
Autor | ANTI
Führung
Da die Konfrontation zwischen Anti-Cheating- und Cheating-Black-Produkten immer heftiger wird und sich die Cheat-Methoden mit jedem Tag ändern, versuchen wir auch ständig neue Methoden, um neue Cheat-Probleme zu lösen. Dieses Papier stellt hauptsächlich die Anwendung des Graphalgorithmus vor, um das Problem des Betrugs vom Community-Typ im Ereignisszenario zu lösen. Das Graphenmodell kann nicht nur die topologische Struktur des Graphen und die Eigenschaften der Knoten zum Lernen gleichzeitig integrieren, sondern auch als halbüberwachtes Modell unbeschriftete Daten besser nutzen und den Recall-Effekt verbessern. Sowohl das im Artikel erwähnte GCN-Graphenmodell als auch SCGCN (Multi-Graph Concatenation Model) haben gute Ergebnisse beim Cheat-Recall erzielt.
Der Volltext umfasst 4102 Wörter und die erwartete Lesezeit beträgt 11 Minuten.
01 Einführung
Operative Aktivitäten sind ein wichtiges Mittel für Unternehmen, um das Wachstum und die Bindung von Benutzern sicherzustellen, und sind auch eine der wichtigsten Wettbewerbsfähigkeiten von Unternehmen. Zu seinen Hauptformen gehören das Gewinnen neuer Benutzer und das Fördern der Aktivierung.Das Akquirieren neuer Benutzer bedeutet, neue Benutzer zu gewinnen, indem neue Benutzer von alten Benutzern eingeladen werden, um den Benutzerressourcenpool zu vergrößern; das Fördern der Aktivierung bedeutet, die DAU zu erhöhen und die Benutzerbindung zu erhöhen, indem Aufgaben erledigt werden. Zum Beispiel beteiligen wir uns normalerweise an der Aktivität, Aufgaben zu erledigen und rote Umschläge auf einer APP zu erhalten, was eine der spezifischen Formen von Betriebsaktivitäten ist. Durch die Kombination ihrer eigenen Produktmerkmale zur Durchführung operativer Aktivitäten können Unternehmen das Ziel erreichen, die Benutzerbindung und die Konversionsraten zu verbessern und dadurch das Unternehmenseinkommen und den Einfluss zu erhöhen. Es gibt auch verschiedene Aktivitäten in der Baidu APP, wie "Freunde einladen, um rote Umschläge zu erhalten", "Aufgaben erledigen, um rote Umschläge zu erhalten" usw. Es wird jedoch eine große Anzahl von Betrügern (z. B. Internet-Hackern) bei der Veranstaltung geben, um sich durch Betrug unrechtmäßige Vorteile zu verschaffen, die den Marketingeffekt der Veranstaltung beeinträchtigen. Zu diesem Zeitpunkt muss das Anti-Cheating-System schwarze Produkte durch mehrdimensionale Informationen wie Benutzerporträts, Benutzerverhalten und Geräteinformationen identifizieren, um die Betriebsaktivitäten des Unternehmens zu begleiten. In den letzten Jahren wurden mit der kontinuierlichen offensiven und defensiven Konfrontation zwischen Anti-Cheating und Schwarzindustrie auch die Betrugsmethoden der Schwarzindustrie schrittweise verbessert, von groß angelegtem computerbasiertem Betrug zu Crowdsourcing-Betrug und sogar kleinem Real- Person betrügen, was Anti-Cheaten ausmacht Die Schwierigkeit des Cheatens und der Identifizierung von Cheaten nimmt ebenfalls zu, daher müssen wir ständig neue Methoden entwickeln, um schwarze Produkte zu identifizieren und zu blockieren.
02 Schwierigkeit
Nehmen Sie bei den operativen Aktivitäten die Aktivität der Gewinnung von Neuankömmlingen als Beispiel. Bei Aktivitäten zum Ziehen neuer Typen wird nach erfolgter Einladung automatisch eine Beziehung zwischen Benutzern hergestellt, hier nennen wir es eine "Meister-Schüler-Beziehung" (der Einladende wird als "Meister" und der Eingeladene als "Lehrling" betrachtet "). Zum Beispiel ist Bild 3 ein Benutzerbeziehungsdiagramm, das durch die Operation „Neu einladen" erzeugt wird. Wir nennen die Charaktere der höheren Ebene die „Meister" der Charaktere der unteren Ebene und die Charaktere der unteren Ebene die „Lehrlinge" von die Charaktere der oberen Ebene. Auf dem Bild kann der Meister mehrere Lehrlinge rekrutieren und erhält gleichzeitig entsprechende Belohnungen – je mehr Lehrlinge, desto mehr Belohnungen.


△Bild 1 Einladungsaktivität für Freunde, Bild 2 Aktivität zum Nationalfeiertag
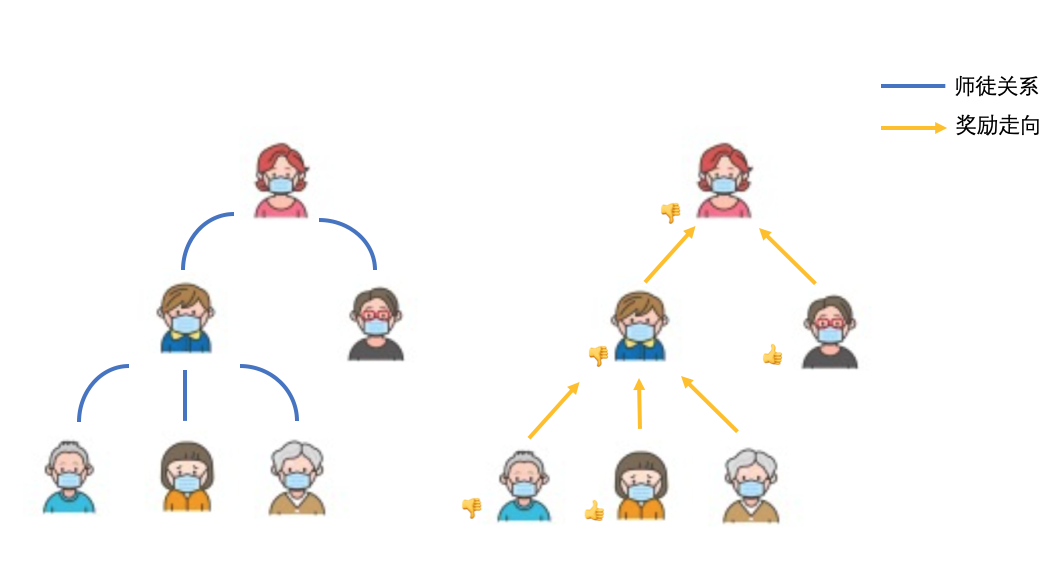
△Bild 3 Beschreibung der Beziehung zwischen den eingeladenen Ereignischarakteren
Gegenwärtig sieht sich die Anti-Cheating-Modellierung beim Erstellen neuer Szenarien mit den folgenden zwei Problemen konfrontiert:
1. Fehlende Fähigkeit, Kontaktinformationen zwischen Benutzern zu beschreiben : Das aktuelle Anwendungsmodell des Aktivitäten-Anti-Cheating-Geschäfts umfasst Baummodell, DNN und Modell für maschinelles Lernen. Wenn wir Benutzer als Knoten betrachten, werden wir feststellen, dass das Lernen und Trainieren dieser Modelle den Eigenschaften der Knoten selbst mehr Aufmerksamkeit schenkt, aber nicht in der Lage ist, die Eigenschaften der Beziehung zwischen Knoten zu lernen. Bei mehreren Cheat-Angriffen der letzten Zeit wurde festgestellt, dass die "Community" eine Form des Cheatens mit einem großangelegten Angriff als Basiseinheit darstellt. Sie teilen offensichtlich Verhaltens- und Ausrüstungsinformationen, und es besteht eine starke Korrelation zwischen den Informationen zwischen den Betrügern Wir brauchen bessere Modelle, um diese "Assoziations"-Fähigkeit zu erlernen.
2. Niedrige Probenreinheit führt zu eingeschränktem Rückruf : Im Allgemeinen werden schwarze Proben durch manuelle Probenauswertung und Anreicherung von Kundenbeschwerden erhalten, während weiße Proben in einem bestimmten Anteil durch Zufallsstichproben erhalten werden. Es gibt jedoch ein Problem, das auf diese Weise nicht einfach zu lösen ist, nämlich, dass diese weißen Proben mit unbekannten Schummeldaten gemischt werden können, was die Reinheit der weißen Proben verringert und den Trainingseffekt des überwachten Modells beeinträchtigt.
Im Folgenden stellen wir den Graphmodellalgorithmus vor, der die beiden oben genannten Probleme effektiv lösen kann.
03 Graph-Algorithmus-Anwendung
Um die beiden oben angesprochenen Geschäftsprobleme zu lösen, wird das Graph-Neuralnetzmodell für die Geschäftsmodellierung ausgewählt. Der Vorteil des Graphmodells besteht darin, dass es die topologische Struktur des Graphen und die Eigenschaften der zu lernenden Knoten gleichzeitig integrieren kann.Es kann nicht nur Informationen durch die zwischen Knoten hergestellte Kantenbeziehung verbinden, sondern die Lernfähigkeit des Modells ergänzen Kantenbeziehungen, wodurch der Recall erweitert wird, sondern auch als semi-überwachtes Modell kann das Graphenmodell unbeschriftete Daten besser nutzen und den Recall-Effekt verbessern.
3.1 Einführung in grafische Modelle
Die derzeit gebräuchlichen Graph-Neural-Network-Modelle lassen sich in zwei Kategorien einteilen: Die eine basiert auf Graph-Walk-Methoden wie Random-Walk-Walk-Modellen, die andere auf Graph-Convolution-Methoden wie GCN, GAT und GraphSAGE Isograph Convolutional Neural Netzwerkmodell. Aus der Perspektive des gesamten Graphen durchbricht GCN die Barrieren zwischen der ursprünglichen Graphstruktur und dem neuronalen Netzwerk, aber die enorme Menge an Berechnungen auf der Grundlage des gesamten Graphen führt dazu, dass es in groß angelegten Szenenanwendungen auf Engpässe stößt, während GraphSAGE aus der Perspektive von lokalen Graphen kann dieses Problem bis zu einem gewissen Grad lösen. Ein weiteres häufig verwendetes Graphenmodell, GAT, hat einen Aufmerksamkeitsmechanismus hinzugefügt.Mehr Modellparameter verbessern nicht nur die Lernfähigkeit, sondern erhöhen auch die zeitliche und räumliche Komplexität, wodurch das Modelltraining mehr ausreichende Beispielinformationen und Rechenressourcen erfordert. Da in realen Geschäftsszenarien die Stichprobengröße steuerbar ist, wird der GCN-Graphalgorithmus direkt für das Training ausgewählt.Im Folgenden wird das Prinzip von GCN kurz vorgestellt.
GCN ist ein Multi-Layer-Graph Convolutional Neural Network.Jede Convolutional Layer verarbeitet nur Nachbarschaftsinformationen erster Ordnung.Durch das Stapeln mehrerer Convolutional Layers kann eine Informationsübertragungin Multi-Order-Nachbarschaften erreicht werden.
Die Ausbreitungsregeln jeder Faltungsschicht lauten wie folgt [1]:
\(H^{(l+1)}=σ(\tilde{D}^{-{\frac 1 2}}\tilde{A}\tilde{D}^{-{\frac 1 2}}H ^{(l)}W^{(l)})\)
In
- \(\tilde{A}=A+I_{N} \) ist die Adjazenzmatrix des ungerichteten Graphen \(G\) plus Selbstzusammenhang (d. h. jede Ecke und sich selbst plus eine Kante), \(I_{ N} \) ist die Identitätsmatrix.
- \(\tilde{D}\) ist die Gradmatrix von \(\tilde{A} \) , also \(\tilde{D}{ii}=\sum_j\tilde{A}{ij}\)
- \(H^{(l)}\) ist die Aktivierungseinheitsmatrix der \(I\)- Schicht, \( H^0=X\)
- \(W^{(l)}\) ist die Parametermatrix jeder Schicht
Die Adjazenzmatrix \(A\) überträgt die Informationen der Nachbarn des Knotens und die Identitätsmatrix \(I_{N}\) stellt die Übertragung der eigenen Informationen des Knotens dar. Dadurch kann das GCN-Modell sowohl die lernen Eigenschaften des Knotens selbst und der ihm zugeordneten Informationen mit anderen Knoten und die Informationen von ihm selbst und benachbarten Knoten werden für das Training und Lernen aggregiert.
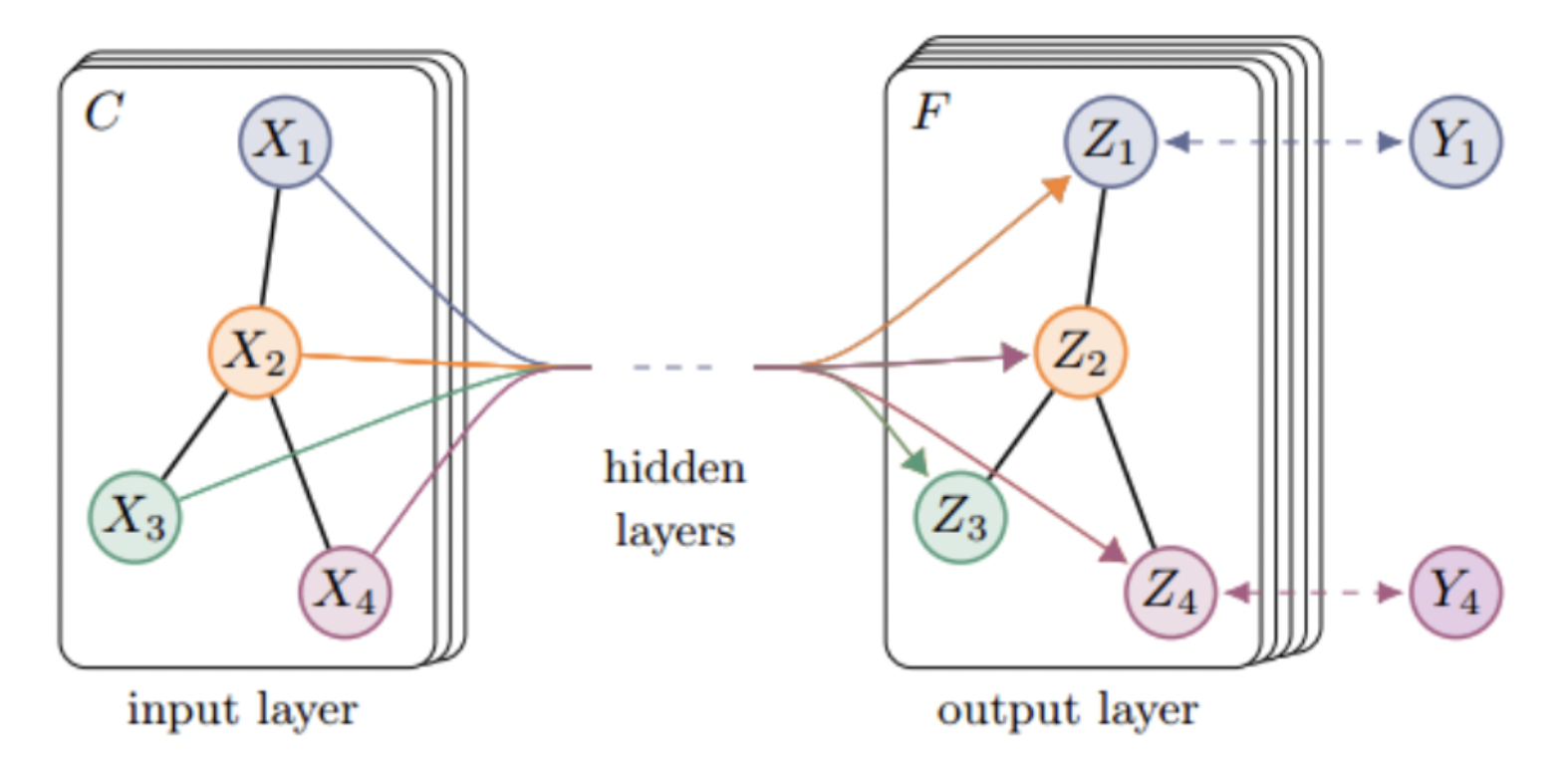
△Abb.4 Schematische Darstellung von GCN

△Abb.5 Beispiel
Als einer der Forschungs-Hotspots wurde das Gebiet der Graphen Neural Networks in den letzten Jahren in verschiedenen industriellen Szenarien weit verbreitet und erzielte gute Ergebnisse.
3.2 Graph-Algorithmus-Anwendung
3.2.1 GCN-Rückrufmodell basierend auf dem Betrugsszenario neuer Pull-Aktivitäten
Ziehen Sie neue Ereignisszenenmodellierung
Die neue Eventszene ist eine der wichtigsten Schummelszenen des Events. Am Beispiel des „Meister- und Lehrlings-Einladungsszenarios“, wenn der Master-Benutzer den Lehrlings-Benutzer erfolgreich einlädt, ein neuer Benutzer zu werden, erhalten sowohl der Master-Benutzer als auch der Lehrlings-Benutzer entsprechende Belohnungen. Die Schwarzindustrie wird Stapel gefälschter Lehrlingskonten verwenden, um dem Meister zu helfen, das Verhalten der Einladung neuer Schüler zu vervollständigen, um Vorteile zu erhalten. Durch statistische Analyse der Daten wurde festgestellt, dass diese falschen Lehrlinge IPs teilten und Modelle überlappten. Versuchen Sie auf dieser Grundlage, "Master User" als Basisknoten im Diagramm zu verwenden, und verwenden Sie jeweils "Stadt + Modell" und "IP+-Modell" als Kantenbeziehungen, um ein Diagrammmodell zu erstellen.
Abbildung zuschneiden
Da nicht alle Master, die sich IP-Modelle teilen, Betrugssignale haben, werden nur die Kanten, deren Gewicht größer als der Schwellenwert T ist, beibehalten, um den Effekt der Merkmalsverbesserung zu erzielen.
Modelleffekt

△Tabelle 1 Modelleffekte im Vergleich
Die experimentellen Ergebnisse zeigen, dass der GCN-Algorithmus einen signifikanten Effekt hat, indem er die Rückrufrate von betrügerischen Proben um 42,97 % erhöht.
3.2.2 Anwendungserforschung der Multi-Image-Fusion-Methode
Aus den obigen Experimenten ist ersichtlich, dass unterschiedliche Zusammensetzungsverfahren an unterschiedliche betrügerische Gruppen erinnern. Wenn Informationen über die Unterschiede zwischen diesen Gruppen miteinander verschmolzen würden, würde man mehr Recall erhalten? Versuchen Sie daher, einen effektiven Weg zu finden, um verschiedene Diagramminformationen in dasselbe Modell zu integrieren, um die Wiedererkennungsrate von Betrugsproben zu verbessern. Nach der Idee der Multi-Image-Fusion werden die folgenden drei Methoden vorgeschlagen, um jeweils Experimente durchzuführen.
Fusionsverfahren
Edge_union führt die beiden Bilder mit der Idee zusammen, "Bild A und Bild B in demselben Bild für Training und Lernen zu mischen", und auf diese Weise werden die in Bild A und Bild B enthaltenen Informationen miteinander verschmolzen.
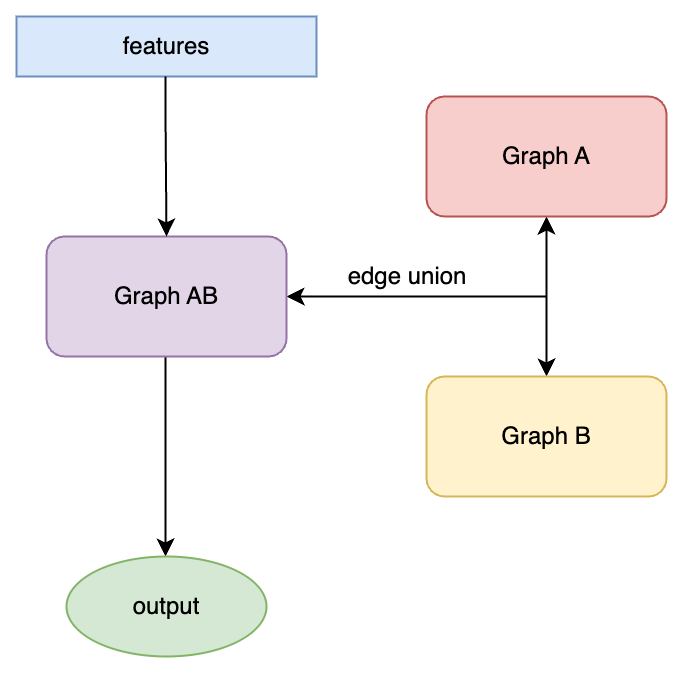
△Bild 6 edge_union-Modell
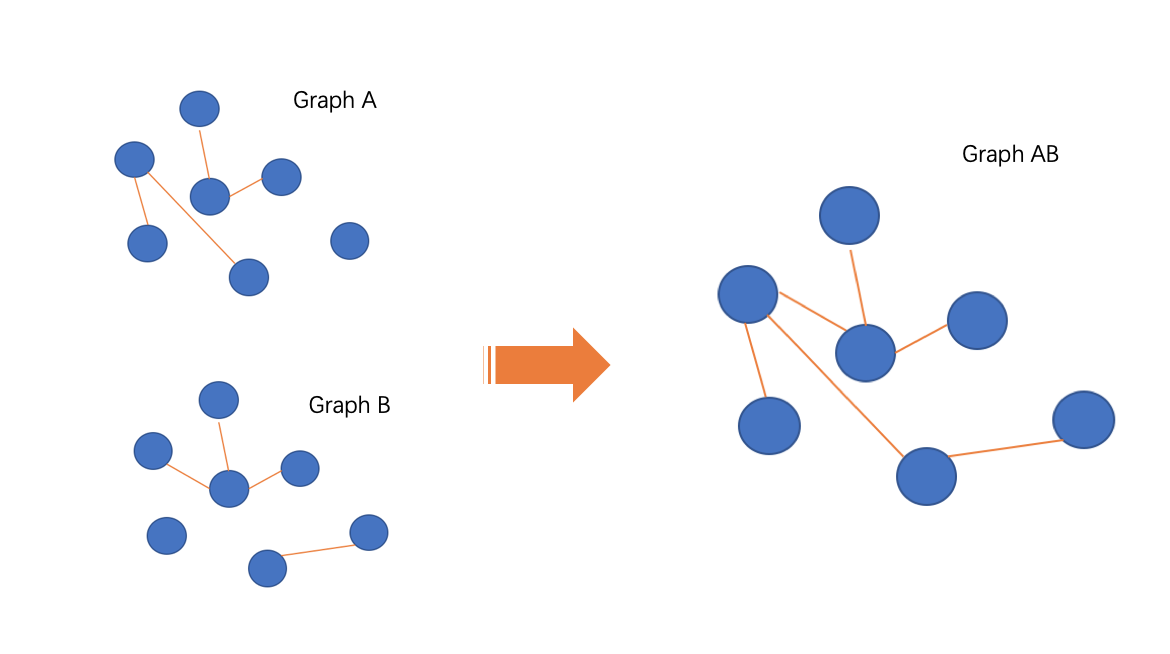
△Bild 7 edge_union Kompositionsmethode
scgcn-split- Einbettungsfunktionsvererbung
Die Idee der Verschmelzung der beiden Bilder besteht darin, „die eingebettete Darstellung des trainierten Bildes A als Eingabemerkmal von Bild B für das Training und Lernen zu nehmen“, und auf diese Weise werden die in Bild A und Bild B enthaltenen Informationen enthalten sein miteinander verschmolzen.
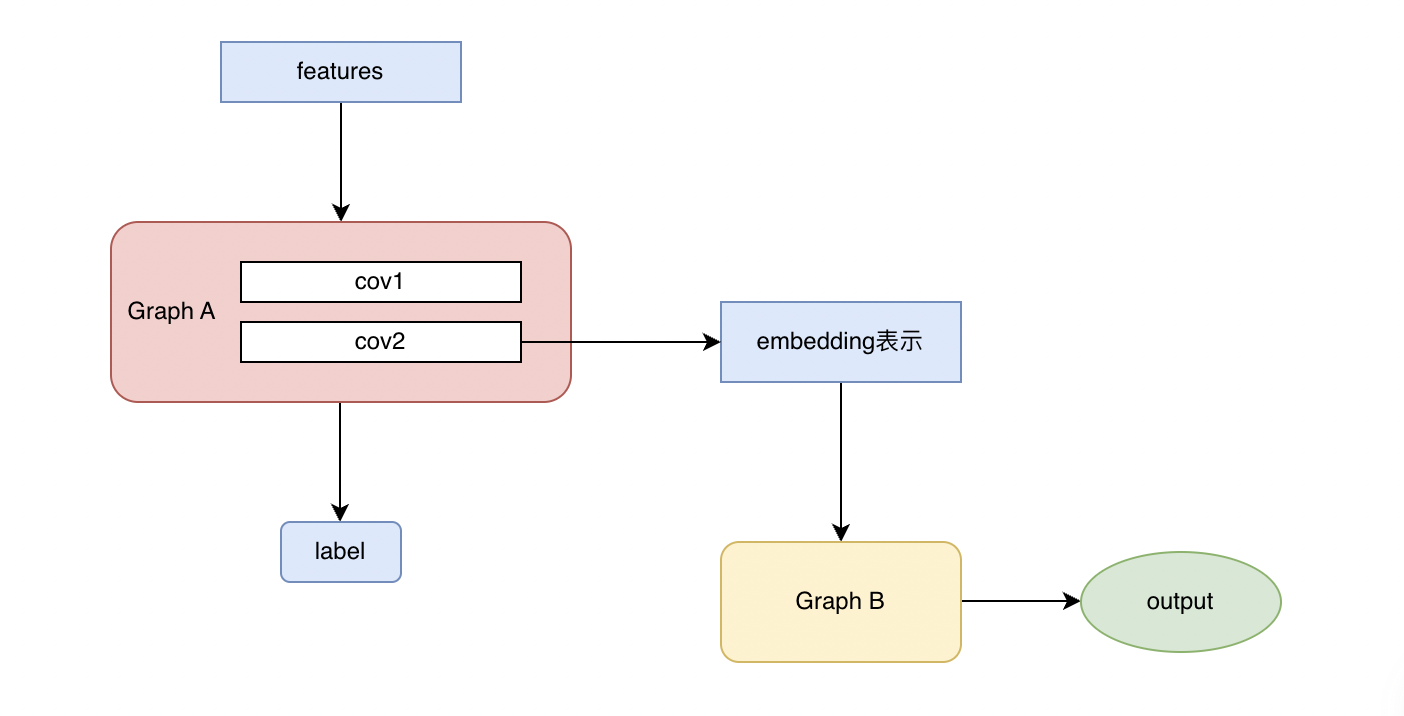
△Bild 8 Scgcn-Split-Modell
Scgcn Serial Graph Merge Training
Basierend auf dem Scgcn-Split- Schema werden Graph A und Graph B in Reihe geschaltet, um gleichzeitig zu trainieren und zu lernen.
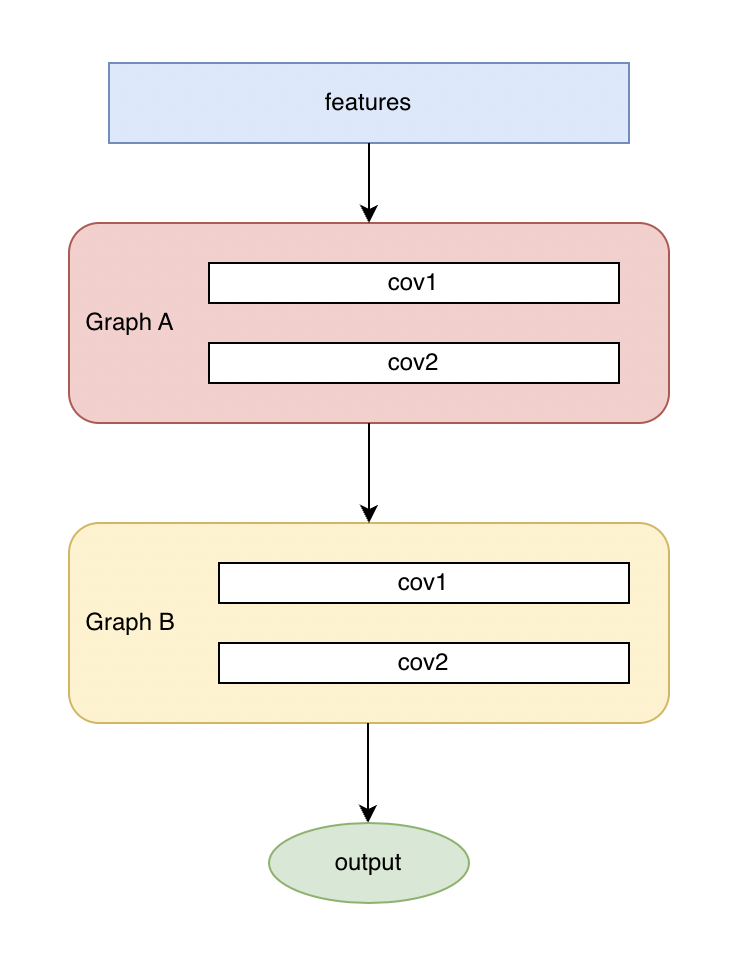
△Bild 9 scgcn-Modell
Modelleffekt
Im Folgenden sind die Ergebnisse des Leistungsvergleichs verschiedener Methoden für denselben Datensatz aufgeführt:

△Tabelle 2 Modelleffekte im Vergleich
In Bezug auf die Größe des neuen Abrufs ist die scgcn-Methode die beste, da sie die meisten betrügerischen Proben zurückruft; die edge_union-Methode schneidet schlecht ab und ihre Abrufgröße ist nicht einmal so gut wie das GCN-Einzelbild. Analysieren Sie einfach den Grund: Die edge_union-Methode verschmilzt verschiedene Arten von Kanten in derselben Graphstruktur, wobei Art und Wichtigkeit von Kanten nicht unterschieden werden, was einer Homogenisierung der Kanten des Graphen gleichkommt, wodurch einige Kanteninformationen verloren gehen. Aus dem Experiment ging dadurch ein Teil des Rückrufs verloren. Gleichzeitig ist das edge_union-Modell durch semi-überwachte Lernszenarien und unzureichende Probenreinheit begrenzt, da es beim Hinzufügen von Edge-Verbindungen zwischen Knoten auch das Risiko birgt, falsche Informationen zu übertragen. Zusätzlich zu den obigen Experimenten wurden Verfahren zur Bildfusion wie concat/max-pool/avg-pool auch auf der Einbettungsschicht ausprobiert.Diese Verfahren weisen alle Erinnerungsverluste auf, was darauf hindeutet, dassdas "parallele" Bildfusionsverfahren dies nicht ermöglichen kann Modell, um mehr zu erfahren, Informationen hingegen werden aufgrund des gegenseitigen Ausschlusseffekts des Informationsverlusts abgerufen. Effektiver erscheint dagegen die Methode der "seriellen" Graphenfusion. Sowohl scgcn-split als auch scgcn haben mehr Recall als das Single-Image-Modell, insbesondere das scgcn-Modell, das die Multi-Image-Parameter gleichzeitig trainiert, kann die Multi-Image-Informationen wirklich zusammen integrieren und erinnert sich an mehr als das Single-Image-Modell. Modellrückruf Union Viele Proben.
04 Zusammenfassung und Ausblick
Verglichen mit dem traditionellen Modell kann das Graphmodell nicht nur Knoteninformationen erhalten, sondern auch die Beziehungsinformationen zwischen Knoten erfassen. Durch die zwischen den Knoten hergestellte Kantenbeziehung werden die Informationen miteinander verbunden, und es werden mehr Informationen erlernt, wodurch der Abruf erweitert wird. In der Anti-Betrugs-Meister-Lehrlings-Aktivitätsszene der neuen Werbeaktivität werden durch die Anwendung des Graphalgorithmus die neu abgerufenen Betrugsproben auf der Grundlage der ursprünglichen Betrugsproben um 50% erhöht und die Erinnerungsrate wird stark verbessert .
In Zukunft werden weitere Explorationen in die folgenden Richtungen durchgeführt:
1. Aus der bisherigen Arbeit ist ersichtlich, dass die Kantenbeziehung eine wichtige Rolle beim Lernen des Graphenmodells spielt. Das Kantengewicht wird später verarbeitet und gelernt, und auch die Knoteninformationen werden ergänzt. Durch Hinzufügen von Dateninformationen und effektive Funktionen, das Modell wird verbessert.
2. Mit der kontinuierlichen Verbesserung der Betrugsmethoden geht die Form des Betrugs allmählich von der Maschinenbedienung zur Bedienung durch Menschen über, und das Ausmaß des Betrugs wird reduziert, was zu spärlichen Betrugsmerkmalen führt und die Schwierigkeit der Identifizierung erhöht. In Zukunft werden weitere Graphalgorithmen ausprobiert, wie das GAT[2]-Modell, das den Aufmerksamkeitsmechanismus einführt, das Deepgcn[3]-Modell, das mehrschichtige Netzwerke stapeln kann usw., um die Empfindlichkeit der Betrugserkennung zu verbessern.
--ENDE--
Referenzen :
[1]Kipf, Thomas N. und Max Welling. "Semi-überwachte Klassifizierung mit Graph-Faltungsnetzen." arXiv-Vordruck arXiv:1609.02907 (2016).
[2] Veličković, Petar, et al. "Aufmerksamkeitsnetzwerke grafisch darstellen." arXiv-Vordruck arXiv:1710.10903 (2017).
[3]Li, Guohao, et al. "Deepgcns: Können gcns so tief gehen wie cnns?." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
Empfohlene Lektüre :
Serverlos: Flexible Skalierungspraxis basierend auf personalisierten Serviceportraits
Aktionszerlegungsmethode in der Bildanimationsanwendung
Performance Platform Data Acceleration Road
Bearbeitung der AIGC-Videoproduktionsprozess-Anordnungspraxis
Baidu-Ingenieure sprechen über Videoverständnis
Baidu-Ingenieure führen Sie zum Verständnis von Module Federation