunktW = ( 100 , − 200 , 300 , 150 ) TW=(100,-200,300,150)^TIm=( 100 ,− 200 ,300 ,150 )T ; der quadratische Fehler von Schema 2 auf dem Datensatz ist10, 10,10 , zu diesem ZeitpunktW = ( 1 , − 3 , 2 , 1 ) W=(1,-3,2,1)Im=( 1 ,− 3 ,2 ,1 ) , dann wählen wirW.W.W. Regularisierungskoeffizient λλλ charakterisiert dies fürWWDie Bedeutung der W -Modullänge:λ \lambdaJe größer λ , desto besser der WWJe höher die Modullänge von W , desto größer die Strafe. Wennλ = 0 , λ=0,l=0 wird die Ridge-Regression zur gewöhnlichen Methode der kleinsten Quadrate. Ähnlich wie bei der Ridge-Regression ist LASSO, das den Regularisierungsterm durchL 1 L_1L1Norm.
Durch Wiederholung der obigen Ableitung erhalten wir die analytische Lösung als
W = ( XTX + λ E m + 1 ) − 1 XTY .W=(X^TX+\lambda E_{m+1})^{-1}X^TY .Im=( XTX _+λE _m + 1)− 1X _T Y.wobeiE m + 1 E_{m+1
}UNDm + 1ist m + 1 m+1m+Einheitenmatrix 1. Ordnung. Man erhält leicht( XTX + λ E m + 1 ) (X^TX+\lambda E_{m+1})( XTX _+λE _m + 1) ist ebenfalls reversibel.
Dieser Teil des Codes lautet wie folgt.
'''
岭回归求解析解, m 为多项式次数, l 为 lambda 即正则项系数
岭回归误差为 (XW - Y)^T*(XW - Y) + λ(W^T)*W
- dataset 数据集
- m 多项式次数, 默认为 5
- l 正则化参数 lambda, 默认为 0.5
'''
def ridge_regression(dataset, m = 5, l = 0.5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X) + l * np.eye(m + 1)), X.T), Y)
Der Vergleich der beiden Methoden sieht wie folgt aus:
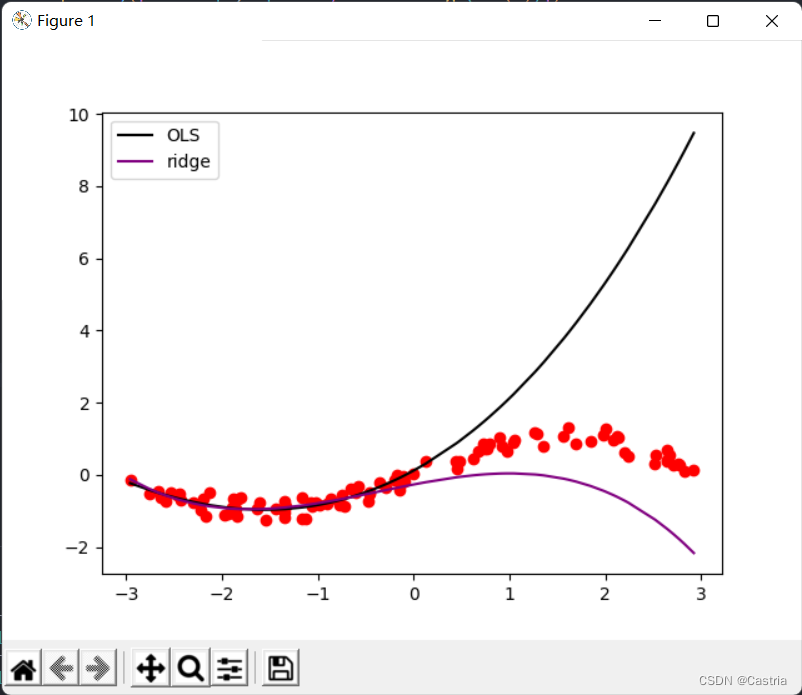
Aus dem Vergleich ist ersichtlich, dass die Ridge-Regression das Overfitting deutlich reduziert (zu diesem Zeitpunkt m = 3 , λ = 0,3 m = 3, λ = 0,3m=3 ,l=0,3 ).
Gradientenabstieg
Der Gradientenabstieg ist nicht der beste Weg, um dieses Problem zu lösen, und es kann leicht dazu führen, dass er nicht konvergiert. Stellen Sie zunächst kurz die Grundidee der Gradientenabstiegsmethode vor: Wenn wir die komplexe Funktion f ( x ) f(x) finden wollenDer Minimalwert (Maximalpunkt) von f ( x ) (dieses xxx kann ein Vektor sein usw.),
also xmin = arg min xf ( x ) x_{min}=\argmin_{x}f(x)xMin=xArgMinf ( x )
Gradientenabstieg wiederholt die folgenden Operationen:
(0) (zufällig)x 0 initialisieren ( t = 0 ) x_0(t=0)x0( t=0 ) ;
(1) Seif ( x ) f(x)f ( x ) inxt x_txtSteigung bei (wenn xxWenn x eindimensional ist, ist es die Ableitung)∇ f ( xt ) \nabla f(x_t)∇ f ( xt);
(2)xt + 1 = xt − η ∇ f ( xt ) x_{t+1}=x_t-\eta\nabla f(x_t)xt + 1=xt−η ∇ f ( xt)
(3) Wennxt + 1 x_{t+1}xt + 1mit xt x_txtWenn es wenig Unterschied gibt (erreicht den voreingestellten Bereich) oder die Anzahl der Iterationen die voreingestellte Obergrenze erreicht, stoppen Sie den Algorithmus; andernfalls wiederholen Sie (1) (2).
Darunter η \ etaη ist die Lernrate, die die Schrittgröße des Gradientenabstiegs bestimmt.
Das Folgende ist eine Gradientenabstiegsmethode, umy = x 2 y=x^2Y=xBeispielprogramm für den Minimalpunkt 2 :
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x ** 2
def draw():
x = np.linspace(-3, 3)
y = f(x)
plt.plot(x, y, c = 'red')
cnt = 0
# 初始化 x
x = np.random.rand(1) * 3
learning_rate = 0.05
while True:
grad = 2 * x
# -----------作图用,非算法部分-----------
plt.scatter(x, f(x), c = 'black')
plt.text(x + 0.3, f(x) + 0.3, str(cnt))
# -------------------------------------
new_x = x - grad * learning_rate
# 判断收敛
if abs(new_x - x) < 1e-3:
break
x = new_x
cnt += 1
draw()
plt.show()
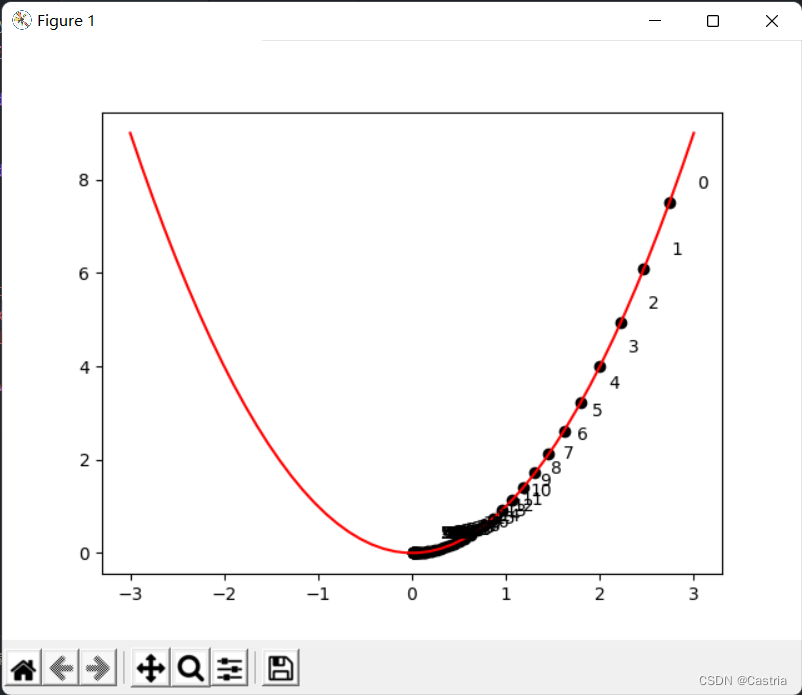
Das obige Bild zeigt xxx Während sich die Iteration entwickelt, können Siexxx nähert sich entlang der positiven Halbachse immer weiter Null. Es ist zu beachten, dass die Lernrate nicht zu groß sein darf (obwohl im obigen Programm die Lernrate etwas klein eingestellt ist), sie muss manuell angepasst werden, sonst ist es leicht vorstellbar,xxx oszilliert auf der positiven und negativen Halbachse hin und her, was eine Konvergenz erschwert.
Bei der Methode der kleinsten Quadrate ist die zu optimierende Funktion die Verlustfunktion
L = ( XW − Y ) T ( XW − Y ) . L=(XW-Y)^T(XW-Y).L=( XW _−und )T (XW−Y )
Als nächstes lösen wir das Problem mit dem Gradientenabstieg . In der obigen Herleitung gilt
∂ L ∂ W = 2 XTXW − 2 XTY , \begin{aligned}\frac{\partial L}{\partial W}=2X^TXW-2X^TY\end{aligned},∂ W∂L _=2X _T XW−2X _TY _,
also jedes Mal, wenn wir eine Iteration aufWWW subtrahiert diesen Gradienten bis zum ParameterWWW konvergiert. Nach Experimenten wird der quadratische Fehler jedoch den Gradienten zu groß machen und der Prozess kann nicht konvergieren.Daher wird der mittlere quadratische Fehler (MSE) verwendet, um ihn zu ersetzen, was darin besteht, die ursprüngliche Formel durchNNN :
'''
梯度下降法(Gradient Descent, GD)求优化解, m 为多项式次数, max_iteration 为最大迭代次数, lr 为学习率
注: 此时拟合次数不宜太高(m <= 3), 且数据集的数据范围不能太大(这里设置为(-3, 3)), 否则很难收敛
- dataset 数据集
- m 多项式次数, 默认为 3(太高会溢出, 无法收敛)
- max_iteration 最大迭代次数, 默认为 1000
- lr 梯度下降的学习率, 默认为 0.01
'''
def GD(dataset, m = 3, max_iteration = 1000, lr = 0.01):
# 初始化参数
w = np.random.rand(m + 1)
N = len(dataset)
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = dataset[:, 1]
try:
for i in range(max_iteration):
pred_Y = np.dot(X, w)
# 均方误差(省略系数2)
grad = np.dot(X.T, pred_Y - Y) / N
w -= lr * grad
'''
为了能捕获这个溢出的 Warning,需要import warnings并在主程序中加上:
warnings.simplefilter('error')
'''
except RuntimeWarning:
print('梯度下降法溢出, 无法收敛')
return w
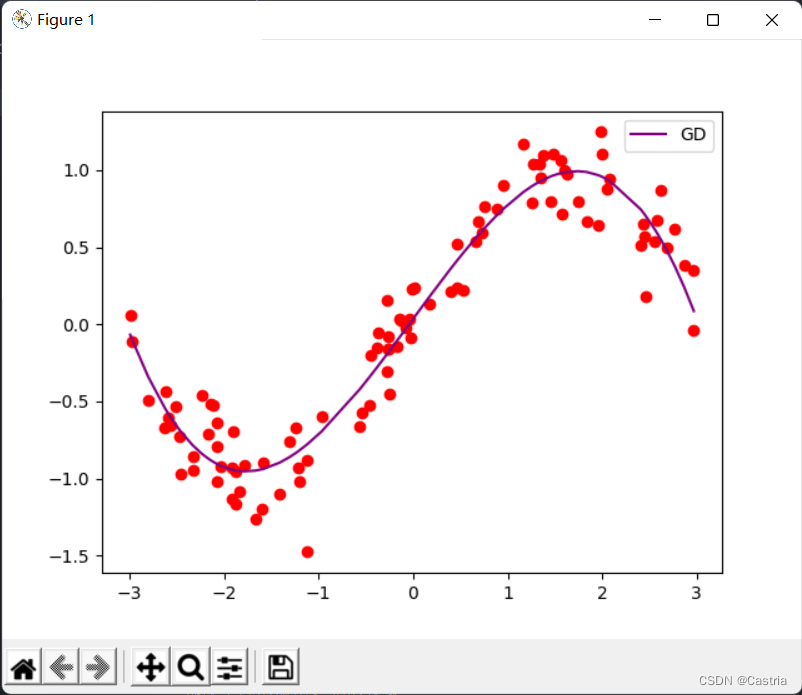
Zu diesem Zeitpunkt, wenn mmWenn m etwas größer eingestellt ist (z. B. 4), läuft der Gradient während der Iteration über, sodass die Parameter nicht konvergieren können. Beim Konvergieren ist der Anpassungseffekt in Ordnung:
Konjugierte Gradientenmethode
Konjugierte Gradienten können verwendet werden, um die Form A x = b A\pmb x=\pmb b zu lösenEINxx=bGleichungssystem für b , oder minimieren Sie die quadratische Form f ( x ) = 1 2 x TA x − b T x + c .f(\pmb x)=\frac12\pmb x^TA\pmb x-\pmb b^ T \pmb x+c.f (xx )=21xxTA _xx−bbTxx+c . (Es kann gezeigt werden, dass für positiv definiteAAA , die beiden sind äquivalent) wobeiAAA ist einepositiv definiteMatrix. In diesem Problem fragen wir nach der Lösung von XTXW = YTX , X^TXW=Y^TX,XT XW=YT X,
dannA ( m + 1 ) × ( m + 1 ) = XTX , b = YT . A_{(m+1)\times(m+1)}=X^TX,\pmb b=Y^ T .EIN( m + 1 ) × ( m + 1 )=XT X,bb=YT. Wenn wir einen regulären Term hinzufügenwollen, wird daraus die Lösung
( XTX + λ E ) W = YTX .(X^TX+\lambda E)W=Y^TX.( XTX _+λ E ) W=YT X.
Lassen Sie mich zunächst erklären:XTXX^TXXT Xist nicht unbedingt positiv definit, muss aber positiv semidefinit sein (siehe). Aber im Experiment brauchen wir uns um dieses Problem im Grunde nicht zu kümmern, dennXTXX^TXXT Xist sehr wahrscheinlich positiv definit, wir fügen dem Code nur eine Behauptung hinzu und schenken dieser Bedingung nicht viel Aufmerksamkeit.
Die Idee der Methode der konjugierten Gradienten und der Beweisprozess sind relativ lang. Sie können aufdiese Serie. Hier werden nur die Algorithmusschritte angegeben (am Anfang des dritten oben verlinkten Artikels):
(0) x initialisieren ( 0 ); x_{(0)};x( 0 );
(1) Initialisiered ( 0 ) = r ( 0 ) = b − A x ( 0 ) ; d_{(0)}=r_{(0)}=b-Ax_{(0)};d( 0 )=r( 0 )=b−Ein x( 0 );
(2)令α ( ich ) = r ( ich ) T r ( ich ) d ( ich ) TA d ( ich ) ; \alpha_{(i)}=\frac{r_{(i)}^Tr_{(i)}}{d_{(i)}^TAd_{(i)}};a( ich )=d( ich )TEin d( ich )r( ich )Tr( ich );
(3)迭代x ( i + 1 ) = x ( i ) + α ( i ) d ( i ) ; x_{(i+1)}=x_{(i)}+\alpha_{(i)}d_{(i)};x( ich + 1 )=x( ich )+a( ich )d( ich );
(4)令r ( ich + 1 ) = r ( ich ) − α ( ich ) EIN d ( ich ) ; r_{(i+1)}=r_{(i)}-\alpha_{(i)}Ad_{(i)};r( ich + 1 )=r( ich )−a( ich )Ein d( ich );
(5)令β ( i + 1 ) = r ( i + 1 ) T r ( i + 1 ) r ( i ) T r ( i ) , d ( i + 1 ) = r ( i + 1 ) + β ( ich + 1 ) d ( ich ) . \beta_{(i+1)}=\frac{r_{(i+1)}^Tr_{(i+1)}}{r_{(i)}^Tr_{(i)}},d_{( i+1)}=r_{(i+1)}+\beta_{(i+1)}d_{(i)}.b( ich + 1 )=r( ich )Tr( ich )r( ich + 1 )Tr( ich + 1 ),d( ich + 1 )=r( ich + 1 )+b( ich + 1 )d( ich ).
(6)当∣ ∣ r ( i ) ∣ ∣ ∣ ∣ r ( 0 ) ∣ ∣ < ϵ \frac{||r_{(i)}||}{||r_{(0)}||}<\ Epsilon∣∣r _( 0 )∣∣∣∣r _( ich )∣∣<ϵ , stoppe den Algorithmus, andernfalls iteriere weiter ab (2). ϵ \epsilonϵ ist ein kleiner voreingestellter Wert, ich nehme hier1 0 − 5 . 10^{-5}.1 0− 5.
Im Folgenden folgen wir diesem Prozess, um den Codezu
'''
共轭梯度法(Conjugate Gradients, CG)求优化解, m 为多项式次数
- dataset 数据集
- m 多项式次数, 默认为 5
- regularize 正则化参数, 若为 0 则不进行正则化
'''
def CG(dataset, m = 5, regularize = 0):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
A = np.dot(X.T, X) + regularize * np.eye(m + 1)
assert np.all(np.linalg.eigvals(A) > 0), '矩阵不满足正定!'
b = np.dot(X.T, dataset[:, 1])
w = np.random.rand(m + 1)
epsilon = 1e-5
# 初始化参数
d = r = b - np.dot(A, w)
r0 = r
while True:
alpha = np.dot(r.T, r) / np.dot(np.dot(d, A), d)
w += alpha * d
new_r = r - alpha * np.dot(A, d)
beta = np.dot(new_r.T, new_r) / np.dot(r.T, r)
d = beta * d + new_r
r = new_r
# 基本收敛,停止迭代
if np.linalg.norm(r) / np.linalg.norm(r0) < epsilon:
break
return w
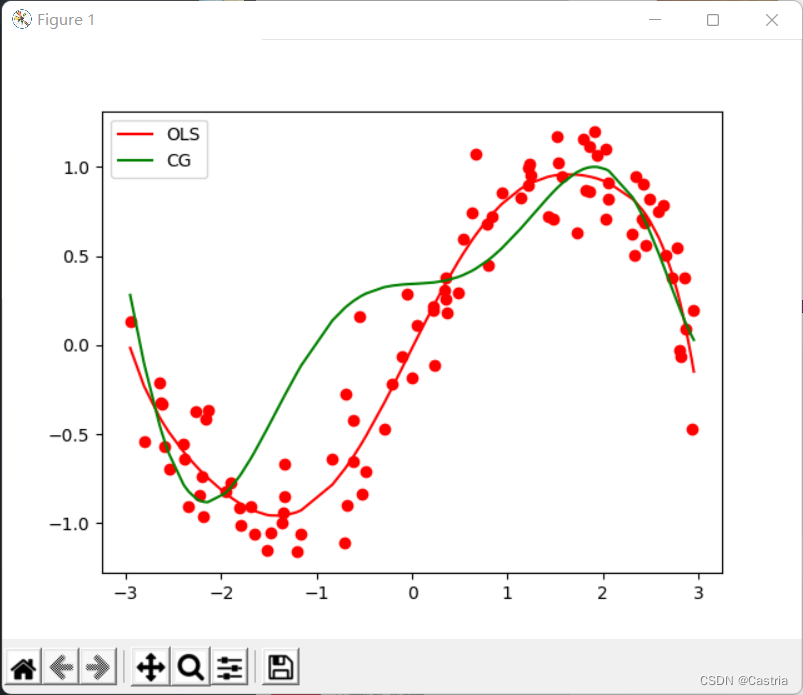
Verglichen mit dem naiven Gradientenabstiegsverfahren konvergiert das konjugierte Gradientenverfahren schnell und stabil. Mit zunehmendem Grad des Polynoms wird die Anpassung jedoch schlechter: bei m = 7 m=7m=7 wird es wie folgt mit der Methode der kleinsten Quadrate verglichen:
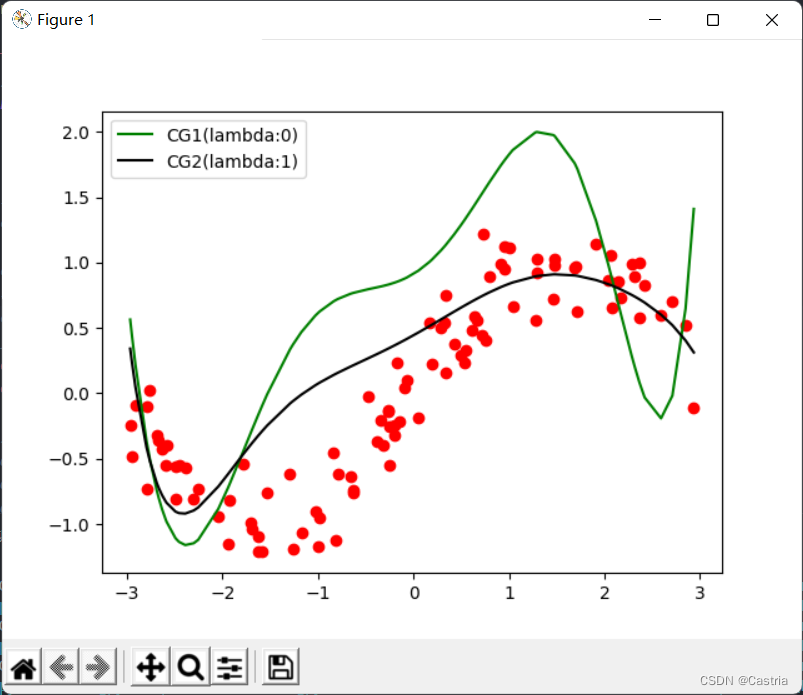
Zu diesem Zeitpunkt kann es noch teilweise durch den regulären Term gemildert werden (die Zahl istm = 7 , λ = 1 m = 7, λ = 1m=7 ,l=1 ):
Schließlich sind die passenden Bilder der vier Methoden (im Grunde gleich) und der Hauptfunktion beigefügt, und die Parameter können entsprechend den experimentellen Anforderungen angepasst werden:
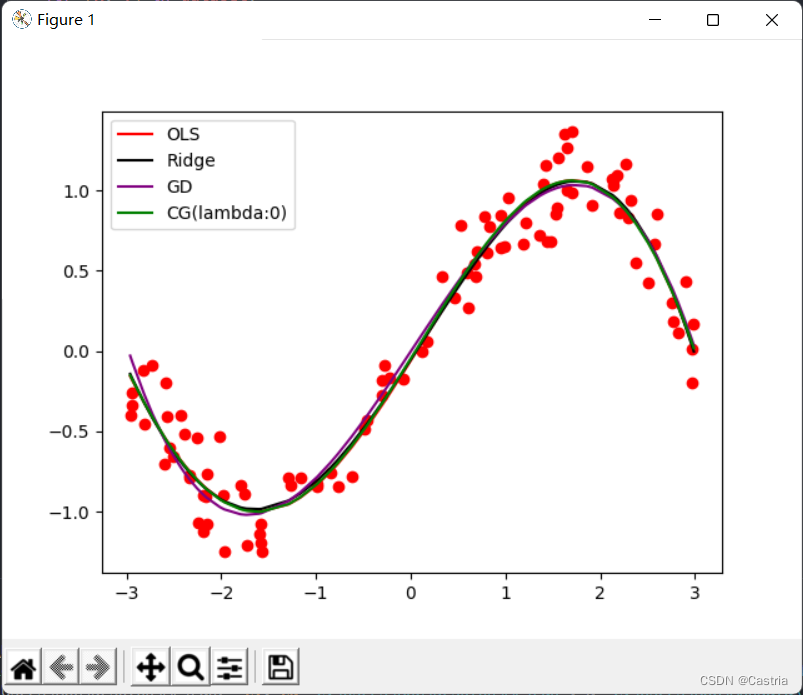
if __name__ == '__main__':
warnings.simplefilter('error')
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 最小二乘法
coef1 = fit(dataset)
# 岭回归
coef2 = ridge_regression(dataset)
# 梯度下降法
coef3 = GD(dataset, m = 3)
# 共轭梯度法
coef4 = CG(dataset)
# 绘制出四种方法的曲线
draw(dataset, coef1, color = 'red', label = 'OLS')
draw(dataset, coef2, color = 'black', label = 'Ridge')
draw(dataset, coef3, color = 'purple', label = 'GD')
draw(dataset, coef4, color = 'green', label = 'CG(lambda:0)')
# 绘制标签, 显示图像
plt.legend()
plt.show()