Für mehr technischen Austausch und Möglichkeiten zur Stellensuche beachten Sie bitte das offizielle WeChat-Konto der ByteDance Data Platform und antworten Sie [1], um der offiziellen Austauschgruppe beizutreten
ByteHouse ist ein Cloud-natives Data Warehouse auf Volcano Engine, das Benutzern ein extrem schnelles Analyseerlebnis bietet und Echtzeit-Datenanalysen und umfangreiche Offline-Datenanalysen unterstützen kann; bequeme elastische Expansions- und Kontraktionsfunktionen, extreme Analyseleistung und umfangreiche Funktionen auf Unternehmensebene , um Kunden bei der digitalen Transformation zu unterstützen.
Dieser Artikel stellt die Entwicklung der Echtzeit-Importtechnologie von ByteHouse basierend auf verschiedenen Architekturen aus den Perspektiven der Nachfragemotivation, der Technologieimplementierung und der praktischen Anwendung vor.
Echtzeit-Importanforderungen des internen Geschäfts
Die Motivation für die Weiterentwicklung der Echtzeit-Importtechnologie von ByteHouse entstand aus den Anforderungen des internen Geschäfts von ByteDance.
Innerhalb von Byte verwendet ByteHouse hauptsächlich Kafka als Hauptdatenquelle für den Echtzeitimport ( dieser Artikel verwendet den Kafka-Import als Beispiel, um die Beschreibung zu erweitern, was im Folgenden nicht wiederholt wird ). Für die meisten internen Benutzer ist das Datenvolumen relativ groß, daher achten die Benutzer mehr auf die Leistung des Datenimports, die Stabilität der Dienste und die Skalierbarkeit der Importfunktionen. Was die Datenlatenz betrifft, können die meisten Benutzer ihre Anforderungen erfüllen, solange sie in Sekunden sichtbar sind. Basierend auf einem solchen Szenario hat ByteHouse eine kundenspezifische Optimierung durchgeführt.
Hochverfügbarkeit unter verteilter Architektur

Community Native verteilte Architektur
ByteHouse folgte zunächst der verteilten Architektur der Clickhouse-Community, aber die verteilte Architektur weist einige natürliche architektonische Mängel auf, die sich hauptsächlich in drei Aspekten manifestieren:
-
Knotenfehler: Wenn die Anzahl der Clustermaschinen eine bestimmte Größenordnung erreicht, müssen Knotenfehler jede Woche manuell behandelt werden. Bei Single-Copy-Clustern kann ein Knotenausfall in einigen Extremfällen sogar zu Datenverlust führen.
-
Lese-Schreib-Konflikte: Aufgrund der Lese-Schreib-Kopplung der verteilten Architektur treten Ressourcenkonflikte bei Benutzerabfragen und Echtzeitimporten auf, wenn die Clusterlast ein bestimmtes Niveau erreicht – insbesondere CPU- und E/A-Importe werden beeinträchtigt und Es kommt zu Verbrauchsverzögerungen.
-
Erweiterungskosten: Da die Daten in der verteilten Architektur grundsätzlich lokal gespeichert werden, können die Daten nach der Erweiterung nicht neu gemischt werden.Die neu erweiterte Maschine hat fast keine Daten, und die Festplatte auf der alten Maschine kann fast voll sein, was zu einem ungleichmäßigen Cluster führt Last. , die zu einer Expansion führt, kann keine effektive Wirkung entfalten.
Dies sind die natürlichen Schmerzpunkte der verteilten Architektur, aber aufgrund ihrer natürlichen Nebenläufigkeitseigenschaften und der extremen Leistungsoptimierung beim Lesen und Schreiben von lokalen Festplattendaten kann gesagt werden, dass es Vor- und Nachteile gibt.
Community-Echtzeit-Importdesign
-
High-Level-Verbrauchsmodus: Verlassen Sie sich auf Kafkas eigenen Rebalance-Mechanismus für den Verbrauchslastausgleich.
-
zwei Ebenen der Parallelität
Das Echtzeit-Import-Core-Design, das auf einer verteilten Architektur basiert, ist eigentlich eine Parallelität auf zwei Ebenen:
Ein CH-Cluster hat normalerweise mehrere Shards, und jeder Shard wird gleichzeitig verbraucht und importiert, was die Multi-Prozess-Parallelität zwischen den Shards der ersten Ebene ist;
Jeder Shard kann auch mehrere Threads gleichzeitig verwenden, um einen hohen Leistungsdurchsatz zu erreichen.
-
Schreiben Sie in Stapeln
Bei einem einzelnen Thread besteht der grundlegende Verbrauchsmodus darin, in Stapeln zu schreiben – eine bestimmte Datenmenge zu verbrauchen oder sie nach einer bestimmten Zeit auf einmal zu schreiben. Das Batch-Schreiben kann eine Leistungsoptimierung erreichen, die Abfrageleistung verbessern und den Druck auf den Merge-Thread im Hintergrund verringern.
unerfüllte Bedürfnisse
Das Design und die Implementierung der oben genannten Communities können einige fortgeschrittene Bedürfnisse der Benutzer immer noch nicht erfüllen:
-
Zunächst einmal haben einige fortgeschrittene Benutzer relativ strenge Anforderungen an die Datenverteilung, sie haben beispielsweise bestimmte Schlüssel für bestimmte Daten und hoffen, dass die Daten mit demselben Schlüssel auf demselben Shard abgelegt werden (z. B. Anforderungen an eindeutige Schlüssel). In diesem Fall kann das Verbrauchsmodell der Community High Level nicht erfüllt werden.
-
Zweitens ist die Neuverteilung der Verbrauchsform auf hohem Niveau unkontrollierbar, was schließlich zu einer ungleichmäßigen Verteilung der in den Clickhouse-Cluster importierten Daten auf die verschiedenen Shards führen kann.
-
Natürlich ist die Zuweisung von Verbrauchsaufgaben unbekannt, und in einigen anormalen Verbrauchsszenarien wird es sehr schwierig, Probleme zu beheben; dies ist für eine Anwendung auf Unternehmensebene nicht akzeptabel.
Selbst entwickelte verteilte Architektur-Verbrauchs-Engine HaKafka
Um die oben genannten Anforderungen zu lösen, entwickelte das ByteHouse-Team eine Verbrauchs-Engine basierend auf der verteilten Architektur – HaKafka.
Hohe Verfügbarkeit (ha)
HaKafka erbt die Verbrauchsvorteile der ursprünglichen Kafka-Tabellen-Engine in der Community und konzentriert sich dann auf die hochverfügbare Ha-Optimierung.
Was die verteilte Architektur anbelangt, so kann es tatsächlich mehrere Kopien in jedem Shard geben, und HaKafka-Tabellen können auf jeder Kopie erstellt werden. Aber ByteHouse wählt nur einen Leader durch ZK aus, lässt den Leader den Verbrauchsprozess tatsächlich ausführen, und die anderen Knoten befinden sich im Stand-by-Zustand. Wenn der Leader-Knoten nicht verfügbar ist, kann ZK den Leader in Sekundenschnelle auf den Stand-by-Knoten umschalten, um den Verbrauch fortzusetzen, wodurch eine hohe Verfügbarkeit erreicht wird.
Low-Level-Verbrauchsmodus
Der Konsummodus von HaKafka wurde von High Level auf Low Level angepasst. Der Low-Level-Modus kann sicherstellen, dass Themenpartitionen geordnet und gleichmäßig auf jeden Shard im Cluster verteilt werden; gleichzeitig kann innerhalb des Shards wieder Multi-Threading verwendet werden, sodass jeder Thread unterschiedliche Partitionen verbrauchen kann. Somit übernimmt es vollständig die Vorteile der Zwei-Ebenen-Parallelität der Community-Kafka-Tabellen-Engine.
Im Low-Level-Verbrauchsmodus müssen die über HaKafka in Clickhouse importierten Daten gleichmäßig auf die Shards verteilt werden, solange die Upstream-Benutzer sicherstellen, dass beim Schreiben in das Thema keine Datenverzerrung auftritt.
Gleichzeitig für fortgeschrittene Benutzer, die spezielle Anforderungen an die Datenverteilung haben – das Schreiben der Daten desselben Schlüssels auf denselben Shard – solange der Upstream sicherstellt, dass die Daten desselben Schlüssels auf dieselbe Partition geschrieben werden, und dann ByteHouse importieren kann die Bedürfnisse des Benutzers vollständig erfüllen, und es ist sehr einfach, Szenarien wie eindeutige Schlüssel zu unterstützen.
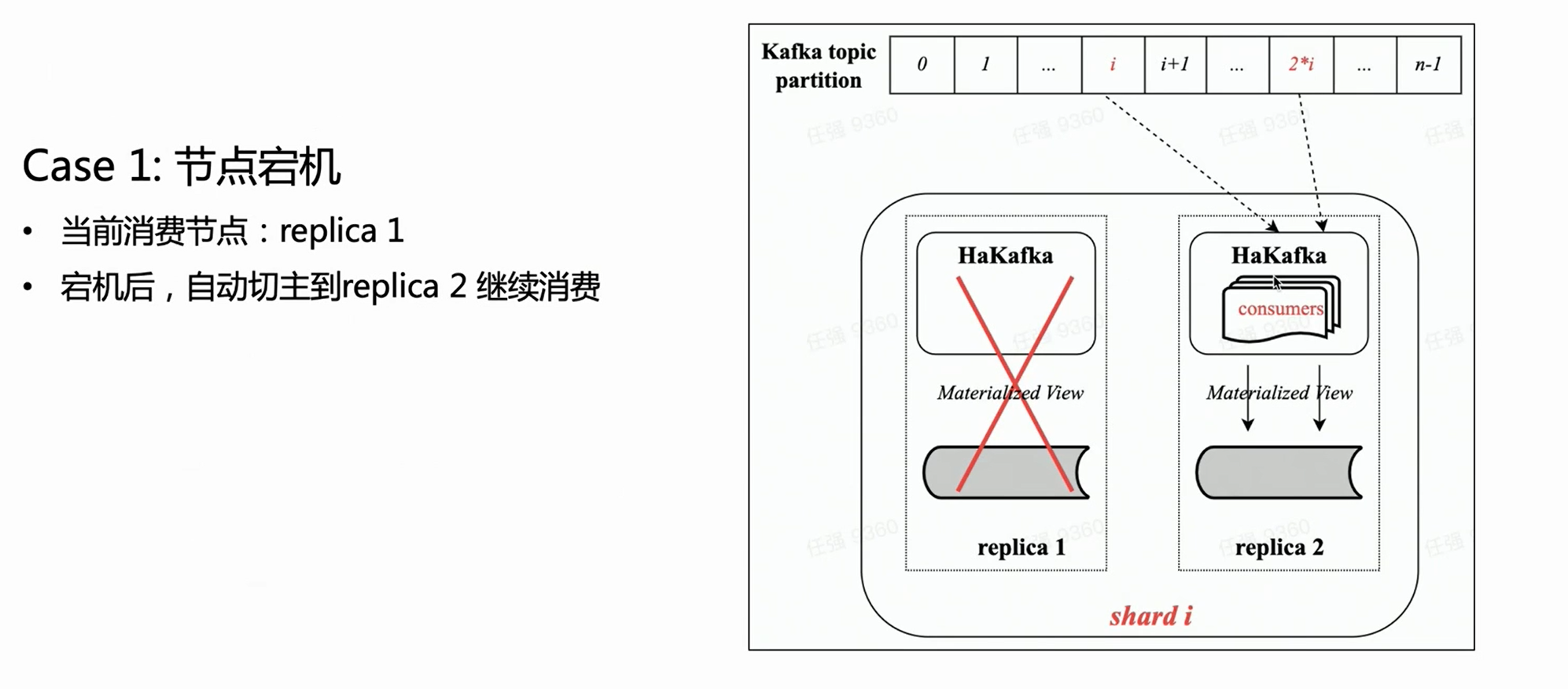
Szene eins:
Basierend auf der obigen Abbildung und unter der Annahme, dass ein Shard mit zwei Kopien vorhanden ist, hat jede Kopie dieselbe HaKafka-Tabelle im Status „Bereit“. Aber nur auf dem Leader-Knoten, der den Leader erfolgreich durch ZK gewählt hat, führt HaKafka den entsprechenden Verbrauchsprozess aus. Wenn der Leader-Knoten ausfällt, wird die Replica Replica 2 automatisch als neuer Leader wiedergewählt, um den Verbrauch fortzusetzen und so eine hohe Verfügbarkeit sicherzustellen.
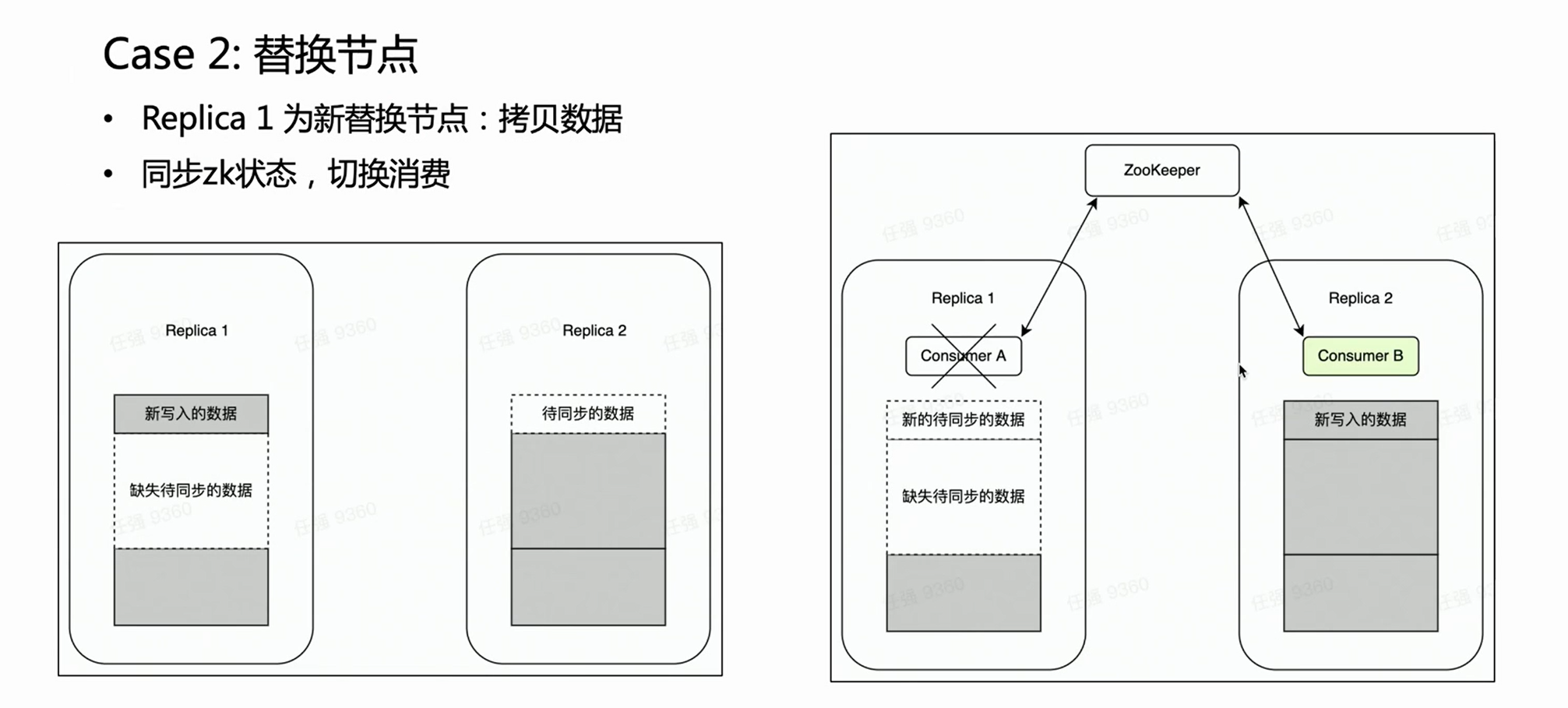
Szene zwei:
Im Falle eines Knotenausfalls ist es im Allgemeinen notwendig, den Prozess zum Ersetzen des Knotens durchzuführen. Es gibt eine sehr schwere Operation für das Ersetzen verteilter Knoten – das Kopieren von Daten.
Wenn es sich um einen Cluster mit mehreren Replikaten handelt, fällt eine Kopie aus und die andere Kopie ist intakt. Wir hoffen natürlich, dass während der Node-Replacement-Phase der Kafka-Verbrauch auf die intakte Replica Replica 2 gelegt wird, da die alten Daten darauf vollständig sind. Auf diese Weise ist Replica 2 immer ein vollständiger Datensatz und kann externe Dienste normal bereitstellen. HaKafka kann dies garantieren. Wenn HaKafka den Anführer wählt und festgestellt wird, dass ein bestimmter Knoten dabei ist, den Knoten zu ersetzen, wird es vermieden, als Anführer ausgewählt zu werden.
Leistungsoptimierung importieren: Speichertabelle
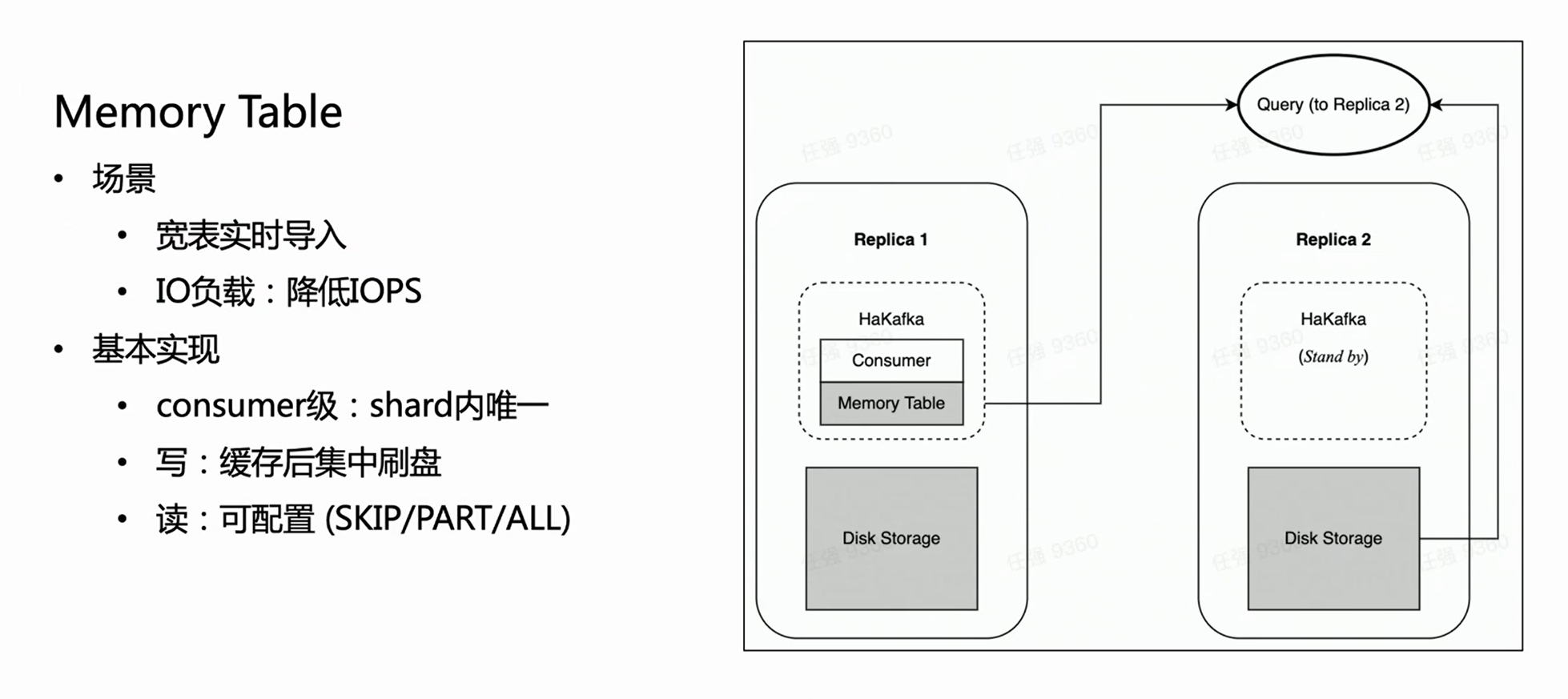
HaKafka optimiert auch die Memory Table.
Stellen Sie sich ein solches Szenario vor: Das Unternehmen hat eine große und breite Tabelle, die Hunderte von Feldern oder Tausende von Map-Keys enthalten kann. Da jede Spalte von ClickHouse einer bestimmten Datei entspricht, werden je mehr Spalten vorhanden sind, desto mehr Dateien werden für jeden Import geschrieben. Dann werden innerhalb der gleichen Verbrauchszeit häufig viele fragmentierte Dateien geschrieben, was die IO der Maschine stark belastet und gleichzeitig MERGE stark unter Druck setzt, in schweren Fällen sogar dazu führen, dass der Cluster nicht verfügbar ist. Um dieses Szenario zu lösen, haben wir Memory Table entwickelt, um die Importleistung zu optimieren.
Die Methode von Memory Table besteht darin, dass die importierten Daten jedes Mal nicht direkt geflasht, sondern im Speicher gespeichert werden; wenn die Daten eine bestimmte Menge erreichen, werden sie dann auf der Festplatte konzentriert, um IO-Operationen zu reduzieren. Die Speichertabelle kann einen externen Abfragedienst bereitstellen, und die Abfrage wird an die Kopie weitergeleitet, in der sich der Verbraucherknoten befindet, um die Daten in der Speichertabelle zu lesen, wodurch sichergestellt wird, dass die Verzögerung des Datenimports nicht beeinträchtigt wird. Nach der internen Erfahrung erfüllt Memory Table nicht nur einige geschäftliche Importanforderungen von großen und breiten Tabellen, sondern verbessert auch die Importleistung um das bis zu 3-fache.
Cloud-native neue Architektur
Angesichts der oben beschriebenen natürlichen Mängel der verteilten Architektur hat das ByteHouse-Team an der Aktualisierung der Architektur gearbeitet. Wir haben uns für die Cloud-native Architektur entschieden, die den Mainstream des Geschäfts darstellt. Die neue Architektur wird Anfang 2021 beginnen, das interne Geschäft von Byte zu bedienen, und den Code ( ByConity ) Anfang 2023 als Open Source bereitstellen .
Die Cloud-native Architektur selbst verfügt über eine natürliche automatische Fehlertoleranz und leichte Skalierungsfunktionen. Da seine Daten in der Cloud gespeichert werden, realisiert es gleichzeitig nicht nur die Trennung von Speicherung und Datenverarbeitung, sondern verbessert auch die Sicherheit und Stabilität der Daten. Natürlich ist die Cloud-native Architektur nicht ohne Schwächen: Die Änderung des ursprünglichen lokalen Lese- und Schreibzugriffs auf Remote-Lese- und -Schreibzugriff führt zwangsläufig zu einem gewissen Verlust an Lese- und Schreibleistung. Ein gewisser Leistungsverlust gegen die Rationalität der Architektur einzutauschen und die Kosten für Betrieb und Wartung zu reduzieren, wiegen die Nachteile jedoch tatsächlich auf.
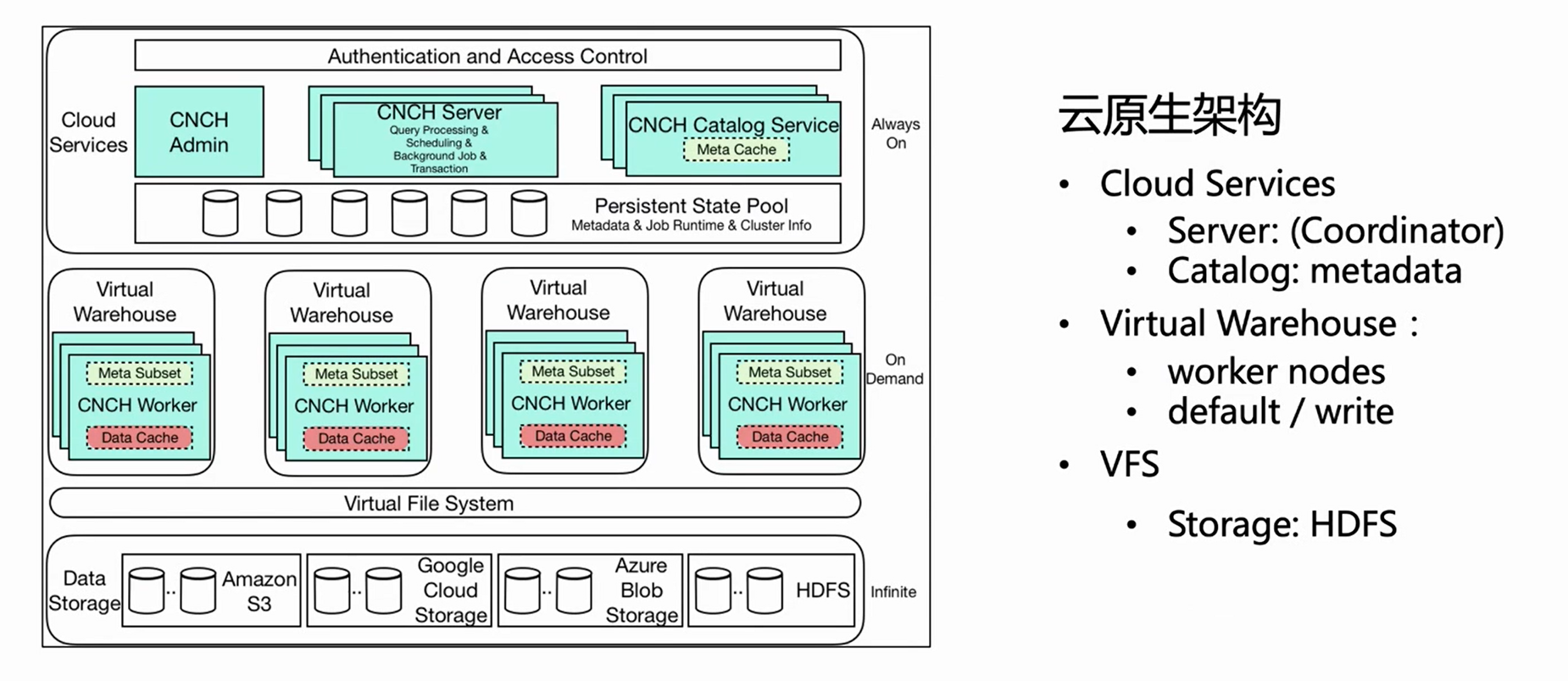
Das obige Bild stellt das Architekturdiagramm der Cloud-nativen Architektur von ByteHouse dar. Dieser Artikel stellt mehrere wichtige verwandte Komponenten für den Echtzeitimport vor.
-
Cloud-Dienst
Zunächst einmal ist die Gesamtarchitektur in drei Schichten unterteilt: Die erste Schicht ist Cloud Service, die hauptsächlich zwei Komponenten umfasst, Server und Catlog. Diese Schicht ist der Diensteingang, und alle Benutzeranforderungen, einschließlich Abfrageimporte, gehen vom Server ein. Der Server verarbeitet die Anforderung nur vor, führt sie jedoch nicht aus; nachdem Catlog die Metainformationen abgefragt hat, sendet er die vorverarbeitete Anforderung und die Metainformationen zur Ausführung an das Virtual Warehouse.
-
Virtuelles Lager
Virtual Warehouse ist die Ausführungsschicht. Verschiedene Unternehmen können unabhängige Virtual Warehouses haben, um eine Ressourcenisolation zu erreichen. Jetzt ist Virtual Warehouse hauptsächlich in zwei Kategorien unterteilt, eine ist Default und die andere Write.Default wird hauptsächlich für Abfragen verwendet, und Write wird für den Import verwendet, um die Trennung von Lesen und Schreiben zu realisieren.
-
VFS
Die unterste Schicht ist VFS (Datenspeicherung), die Cloud-Speicherkomponenten wie HDFS, S3 und aws unterstützt.
Echtzeit-Importdesign basierend auf Cloud-nativer Architektur
Bei der Cloud-nativen Architektur führt der Server keine spezifische Importausführung durch, sondern verwaltet nur Aufgaben. Daher wird auf der Serverseite jede Verbrauchstabelle einen Manager haben, um alle Verbrauchsausführungsaufgaben zu verwalten und ihre Ausführung im virtuellen Warenhaus zu planen.
Da er den Low-Level-Verbrauchsmodus von HaKafka erbt, verteilt der Manager Themenpartitionen gleichmäßig auf jede Aufgabe gemäß der konfigurierten Anzahl von Verbrauchstasks; die Anzahl der Verbrauchstasks ist konfigurierbar, und die Obergrenze ist die Anzahl der Themenpartitionen.
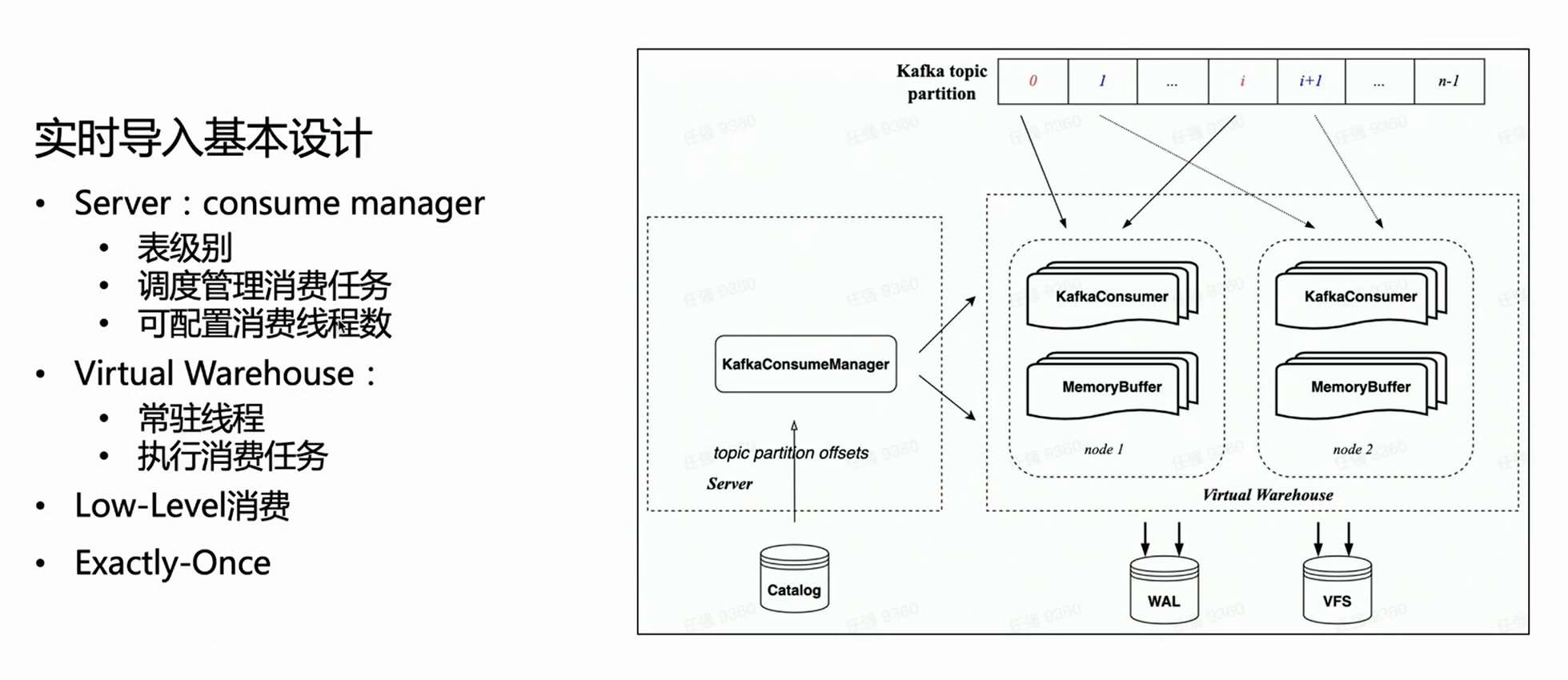
Anhand der obigen Abbildung können Sie sehen, dass der Manager auf der linken Seite den entsprechenden Offset aus dem Katalog erhält und dann die entsprechende Verbrauchspartition gemäß der angegebenen Anzahl von Verbrauchsaufgaben zuweist und sie für verschiedene Knoten des virtuellen Warenhauses einplant Ausführung.
Neuer Verbrauchsausführungsprozess
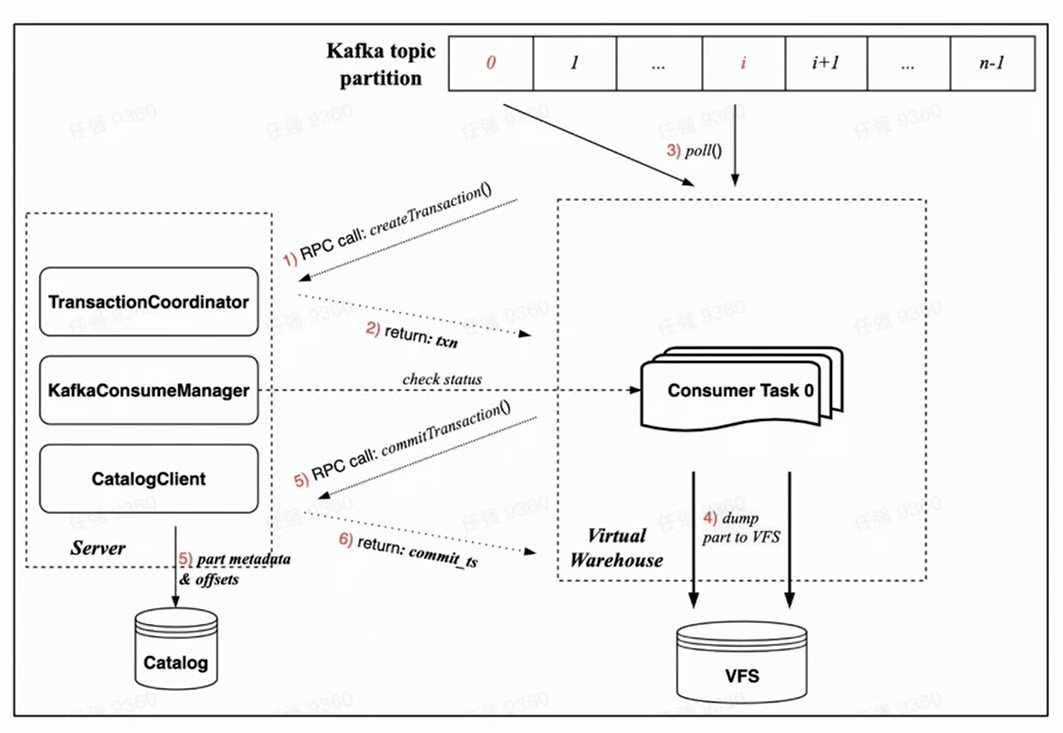
Da die neue Cloud-native Architektur von Transaction garantiert wird, wird erwartet, dass alle Vorgänge innerhalb einer Transaktion abgeschlossen werden, was rationaler ist.
Basierend auf der Implementierung von Transaction unter der neuen Cloud-nativen Architektur umfasst der Verbrauchsprozess jeder Verbrauchsaufgabe hauptsächlich die folgenden Schritte:
-
Bevor der Verbrauch beginnt, fordert die Aufgabe auf der Worker-Seite zuerst die Server-Seite auf, eine Transaktion über eine RPC-Anforderung zu erstellen;
-
Führen Sie rdkafka::poll() aus, um eine bestimmte Zeit (standardmäßig 8s) oder einen ausreichend großen Block zu verbrauchen;
-
Block in Teil konvertieren und in VFS ausgeben ( die Daten sind zu diesem Zeitpunkt nicht sichtbar );
-
Initiieren Sie eine Transaktions-Commit-Anforderung an den Server über eine RPC-Anforderung
(Commit-Daten in der Transaktion beinhalten: Dump-Metadaten des abgeschlossenen Teils und entsprechendes Kafka-Offset)
-
Die Transaktion wurde erfolgreich festgeschrieben ( Daten sind sichtbar )
Fehlertoleranzgarantie
Aus dem obigen Verbrauchsprozess können wir erkennen, dass die fehlertolerante Garantie des Verbrauchs unter der neuen Cloud-nativen Architektur hauptsächlich auf dem Zwei-Wege-Heartbeat von Manager und Task und der Fast-Failure-Strategie basiert:
-
Der Manager selbst wird regelmäßig prüfen und prüfen, ob die geplante Aufgabe normal über RPC ausgeführt wird;
-
Gleichzeitig verwendet jede Aufgabe die Transaktions-RPC-Anforderung, um ihre Gültigkeit während des Verbrauchs zu überprüfen.Sobald die Überprüfung fehlschlägt, kann sie automatisch beendet werden;
-
Sobald der Manager keine Lebendigkeit erkennt, startet er sofort eine neue Verbrauchsaufgabe, um eine Fehlertoleranzgarantie der zweiten Ebene zu erreichen.
Kaufkraft
Hinsichtlich der Verbrauchskapazität wurde oben erwähnt, dass sie skalierbar ist und die Anzahl der Verbrauchstasks vom Benutzer bis zur Anzahl der Partitionen des Themas konfiguriert werden kann. Bei hoher Node-Last im Virtual Warehouse kann der Node auch ganz leicht erweitert werden.
Natürlich implementiert die Manager-Planungsaufgabe die grundlegende Lastausgleichsgarantie – verwenden Sie den Ressourcen-Manager, um Aufgaben zu verwalten und zu planen.
Semantische Erweiterung: Genau – Einmal
Schließlich wurde auch die Verbrauchssemantik unter der neuen Cloud-nativen Architektur verbessert – von „At-Least-Once“ der verteilten Bucharchitektur zu „ Exactly-Once“.
Da die verteilte Architektur keine Transaktionen hat, kann sie nur At-Least-Once erreichen, was bedeutet, dass unter keinen Umständen Daten verloren gehen, aber in einigen Extremfällen kann es zu wiederholtem Verbrauch kommen. In der Cloud-nativen Architektur kann jeder Verbrauch dank der Implementierung von Transaction Part und Offset durch Transaktionen atomar festgeschrieben werden, um die semantische Verbesserung von Exactly-Once zu erreichen.
Speicherpuffer
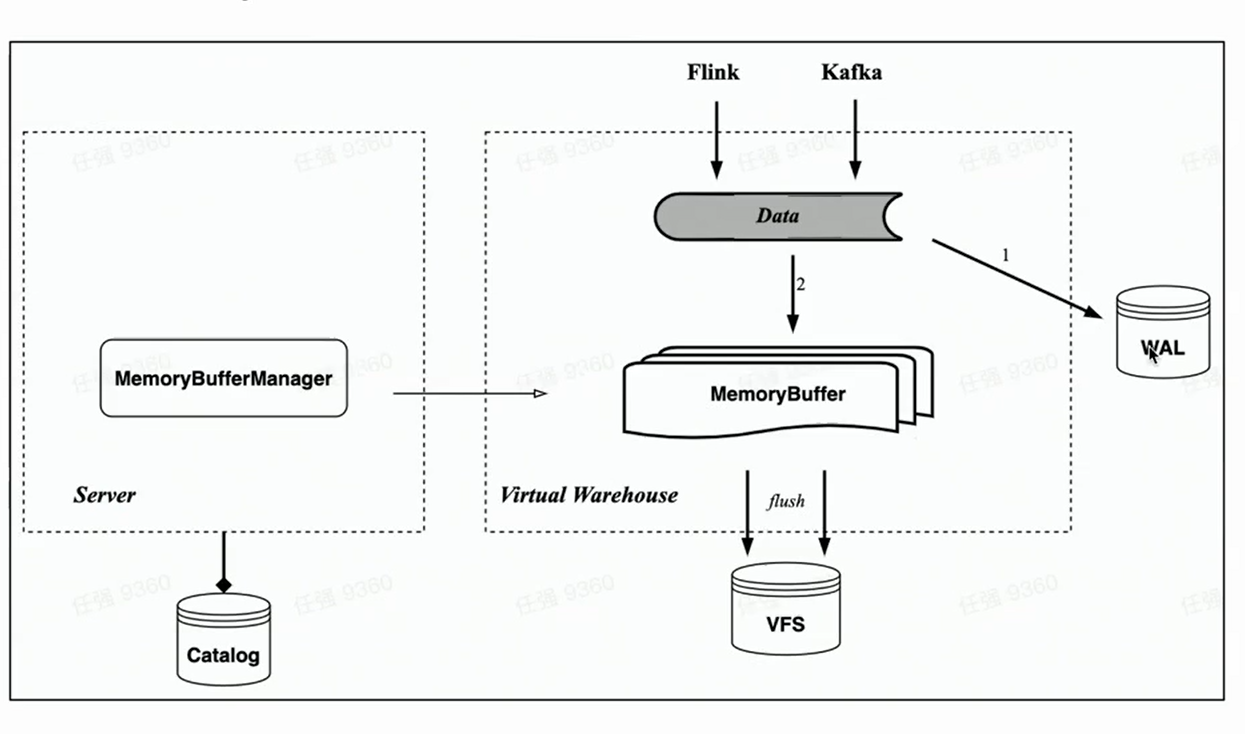
Entsprechend der Speichertabelle von HaKafka implementiert die Cloud-native Architektur auch den Import des Speichercaches Memory Buffer.
Im Gegensatz zu Memory Table ist Memory Buffer nicht mehr an die Verbrauchstasks von Kafka gebunden, sondern wird als Cache-Schicht für Speichertabellen implementiert. Auf diese Weise ist Memory Buffer vielseitiger und kann nicht nur für den Kafka-Import, sondern auch für den Small-Batch-Import wie Flink verwendet werden.
Gleichzeitig haben wir eine neue Komponente WAL eingeführt. Wenn Daten importiert werden, schreiben Sie zuerst WAL, solange das Schreiben erfolgreich ist, kann davon ausgegangen werden, dass der Datenimport erfolgreich war - wenn der Dienst gestartet wird, können Sie zuerst die nicht geflashten Daten aus der WAL wiederherstellen; dann Schreiben Sie den Speicherpuffer, und die Daten sind nach dem erfolgreichen Schreiben sichtbar ——Weil der Speicherpuffer von Benutzern abgefragt werden kann. Die Daten des Speicherpuffers werden ebenfalls regelmäßig geleert und können nach dem Leeren aus der WAL gelöscht werden.
Geschäftsanwendung und Zukunftsdenken
Abschließend wird kurz der aktuelle Stand des Echtzeit-Imports in Byte und die mögliche Optimierungsrichtung der Echtzeit-Import-Technologie der nächsten Generation vorgestellt.
Die Echtzeit-Importtechnologie von ByteHouse basiert auf Kafka, der tägliche Datendurchsatz liegt auf PB-Niveau und der Erfahrungswert des importierten Single-Thread- oder Single-Consumer-Durchsatzes liegt bei 10-20MiB/s. (Hier wird der Erfahrungswert betont, denn dieser Wert ist weder ein Festwert, noch ein Spitzenwert; der Verbrauchsdurchsatz hängt stark von der Komplexität der Benutzertabelle ab, mit zunehmender Anzahl der Tabellenspalten kann die Importleistung erheblich sein reduziert, Eine genaue Berechnungsformel kann nicht verwendet werden, daher ist der Erfahrungswert hier eher der Importleistungserfahrungswert der meisten Tabellen innerhalb des Bytes.)
Neben Kafka unterstützt Byte tatsächlich den Echtzeitimport einiger anderer Datenquellen, einschließlich RocketMQ, Pulsar, MySQL (MaterializedMySQL), Flink Direct Writing usw.
Einfache Gedanken zur nächsten Generation der Echtzeit-Import-Technologie:
-
Eine allgemeinere Echtzeit-Importtechnologie ermöglicht es Benutzern, mehr Importdatenquellen zu unterstützen.
-
Die Datentransparenz ist ein Kompromiss zwischen Latenz und Leistung.
Klicken Sie hier, um zum Cloud-nativen Data Warehouse von ByteHouse zu springen und mehr zu erfahren