1. Zeitreihendaten und ihre Eigenschaften
Zeitreihendaten sind eine Reihe von Indikatorüberwachungsdaten, die kontinuierlich auf der Grundlage einer relativ stabilen Frequenz generiert werden, wie z. B. der Dow Jones Index innerhalb eines Jahres, die gemessene Temperatur zu verschiedenen Zeitpunkten an einem Tag und so weiter. Zeitreihendaten haben die folgenden Eigenschaften:
- Invarianz historischer Daten
- Datenverfügbarkeit
- Aktualität der Daten
- strukturierte Daten
- Datenvolumen
Zweitens die Grundstruktur der Zeitreihendatenbank
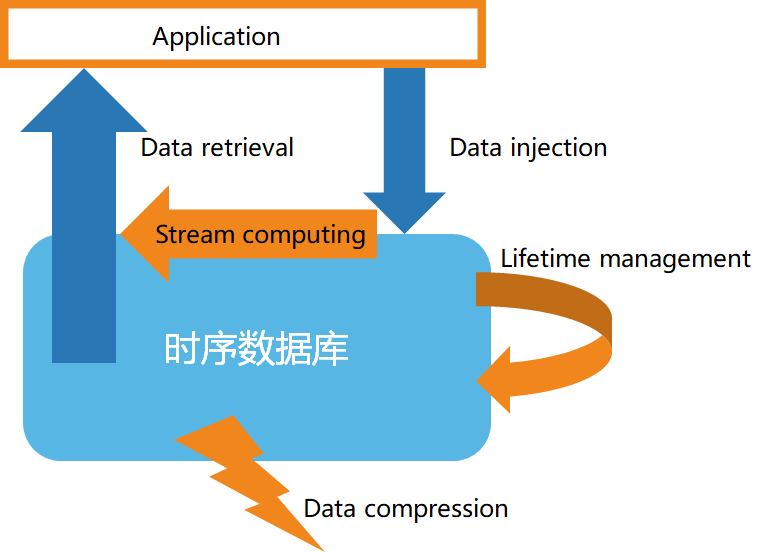
Gemäß den Eigenschaften von Zeitreihendaten haben Zeitreihendatenbanken im Allgemeinen die folgenden Eigenschaften:
- Hochgeschwindigkeits-Datenspeicherung
- Datenlebenszyklusmanagement
- Stream-Verarbeitung von Daten
- Effiziente Datenabfrage
- Benutzerdefinierte Datenkomprimierung
3. Einführung in das Stream-Computing
Stream Computing bezieht sich hauptsächlich auf die Echtzeiterfassung massiver Daten aus verschiedenen Datenquellen sowie die Echtzeitanalyse und -verarbeitung, um wertvolle Informationen zu erhalten. Zu den gängigen Geschäftsszenarien gehören die schnelle Reaktion auf Echtzeitereignisse, Echtzeitalarme bei Marktveränderungen, die interaktive Analyse von Echtzeitdaten usw. Stream Computing umfasst im Allgemeinen die folgenden Funktionen:
1) Filterung und Konvertierung (Filter & Karte)
2) Aggregations- und Fensterfunktionen (Reduce, Aggregation/Window)
3) Zusammenführen mehrerer Datenströme und Mustervergleich (Joining & Pattern Detection)
4) Von der Stream- zur Blockverarbeitung
4. Zeitreihen-Datenbankunterstützung für Stream-Computing
-
Fall 1: Verwenden Sie eine benutzerdefinierte Stream-Computing-API, wie im folgenden Beispiel gezeigt:
from(bucket: "mydb")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "mymeasurement")
|> map(fn: (r) => ({ r with value: r.value * 2 }))
|> filter(fn: (r) => r.value > 100)
|> aggregateWindow(every: 1m, fn: sum, createEmpty: false)
|> group(columns: ["location"])
|> join(tables: {stream1: {bucket: "mydb", measurement: "stream1", start: -1h}, stream2: {bucket: "mydb", measurement: "stream2", start: -1h}}, on: ["location"])
|> alert(name: "value_above_threshold", message: "Value is above threshold", crit: (r) => r.value > 100)
|> to(bucket: "mydb", measurement: "output", tagColumns: ["location"])
-
Fall 2: Verwenden Sie SQL-ähnliche Anweisungen zum Erstellen von Stream-Computing und zum Definieren von Stream-Computing-Regeln wie folgt:
CREATE STREAM current_stream
TRIGGER AT_ONCE
INTO current_stream_output_stb AS
SELECT
_wstart as start,
_wend as end,
max(current) as max_current
FROM meters
WHERE voltage <= 220
INTEVAL (5S) SLIDING (1s);