Da immer mehr Unternehmensdaten gespeichert werden, ist der Widerspruch zwischen Speicherkapazität, Abfrageleistung und Speicherkosten ein häufiges Problem für technische Teams. Dieses Problem tritt besonders in den beiden Szenarien Elasticsearch und ClickHouse auf: Um die Anforderungen an die Abfrageleistung verschiedener heißer Daten zu erfüllen, verfügen diese beiden Komponenten über einige Strategien zur Schichtung von Daten im Architekturdesign.
Gleichzeitig hat sich im Hinblick auf Speichermedien mit der Entwicklung des Cloud Computing der Objektspeicher aufgrund seines niedrigen Preises und seines flexiblen Erweiterungsraums in die Gunst der Unternehmen gerückt. Immer mehr Unternehmen migrieren warme und kalte Daten auf Objektspeicher. Wenn die Index- und Analysekomponenten jedoch direkt mit dem Objektspeicher verbunden sind, treten Probleme wie Abfrageleistung und Kompatibilität auf.
Dieser Artikel stellt die Grundprinzipien des Hot- und Cold-Data-Tierings in diesen beiden Szenarien vor und erläutert, wie JuiceFS verwendet wird, um die im Objektspeicher vorhandenen Probleme zu lösen.
01- Detaillierte Erläuterung der Elasticsearch-Datenhierarchie
Bevor wir vorstellen, wie ES die Hot- und Cold-Data-Layering-Strategie implementiert, lassen Sie uns drei verwandte Konzepte verstehen: Data Stream, Index Lifecycle Management und Node Role.
Datenstrom
Data Stream (Datenstrom) ist ein wichtiges Konzept in ES, das die folgenden Merkmale aufweist:
- Streaming-Schreiben: Es handelt sich eher um einen im Stream geschriebenen Datensatz als um eine Sammlung mit fester Größe.
- Nur-Anhängen-Schreiben: Es aktualisiert die Daten durch Anhängen-Schreiben und muss die historischen Daten nicht ändern;
- Zeitstempel: Jedes neue Datenelement hat einen Zeitstempel, als es generiert wurde;
- Mehrere Indizes: Es gibt ein Indexkonzept in ES, und jedes Datenelement fällt schließlich in seinen entsprechenden Index, aber der Datenfluss ist ein übergeordnetes und umfassenderes Konzept, und hinter einem Datenfluss können viele Indizes stehen nach unterschiedlichen Regeln generiert. Obwohl ein Datenstrom aus vielen Indizes besteht, ist nur der neueste Index beschreibbar, und der historische Index ist schreibgeschützt, und sobald er verfestigt ist, kann er nicht geändert werden.
Protokolldaten sind eine Art von Daten, die den Eigenschaften von Datenströmen entsprechen. Sie werden nur angehängt und geschrieben, und sie müssen auch einen Zeitstempel haben. Benutzer werden neue Indizes basierend auf verschiedenen Dimensionen generieren, z. B. nach Tag oder nach anderen Dimensionen.
Die folgende Abbildung stellt ein einfaches Beispiel für die Datenflussindizierung dar. Während der Verwendung des Datenflusses schreibt ES direkt in den neuesten Index statt in den historischen Index, und der historische Index wird nicht geändert. Wenn in Zukunft mehr neue Daten generiert werden, wird dieser Index auch in einen alten Index übergehen.
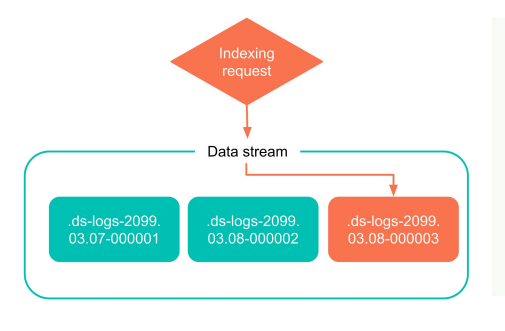
Wie in der folgenden Abbildung gezeigt, wird das Schreiben von Daten durch den Benutzer in ES grob in zwei Phasen unterteilt:
- Phase 1: Die Daten werden zuerst in den In-Memory-Puffer des Speichers geschrieben;
- Phase 2: Der Puffer fällt nach bestimmten Regeln und Zeiten auf die lokale Festplatte, was die grünen persistenten Daten in der Abbildung unten sind, die in ES als Segment bezeichnet werden.
Während dieses Vorgangs kann es zu einem gewissen Zeitunterschied kommen.Wenn Sie während des Persistenzvorgangs eine Abfrage auslösen, kann das neu erstellte Segment nicht durchsucht werden. Sobald das Segment beibehalten wird, kann es sofort von der oberen Abfragemaschine durchsucht werden.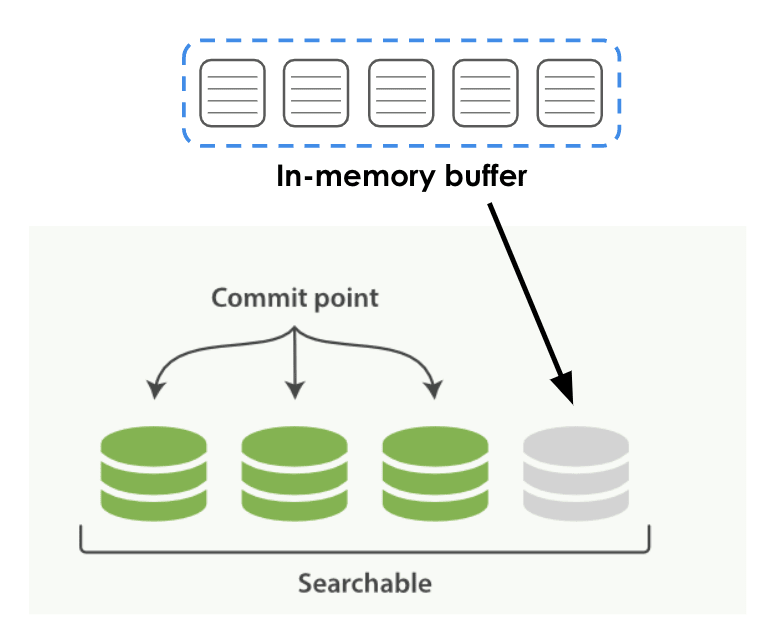
Verwaltung des Index-Lebenszyklus
Index Lifecycle Management, kurz ILM genannt, ist das Index-Lebenszyklusmanagement. ILM definiert den Lebenszyklus eines Index in 5 Phasen:
- Hot data (Hot): Daten, die häufig aktualisiert oder abgefragt werden müssen;
- Warme Daten (Warm): Daten, die nicht mehr aktualisiert werden, aber immer noch häufig abgefragt werden;
- Kalte Daten (Cold): Daten, die nicht mehr aktualisiert werden und eine geringe Abfragehäufigkeit aufweisen;
- Eingefrorene Daten: Daten, die nicht mehr aktualisiert und kaum abgefragt werden. Sie können diese Art von Daten sicher auf einem relativ langsamen und billigsten Speichermedium speichern.
- Daten löschen (Delete): Daten, die nicht mehr benötigt werden und getrost gelöscht werden können.
Die Daten in einem Index, egal ob es sich um einen Index oder ein Segment handelt, durchlaufen diese Phasen. Die Regeln dieser Klassifizierung helfen Benutzern, die Daten in ES sehr gut zu verwalten. Benutzer können selbst Regeln für verschiedene Phasen definieren.
Knotenrolle
In ES hat jeder Bereitstellungsknoten eine Knotenrolle, die die Knotenrolle ist. Jedem ES-Knoten werden unterschiedliche Rollen zugewiesen, z. B. Master, Daten, Ingest usw. Benutzer können Knotenrollen und die oben erwähnten Phasen der verschiedenen Lebenszyklen für das Datenmanagement kombinieren.
Datenknoten haben unterschiedliche Stufen, die ein Knoten sein können, der heiße Daten speichert, oder ein Knoten, der warme Daten, kalte Daten oder sogar extrem kalte Daten speichert. Es ist notwendig, Knoten entsprechend ihrer Funktionen unterschiedliche Rollen zuzuweisen und unterschiedliche Hardware für Knoten mit unterschiedlichen Rollen zu konfigurieren.
Beispielsweise müssen für heiße Datenknoten leistungsstarke CPUs oder Festplatten konfiguriert werden.Für warme und kalte Datenknoten gilt grundsätzlich, dass die Daten weniger häufig abgefragt werden.Zu diesem Zeitpunkt sind die Hardwareanforderungen für bestimmte Rechenressourcen eigentlich nicht so hoch..
Node-Rollen werden nach verschiedenen Stadien des Lebenszyklus definiert.Es ist zu beachten, dass jeder ES-Node mehrere Rollen haben kann, und diese Rollen nicht in einer Eins-zu-Eins-Entsprechung stehen. Hier ist ein Beispiel: Bei der Konfiguration in der YAML-Datei von ES stellt node.roles die Konfiguration von Knotenrollen dar. Sie können mehrere Rollen für diesen Knoten entsprechend den Rollen konfigurieren, die er haben sollte.
node.roles: ["data_hot", "data_content"]
Lebenszykluspolitik
Nachdem Sie die Konzepte von Data Stream, Index Lifecycle Management und Node Role verstanden haben, können Sie verschiedene Lebenszyklusrichtlinien für Daten erstellen.
Gemäß den Indexmerkmalen verschiedener Dimensionen, die in der Lebenszyklusrichtlinie definiert sind, wie z. B. die Größe des Index, die Anzahl der Dokumente im Index und der Zeitpunkt, zu dem der Index erstellt wurde, kann ES Benutzern dabei helfen, die Daten eines automatisch zu rollieren bestimmten Lebenszyklusphase zu einer anderen Phase. Der Begriff in ES ist Rollover.
Beispielsweise können Benutzer Funktionen basierend auf der Dimension der Indexgröße angeben, heiße Daten in warme Daten umwandeln oder gemäß einigen anderen Regeln warme Daten in kalte Daten umwandeln. Auf diese Weise werden beim Rollieren des Index zwischen verschiedenen Phasen des Lebenszyklus auch die entsprechenden indizierten Daten migriert und rolliert. ES kann diese Aufgaben automatisch ausführen, aber die Lebenszyklusrichtlinie muss vom Benutzer definiert werden.
Der folgende Screenshot ist die Verwaltungsoberfläche von Kibana, in der Benutzer Lebenszyklusrichtlinien grafisch konfigurieren können. Es ist ersichtlich, dass es drei Stufen gibt, von oben nach unten sind heiße Daten, warme Daten und kalte Daten.
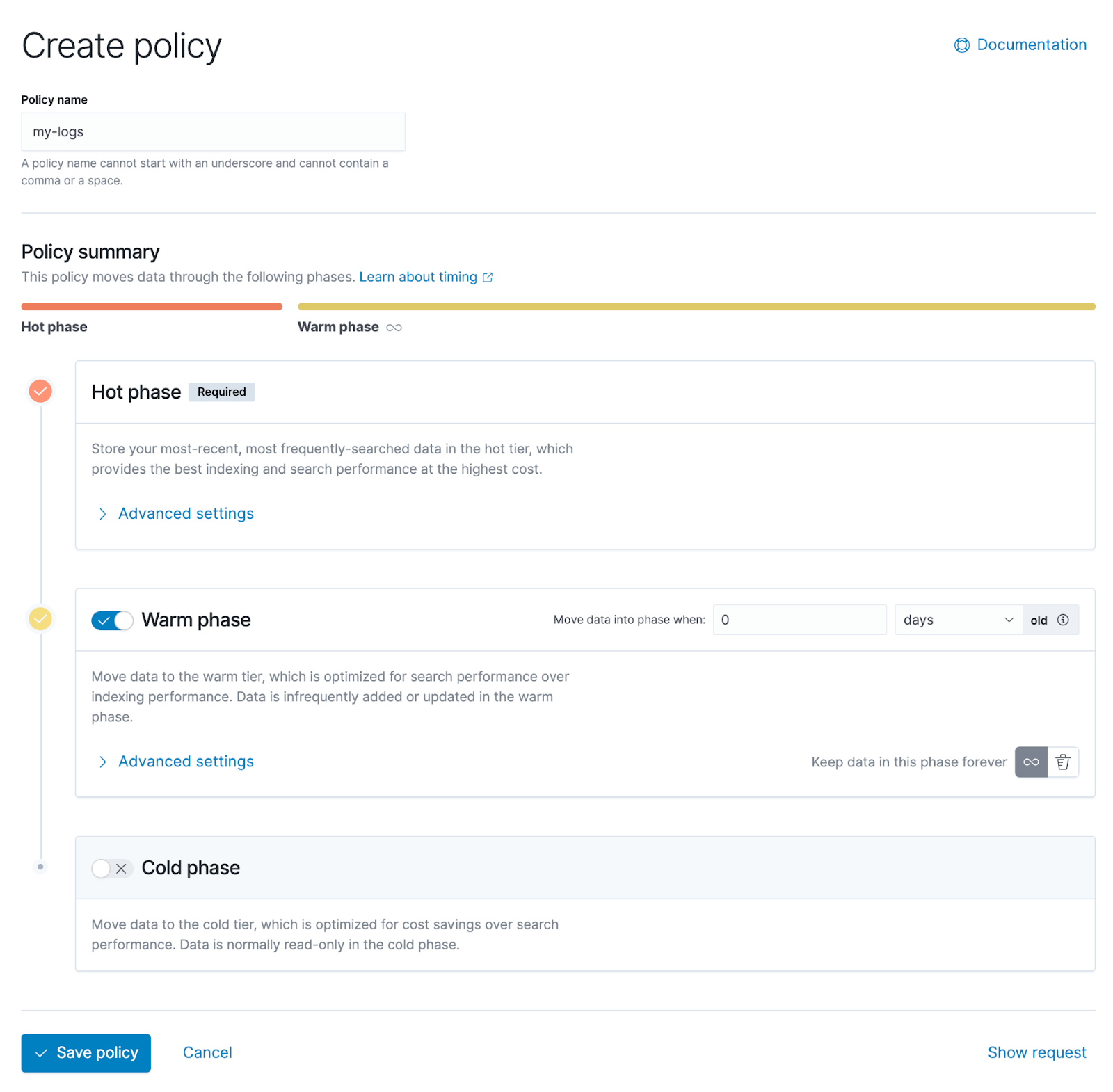
Erweitern Sie die erweiterten Einstellungen der Hot-Data-Stufe, und Sie können weitere Details sehen, die oben erwähnte Richtlinienkonfiguration basiert auf unterschiedlichen Dimensionsmerkmalen, wie z. B. die drei Optionen, die auf der rechten Seite der Abbildung unten zu sehen sind.
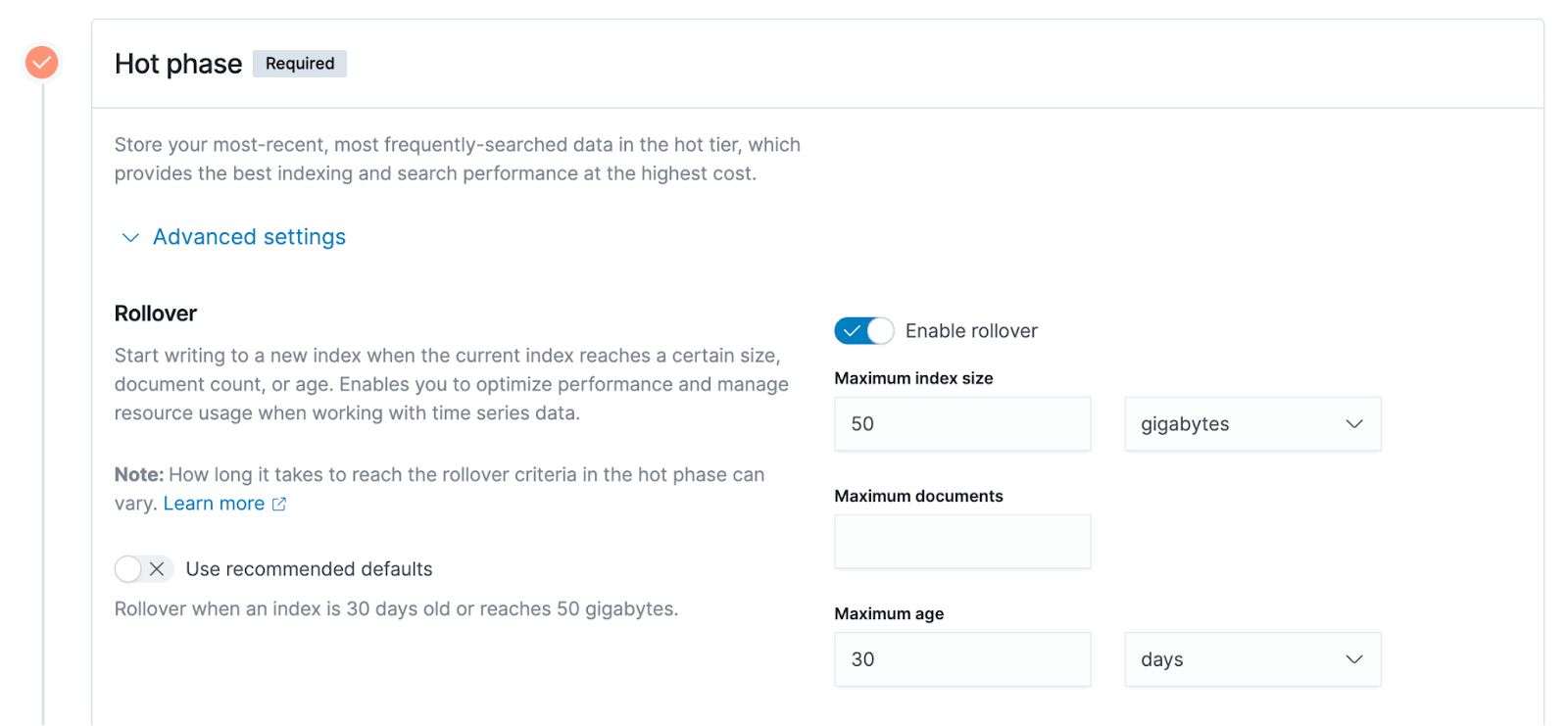
- Die Größe des Index, das Beispiel im Diagramm, beträgt 50 GB. Wenn die Größe des Index 50 GB überschreitet, wird er von der heißen Datenphase in die warme Datenphase verschoben.
- Die maximale Anzahl von Dokumenten, die Indexeinheit in ES ist Dokument, und Benutzerdaten werden in Form von Dokumenten in ES geschrieben, daher ist die Anzahl von Dokumenten auch ein messbarer Indikator.
- Die maximale Indexerstellungszeit. Das Beispiel hier ist 30 Tage. Angenommen, ein Index wurde 30 Tage lang erstellt. Zu diesem Zeitpunkt wird der soeben erwähnte Rollover von der heißen Datenphase zu warmen Daten ausgelöst.
02- Ausführliche Erläuterung der ClickHouse-Datenschichtarchitektur
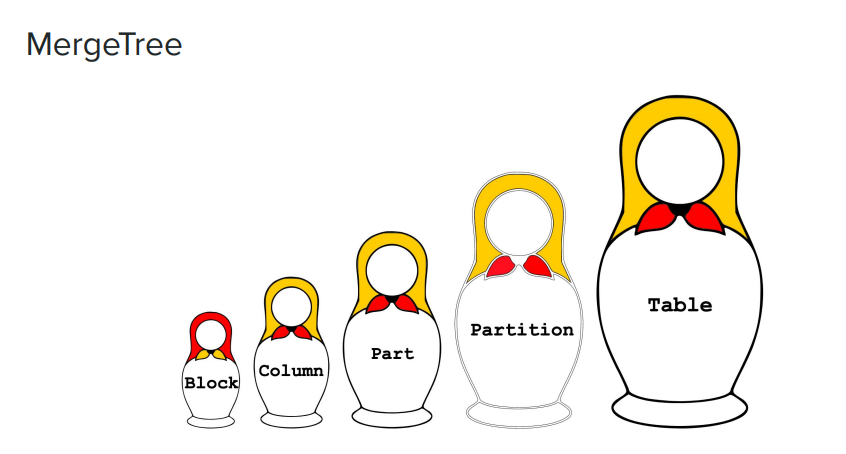
Das Bild unten ist eine Reihe russischer Nistpuppen von groß bis klein, die den Datenverwaltungsmodus von ClickHouse, der MergeTree-Engine, anschaulich zeigt.
- Tabelle: Ganz rechts im Bild befindet sich das größte Konzept, das erste, was Benutzer erstellen möchten oder auf das sie direkten Zugriff haben möchten, ist Tabelle;
- Partition: Es ist eine kleinere Dimension oder kleinere Granularität. In ClickHouse werden Daten zur Speicherung in Partitionen aufgeteilt, und jede Partition hat eine Kennung;
- Part: Jede Partition wird weiter in mehrere Parts unterteilt. Wenn Sie sich das auf der ClickHouse-Festplatte gespeicherte Datenformat ansehen, können Sie denken, dass jedes Unterverzeichnis ein Teil ist;
- Spalte: Im Teil sehen Sie einige kleinkörnigere Daten, nämlich Spalte. Die Engine von ClickHouse verwendet Spaltenspeicher, und alle Daten werden im Spaltenspeicher organisiert. Sie werden viele Spalten im Part-Verzeichnis sehen.Wenn es beispielsweise 100 Spalten in der Tabelle gibt, gibt es 100 Spaltendateien;
- Block: Jede Spaltendatei ist entsprechend der Granularität von Block organisiert.
Im folgenden Beispiel gibt es 4 Unterverzeichnisse unter dem Tabellenverzeichnis, und jedes Unterverzeichnis ist der oben erwähnte Teil.
$ ls -l /var/lib/clickhouse/data/<database>/<table>
drwxr-xr-x 2 test test 64B Aug 8 13:46 202208_1_3_0
drwxr-xr-x 2 test test 64B Aug 8 13:46 202208_4_6_1
drwxr-xr-x 2 test test 64B Sep 8 13:46 202209_1_1_0
drwxr-xr-x 2 test test 64B Sep 8 13:46 202209_4_4_
In der ganz rechten Spalte des Diagramms kann dem Namen jedes Unterverzeichnisses eine Zeit vorangestellt werden, z. B. 202208, was ein Präfix wie dieses ist, und 202208 ist eigentlich der Name der Partition. Partitionsnamen werden von Benutzern selbst definiert, aber gemäß Konventionen oder einigen Praktiken wird normalerweise Zeit für die Benennung verwendet.
Zum Beispiel hat die Partition 202208 zwei Unterverzeichnisse und die Unterverzeichnisse sind Parts.Eine Partition besteht normalerweise aus mehreren Parts. Wenn der Benutzer Daten in ClickHoue schreibt, werden diese zuerst in den Speicher geschrieben und dann entsprechend der Datenstruktur im Speicher auf der Festplatte gespeichert. Wenn die Daten in derselben Partition relativ groß sind, werden sie zu vielen Teilen auf der Festplatte. ClickHouse empfiehlt offiziell, nicht zu viele Teile unter einem Tisch zu erstellen, sondern Teile regelmäßig oder unregelmäßig zusammenzuführen, um die Gesamtzahl der Teile zu reduzieren. Das Konzept von Merge besteht darin, Teile zusammenzuführen, was einer der Ursprünge des Namens der MergeTree-Engine ist.
Lassen Sie uns Part anhand eines Beispiels verstehen. Es wird viele kleine Dateien in Part geben, von denen einige Metainformationen sind, z. B. Indexinformationen, um Benutzern das schnelle Auffinden von Daten zu erleichtern.
$ ls -l /var/lib/clickhouse/data/<database>/<table>/202208_1_3_0
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnA.bin
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnA.mrk
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnB.bin
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnB.mrk
-rw-r--r-- 1 test test ?? Aug 8 14:06 checksums.txt
-rw-r--r-- 1 test test ?? Aug 8 14:06 columns.txt
-rw-r--r-- 1 test test ?? Aug 8 14:06 count.txt
-rw-r--r-- 1 test test ?? Aug 8 14:06 minmax_ColumnC.idx
-rw-r--r-- 1 test test ?? Aug 8 14:06 partition.dat
-rw-r--r-- 1 test test ?? Aug 8 14:06 primary.id
Auf der rechten Seite des Beispiels sind die Dateien mit dem Präfix Column die eigentlichen Datendateien, die im Vergleich zu den Metainformationen normalerweise größer sind. In diesem Beispiel gibt es nur zwei Spalten, A und B, aber in der tatsächlichen Tabelle können viele Spalten vorhanden sein. Alle diese Dateien, einschließlich Metainformationen und Indexinformationen, arbeiten zusammen, um Benutzern zu helfen, schnell zwischen verschiedenen Dateien zu springen oder zwischen ihnen zu suchen.
ClickHouse-Speicherstrategie
Wenn Sie heiße und kalte Daten in ClickHouse schichten möchten, verwenden Sie eine Lebenszyklusrichtlinie ähnlich der in ES erwähnten, die in ClickHouse als Speicherrichtlinie bezeichnet wird.
ClickHouse unterscheidet sich geringfügig von ES und teilt Daten offiziell nicht in verschiedene Phasen wie heiße Daten, warme Daten und kalte Daten ein. ClickHouse stellt einige Regeln und Konfigurationsmethoden bereit, und Benutzer müssen Schichtungsstrategien selbst formulieren.
Jeder ClickHouse-Knoten unterstützt die Konfiguration mehrerer Festplatten gleichzeitig, und die Speichermedien können unterschiedlich sein. Beispielsweise konfigurieren allgemeine Benutzer SSD-Festplatten für ClickHouse-Knoten für Leistung; für einige warme und kalte Daten können Benutzer Daten auf kostengünstigeren Medien wie mechanischen Festplatten speichern. ClickHouse-Benutzer sind sich des zugrunde liegenden Speichermediums nicht bewusst.
Ähnlich wie bei ES müssen ClickHouse-Benutzer Speicherstrategien basierend auf unterschiedlichen Dimensionsmerkmalen der Daten formulieren, wie z. B. der Größe der einzelnen Teilunterverzeichnisse, dem Anteil des verbleibenden Speicherplatzes auf der gesamten Festplatte usw. Wenn die Bedingungen durch ein bestimmtes Dimensionsmerkmal festgelegt werden erfüllt sind, wird die Speicherung ausgelöst. Ausführung der Strategie. Diese Strategie migriert einen Teil von einer Festplatte auf eine andere. In ClickHouse haben mehrere von einem Knoten konfigurierte Laufwerke Priorität. Standardmäßig werden Daten auf das Laufwerk mit der höchsten Priorität fallen. Dadurch kann ein Teil von einem Speichermedium auf ein anderes übertragen werden.
Einige SQL-Befehle von ClickHouse, wie z. B. MOVE PARTITION/PART-Befehle, können die Datenmigration manuell auslösen, und Benutzer können mit diesen Befehlen auch einige Funktionsprüfungen durchführen. Zweitens kann es in manchen Fällen auch wünschenswert sein, den Teil explizit von dem aktuellen Speichermedium auf ein anderes Speichermedium durch manuelle statt automatische Übertragung zu übertragen.
ClickHouse unterstützt auch zeitbasierte Migrationsrichtlinien, ein von Speicherrichtlinien unabhängiges Konzept. Nachdem die Daten geschrieben wurden, löst ClickHouse die Datenmigration auf der Festplatte gemäß der durch das TTL-Attribut jeder Tabelle festgelegten Zeit aus. Wenn die TTL beispielsweise auf 7 Tage eingestellt ist, schreibt ClickHouse die Daten in der Tabelle mehr als 7 Tage von der aktuellen Festplatte (z. B. der Standard-SSD) auf eine andere Festplatte mit niedrigerer Priorität (z. B. JuiceFS).
03- Warme und kalte Datenspeicherung: Warum Objektspeicher + JuiceFS verwenden?
Nachdem Unternehmen warme und kalte Daten in der Cloud gespeichert haben, werden die Speicherkosten im Vergleich zur herkömmlichen SSD-Architektur erheblich reduziert. Unternehmen genießen auch den elastischen Skalierungsraum in der Cloud; sie müssen keine Betriebs- und Wartungsvorgänge für die Datenspeicherung durchführen, wie z. B. Erweiterung und Kontraktion, oder einige Datenbereinigungsarbeiten . Die benötigte Speicherkapazität für warme und kalte Daten ist viel größer als die für heiße Daten, zumal im Laufe der Zeit eine große Menge an Daten erzeugt wird, die lange gespeichert werden müssen.Wenn diese Daten lokal gespeichert werden, werden die entsprechende Betriebs- und Wartungsarbeiten werden überfordert.
Wenn jedoch Datenanwendungskomponenten wie Elasticsearch und ClickHouse auf Objektspeichern verwendet werden, treten Probleme wie schlechte Schreibleistung und Kompatibilität auf. Unternehmen, die die Abfrageleistung berücksichtigen möchten, begannen, nach Lösungen in der Cloud zu suchen. In diesem Zusammenhang wird JuiceFS zunehmend in Data-Layer-Architekturen eingesetzt .
Durch den folgenden ClickHouse-Schreibleistungstest können Sie den Leistungsunterschied beim Schreiben auf SSD, JuiceFS und Objektspeicher intuitiv verstehen.
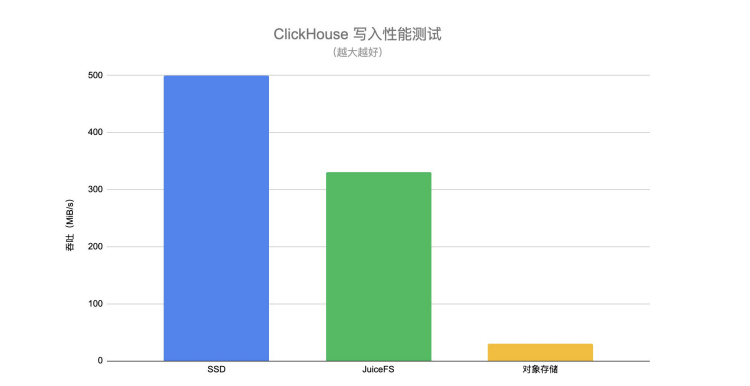
Der Schreibdurchsatz von JuiceFS ist viel höher als der von direkt angeschlossenem Objektspeicher und nahe dem von SSD . Wenn Benutzer heiße Daten in die warme Datenschicht übertragen, haben sie auch bestimmte Anforderungen an die Schreibleistung. Wenn während des Migrationsprozesses die Schreibleistung des zugrunde liegenden Speichermediums schlecht ist, wird der gesamte Migrationsprozess lange in die Länge gezogen, was auch einige Herausforderungen an die gesamte Pipeline oder das Datenmanagement mit sich bringt.
Der ClickHouse-Abfrageleistungstest in der folgenden Abbildung verwendet echte Geschäftsdaten und wählt mehrere typische Abfrageszenarien zum Testen aus. Unter ihnen sind q1-q4 Abfragen, die die gesamte Tabelle durchsuchen, und q5-q7 sind Abfragen, die den Primärschlüsselindex treffen. Die Testergebnisse sind wie folgt:
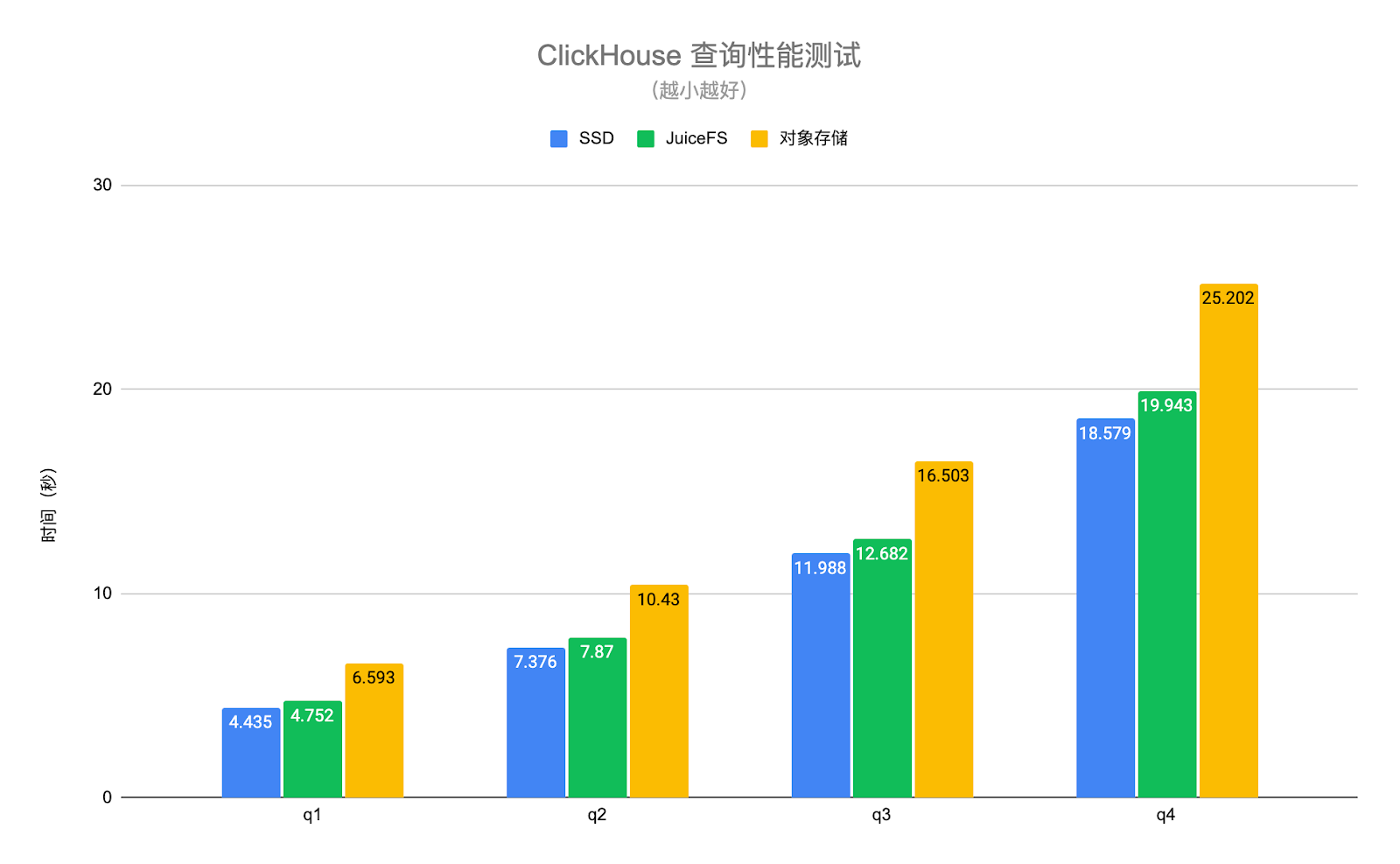
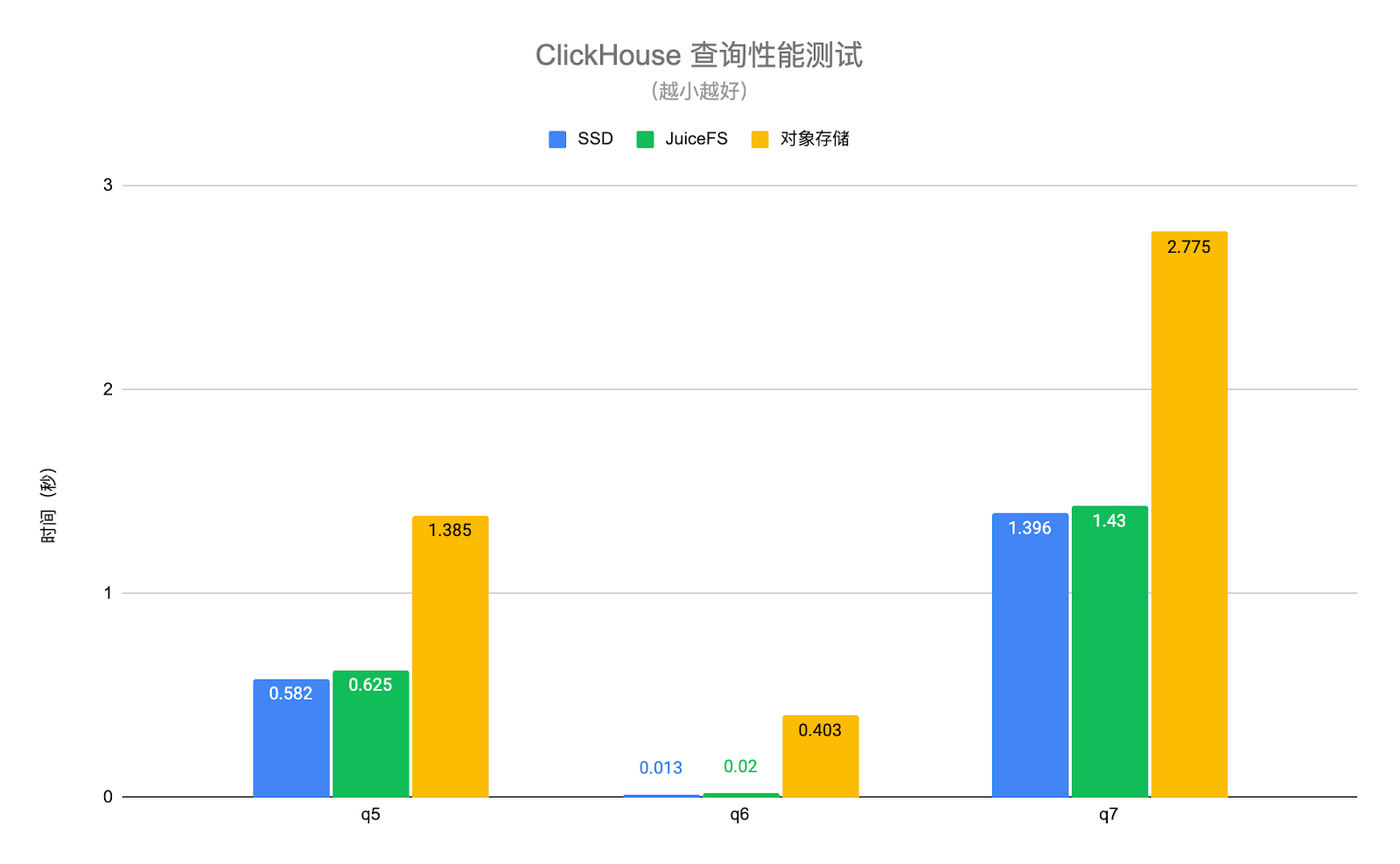
Die Abfrageleistung von JuiceFS- und SSD-Festplatten ist im Grunde gleich, mit einem durchschnittlichen Unterschied von etwa 6 %, aber die Leistung von Objektspeichern ist 1,4- bis 30-mal geringer als die von SSD-Festplatten . Dank der leistungsstarken Metadatenoperation und der lokalen Caching-Funktionen von JuiceFS können die für die Abfrageanforderung erforderlichen heißen Daten automatisch lokal auf dem ClickHouse-Knoten zwischengespeichert werden, wodurch die Abfrageleistung von ClickHouse erheblich verbessert wird. Zu beachten ist, dass auf den Objektspeicher im obigen Test über den S3-Datenträgertyp von ClickHouse zugegriffen wird, sodass nur die Daten auf dem Objektspeicher gespeichert werden und die Metadaten weiterhin auf dem lokalen Datenträger liegen. Wenn der Objektspeicher ähnlich wie S3FS lokal gemountet wird, wird die Leistung weiter beeinträchtigt.
Erwähnenswert ist auch, dass JuiceFS ein vollständig POSIX-kompatibles Dateisystem ist, das gut mit Anwendungen der oberen Schicht (wie Elasticsearch, ClickHouse) kompatibel ist. Benutzer wissen nicht, ob der zugrunde liegende Speicher ein verteiltes Dateisystem oder eine lokale Festplatte ist. Wenn die Objektspeicherung direkt verwendet wird, kann die Kompatibilität mit Anwendungen der oberen Schicht nicht gut erreicht werden.
04- Praktischer Betrieb: ES + JuiceFS
Schritt 1: Bereiten Sie mehrere Arten von Knoten vor und weisen Sie ihnen unterschiedliche Rollen zu . Jedem ES-Knoten können unterschiedliche Rollen zugewiesen werden, z. B. Speichern heißer Daten, warmer Daten, kalter Daten usw. Benutzer müssen Knoten verschiedener Modelle vorbereiten, um die Anforderungen verschiedener Rollen zu erfüllen.
Schritt 2: Mounten Sie das JuiceFS-Dateisystem . Im Allgemeinen verwenden Benutzer JuiceFS für die Speicherung warmer und kalter Daten. Benutzer müssen das JuiceFS-Dateisystem lokal auf ES-Knoten für warme oder kalte Daten mounten. Benutzer können den Einhängepunkt für ES über symbolische Links oder andere Methoden konfigurieren, sodass ES denkt, dass seine Daten in einem lokalen Verzeichnis gespeichert sind, aber hinter diesem Verzeichnis befindet sich tatsächlich ein JuiceFS-Dateisystem.
Schritt 3: Lebenszyklusrichtlinie erstellen . Dies muss von jedem Benutzer angepasst werden. Benutzer können entweder über die ES-API oder über Kibana erstellen. Kibana bietet einige relativ bequeme Möglichkeiten zum Erstellen und Verwalten von Lebenszyklusrichtlinien.
Schritt 4: Legen Sie eine Lebenszyklusrichtlinie für den Index fest . Nach dem Erstellen der Lebenszyklusrichtlinie muss der Benutzer diese Richtlinie auf den Index anwenden, d. h. die neu erstellte Richtlinie für den Index festlegen. Benutzer können Indexvorlagen in Kibana über Indexvorlagen erstellen oder sie explizit über die API über index.lifycycle.name konfigurieren.
Hier sind ein paar Tipps:
Tipp 1: Die Anzahl der Kopien (Replik) von Warm- oder Cold-Knoten kann auf 1 gesetzt werden . Alle Daten werden im Wesentlichen auf JuiceFS abgelegt, und die unterste Schicht ist Objektspeicher, sodass die Zuverlässigkeit der Daten bereits hoch genug ist, sodass die Anzahl der Kopien auf der ES-Seite entsprechend reduziert werden kann, um Speicherplatz zu sparen.
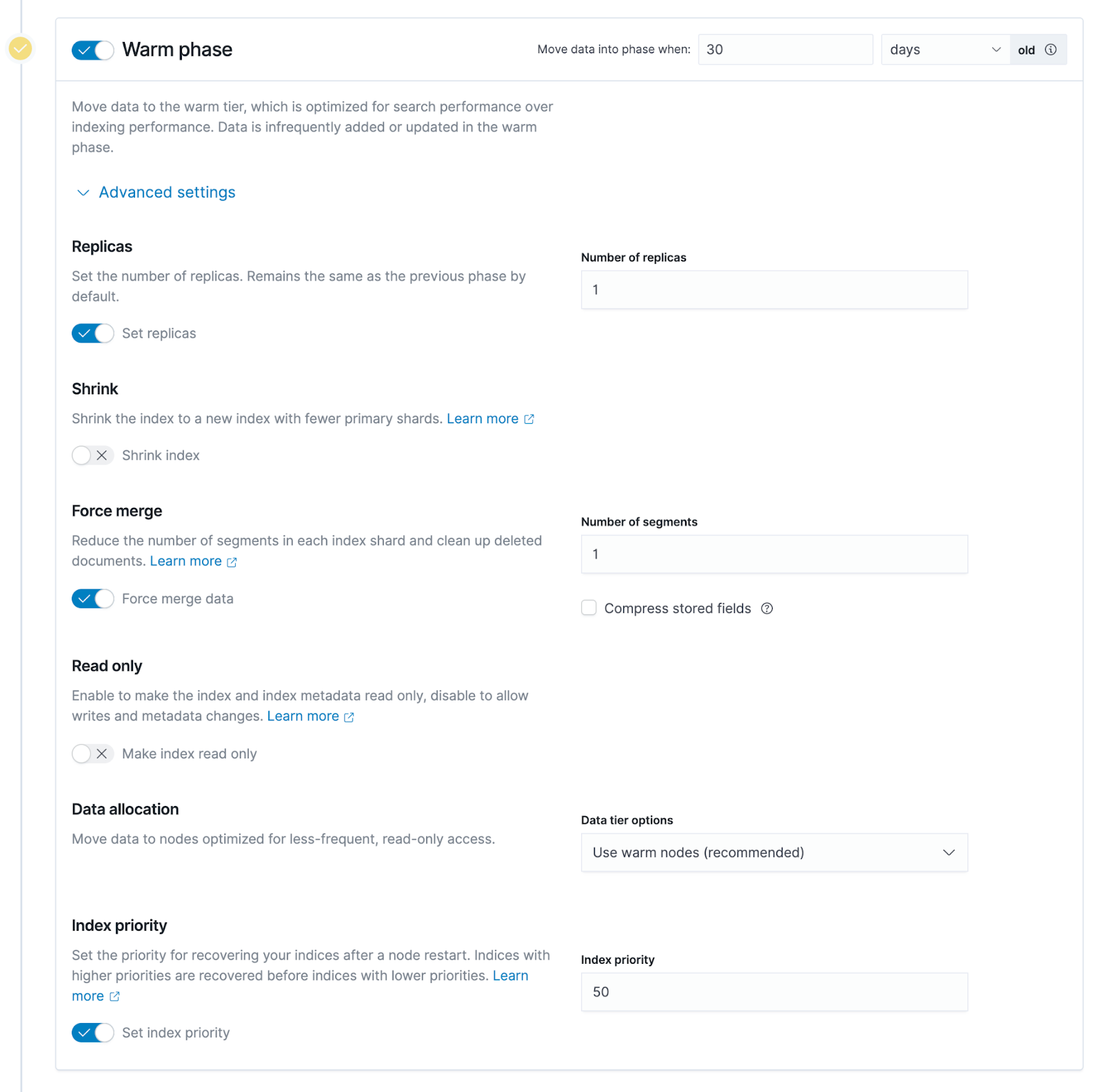
Tipp 2: Die Aktivierung von „Merge erzwingen“ kann dazu führen, dass die Knoten-CPU kontinuierlich belegt ist, schalten Sie sie also gegebenenfalls aus . Beim Übertragen von heißen Daten zu warmen Daten führt ES die zugrunde liegenden Segmente zusammen, die allen Indizes für heiße Daten entsprechen. Wenn die Funktion „Merge erzwingen“ aktiviert ist, führt ES diese Segmente zuerst zusammen und speichert sie dann im zugrunde liegenden System warmer Daten. Das Zusammenführen von Segmenten ist jedoch ein sehr CPU-intensiver Vorgang.Wenn die Datenknoten warmer Daten auch einige Abfrageanforderungen tragen müssen, können Sie diese Funktion entsprechend deaktivieren, dh die Daten intakt lassen und direkt in die darunter liegenden schreiben Lagerung.
Tipp 3: Indizes in der Warm- oder Cold-Phase können auf read-only gesetzt werden . Bei der Indizierung warmer und kalter Datenphasen können wir diese Daten grundsätzlich als schreibgeschützt betrachten, und die Indizes dieser Phasen werden nicht geändert. Wenn Sie es auf schreibgeschützt setzen, können Sie Ressourcen auf warmen und kalten Datenknoten ordnungsgemäß reduzieren, z. B. etwas Speicher freigeben, wodurch einige Hardwareressourcen auf warmen oder kalten Knoten eingespart werden.
05- Praktischer Betrieb: ClickHouse + JuiceFS
**Schritt 1: Mounten Sie das JuiceFS-Dateisystem auf allen ClickHouse-Knoten. **Dieser Pfad kann ein beliebiger Pfad sein, da ClickHouse über eine Konfigurationsdatei verfügt, die auf den Bereitstellungspunkt verweist.
**Schritt 2: Ändern Sie die ClickHouse-Konfiguration und fügen Sie eine JuiceFS-Festplatte hinzu. **Fügen Sie den neu gemounteten JuiceFS-Dateisystem-Mount-Punkt in ClickHouse hinzu, damit ClickHouse die neue Festplatte erkennen kann.
**Schritt 3: Fügen Sie eine Speicherrichtlinie hinzu und legen Sie die Regeln für das Senken von Daten fest. **Diese Speicherrichtlinie senkt gemäß den Benutzerregeln unregelmäßig und automatisch Daten von der Standardfestplatte auf die angegebene Festplatte, z. B. JuiceFS.
**Schritt 4: Legen Sie die Speicherrichtlinie und TTL für eine bestimmte Tabelle fest. **Nachdem die Speicherstrategie formuliert wurde, muss sie auf eine bestimmte Tabelle angewendet werden. In der frühen Phase des Testens und Verifizierens können relativ große Tabellen zum Testen und Verifizieren verwendet werden.Wenn Benutzer Daten basierend auf der Zeitdimension versenken möchten, müssen sie auch TTL für die Tabelle festlegen. Der gesamte Senkvorgang ist ein automatischer Mechanismus. Sie können den Teil, der gerade einer Datenmigration unterzogen wird, und den Migrationsfortschritt über die Systemtabelle von ClickHouse anzeigen.
**Schritt 5: Bewegen Sie das Teil manuell zur Überprüfung. ** Sie können den Befehl manuell ausführen, MOVE PARTITION um zu überprüfen, ob die aktuelle Konfiguration oder Speicherrichtlinie in Kraft ist.
Die folgende Abbildung ist ein konkretes Beispiel. In ClickHouse gibt es ein storage_configuration Konfigurationselement namens , das die Festplattenkonfiguration enthält. Hier wird JuiceFS als Festplatte hinzugefügt. Wir nennen es „jfs“, aber es kann mit einem beliebigen Namen gemountet werden Punkte sind /jfsVerzeichnisse.
<storage_configuration> <disks> <jfs> <path>/jfs</path> </jfs> </disks> <policies> <hot_and_cold> <volumes> <hot> <disk>default</disk> <max_data_part_size_bytes>1073741824</max_data_part_size_bytes> </hot> <cold> <disk>jfs</disk> </cold> </volumes> <move_factor>0.1</move_factor> </hot_and_cold> </policies></storage_configuration>
Weiter unten befindet sich das Konfigurationselement policies, das eine hot_and_cold Speicherrichtlinie namens definiert, und der Benutzer muss einige spezifische Regeln definieren, wie z zuerst heiß in der Volumes-Festplatte und der Standard-ClickHouse-Festplatte, normalerweise eine lokale SSD.
Die Konfiguration in Volumes max_data_part_size_bytes gibt an, dass, wenn die Größe eines bestimmten Teils die festgelegte Größe überschreitet, die Ausführung der Speicherrichtlinie ausgelöst wird und der entsprechende Teil auf das nächste Volume sinkt, d. h. das kalte Volume. Im obigen Beispiel ist das kalte Volume JuiceFS.
Die Konfiguration unten move_factor bedeutet, dass ClickHouse die Ausführung der Speicherrichtlinie gemäß dem Verhältnis des verbleibenden Speicherplatzes auf der aktuellen Festplatte auslöst.
CREATE TABLE test ( d DateTime, ...) ENGINE = MergeTree...TTL d + INTERVAL 1 DAY TO DISK 'jfs'SETTINGS storage_policy = 'hot_and_cold';
Wie im obigen Code gezeigt, können Sie, nachdem Sie über eine Speicherrichtlinie verfügen, storage_policy in SETTINGS auf die zuvor definierte hot_and_cold-Speicherrichtlinie setzen, wenn Sie eine Tabelle erstellen oder das Schema dieser Tabelle ändern. Die TTL in der vorletzten Zeile des obigen Codes ist die oben erwähnte zeitbasierte Schichtungsregel. In diesem Beispiel ist eine Spalte mit dem Namen d in der angegebenen Tabelle vom Typ DateTime.Die Kombination von INTERVAL 1 DAY bedeutet, dass, wenn neue Daten für mehr als einen Tag geschrieben werden, die Daten an JuiceFS übertragen werden.
06- Ausblick
**Zunächst die gemeinsame Nutzung von Kopien. **Ob es sich um ES oder ClickHouse handelt, sie haben mehrere Kopien, um die Verfügbarkeit und Zuverlässigkeit der Daten sicherzustellen. JuiceFS ist im Wesentlichen ein gemeinsam genutztes Dateisystem. Nachdem Daten in JuiceFS geschrieben wurden, müssen nicht mehrere Kopien aufbewahrt werden. Wenn der Benutzer beispielsweise zwei ClickHouse-Knoten hat, die beide Kopien einer bestimmten Tabelle oder eines bestimmten Teils haben, und beide Knoten in JuiceFS versenkt sind, kann es vorkommen, dass dieselben Daten zweimal geschrieben werden. ** Können wir in Zukunft die Engine der oberen Schicht darauf aufmerksam machen, dass die untere Schicht einen gemeinsam genutzten Speicher verwendet, und die Anzahl der Kopien reduzieren, wenn die Daten sinken, sodass Kopien zwischen verschiedenen Knoten geteilt werden können? ** Aus der Perspektive der Anwendungsschicht ist die Anzahl der Teile, wenn der Benutzer die Tabelle betrachtet, immer noch mehrere Kopien, aber tatsächlich wird nur eine Kopie auf dem zugrunde liegenden Speicher aufbewahrt, da die Daten im Wesentlichen geteilt werden können.
** Der zweite Punkt, Fehlerwiederherstellung. **Nachdem die Daten in einem Remote-Shared-Storage versenkt wurden, wenn der ES- oder ClickHousle-Knoten ausfällt, wie kann man sich schnell von dem Ausfall erholen? Die meisten Daten mit Ausnahme von heißen Daten wurden tatsächlich auf einen entfernten gemeinsam genutzten Speicher übertragen. Wenn Sie zu diesem Zeitpunkt einen neuen Knoten wiederherstellen oder erstellen möchten, sind die Kosten viel geringer als bei der herkömmlichen Wiederherstellungsmethode auf lokaler Festplattenbasis ist es wert, in ES- oder ClickHouse-Szenarien untersucht zu werden.
**Der dritte Punkt ist die Trennung von Speicherung und Berechnung. **Unabhängig von ES oder ClickHouse versucht oder untersucht die gesamte Community auch, wie diese traditionellen lokalen festplattenbasierten Speichersysteme zu einem echten Storage-Computing-Trennsystem in der Cloud-nativen Umgebung werden können. Bei der Storage-Computing-Trennung geht es jedoch nicht nur darum, Daten vom Computing zu trennen, sondern es müssen auch verschiedene komplexe Anforderungen der oberen Schicht erfüllt werden, beispielsweise Anforderungen an die Abfrageleistung, Anforderungen an die Schreibleistung und Anforderungen an die Optimierung verschiedener Dimensionen immer noch viele technische Schwierigkeiten, die es wert sind, in der allgemeinen Richtung der Bestandstrennung untersucht zu werden.
**Vierter Punkt, datenschichtige Untersuchung anderer Anwendungskomponenten der oberen Ebene. **Zusätzlich zu den beiden Szenarien von ES und ClickHouse haben wir kürzlich auch einige Versuche unternommen, die warmen und kalten Daten in Apache Pulsar in JuiceFS zu versenken. Einige der verwendeten Strategien und Lösungen ähneln den in diesem Artikel erwähnten nur dass in Apache Pulsar der Datentyp oder das Datenformat, das es aufnehmen muss, anders ist. Nach weiterem erfolgreichen Üben wird es geteilt.
Verwandte Lektüre: