GPT-Modell
GPT-Modell: Generatives Vortraining
Die Gesamtstruktur:
Unbeaufsichtigtes Vortraining
Betreutes Feintuning für nachgelagerte Aufgaben
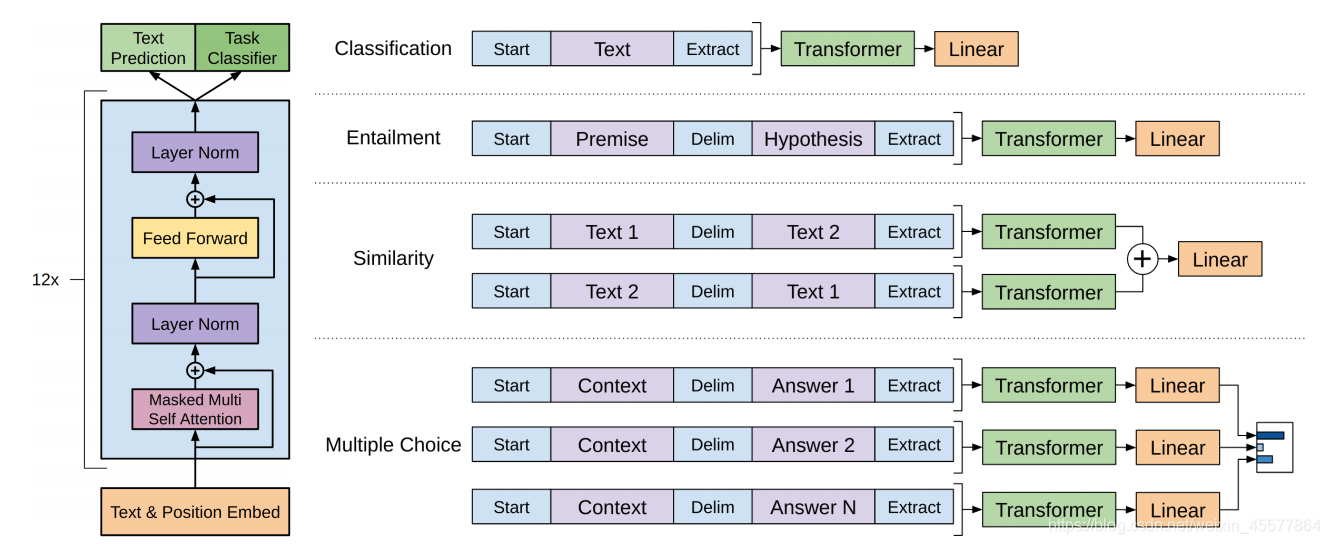
Kernstruktur: Der mittlere Teil besteht hauptsächlich aus 12 gestapelten Transformer-Decoder-Blöcken
Das folgende Bild spiegelt die Gesamtstruktur des Modells intuitiver wider:
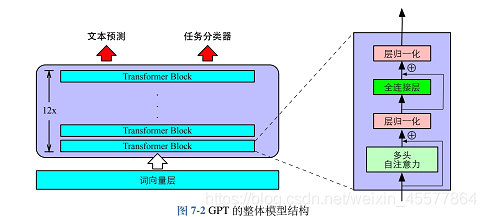
Modellbeschreibung
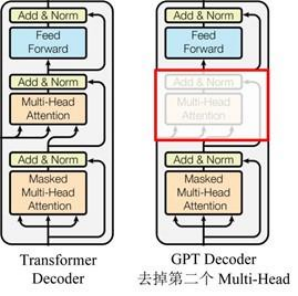
GPT verwendet die Decoder-Struktur von Transformer und nimmt einige Änderungen am Transformer Decoder vor. Der ursprüngliche Decoder enthält zwei Multi-Head-Aufmerksamkeitsstrukturen, und GPT behält nur Mask Multi-Head Attention bei, wie in der Abbildung unten gezeigt .
(Viele Daten besagen, dass es der Decoderstruktur ähnlich ist, weil der Maskenmechanismus des Decoders verwendet wird, aber abgesehen davon fühlt es sich dem Encoder tatsächlich ähnlicher an, also wird es manchmal implementiert, indem stattdessen der Encoder angepasst wird. Kümmern Sie sich nicht )
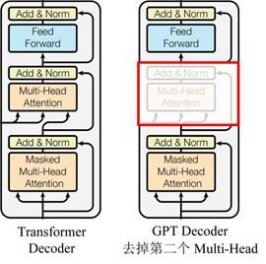
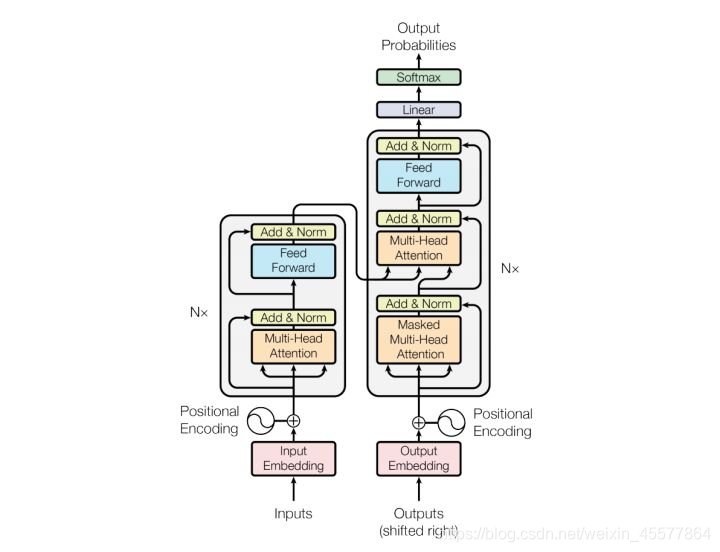
Verglichen mit der Struktur des ursprünglichen Transformators
Bühnenbeschreibung
Vortrainingsphase:



Die Vortrainingsphase ist die Textvorhersage, d. h. die Vorhersage des aktuellen Worts auf der Grundlage der vorhandenen historischen Wörter. Die drei Formeln 7-2, 7-3 und 7-4 entsprechen dem vorherigen GPT-Strukturdiagramm und der Ausgabe P (x) stellt die Ausgabe dar. Die Wahrscheinlichkeit jedes vorhergesagten Wortes, und dann verwenden Sie die 7-1-Formel, um die Maximum-Likelihood-Funktion zu berechnen, und konstruieren darauf basierend eine Verlustfunktion, das heißt, das Sprachmodell kann optimiert werden.
Phase zur Feinabstimmung nachgelagerter Aufgaben

verlustfunktion
Eine lineare Kombination aus Downstream-Tasks und Upstream-Task-Verlusten

Berechnungsprozess:
- eingeben
- Einbettung
- Mehrschichtiger Trafoblock
- Holen Sie sich zwei Ausgabeergebnisse
- Verlust berechnen
- Backpropagation
- Parameter aktualisieren
Ein spezifischer GPT-Beispielcode:
Sie können sehen, dass in der Vorwärtsfunktion des GPT-Modells zuerst die Embedding-Operation durchgeführt wird, dann die Operation im Block des 12-Layer-Transformators durchgeführt wird und dann der endgültige Berechnungswert durch erhalten wird zwei lineare Transformationen (eine für die Textvorhersage), eine für den Aufgabenklassifikator), ist der Code konsistent mit dem zu Beginn gezeigten Modellstrukturdiagramm.
Referenz: Kümmern Sie sich nicht
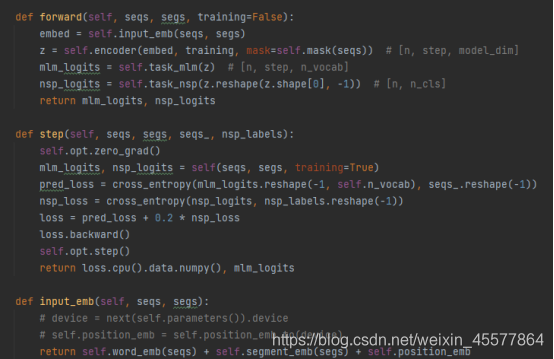
um den Python-GPT-Implementierungscode Konzentrieren wir uns auf die Berechnungsschritte 2 und 3
Berechnungsdetails:
[Einbettungsschicht]:
Die Einbettungsschicht für Tabellensuchoperationen
ist eine vollständig verbundene Schicht mit einem Hot als Eingabe und Zwischenschichtknoten als Wortvektordimensionen. Und der Parameter dieser vollständig verbundenen Schicht ist eine "Wortvektortabelle".

Die Matrixmultiplikation des One-Hot-Typs entspricht einer Tabellensuche, sodass die Tabellensuche direkt als Operation verwendet wird, anstatt sie zur Berechnung in eine Matrix zu schreiben, was den Berechnungsaufwand erheblich reduziert. Es wird nochmals betont, dass die Verringerung des Rechenaufwands nicht auf das Auftreten von Wortvektoren zurückzuführen ist, sondern darauf, dass die One-Hot-Matrix-Operation zu einer Tabellensuchoperation vereinfacht wird.
[Decoder-Schicht ähnlich wie Transformer in GPT]:
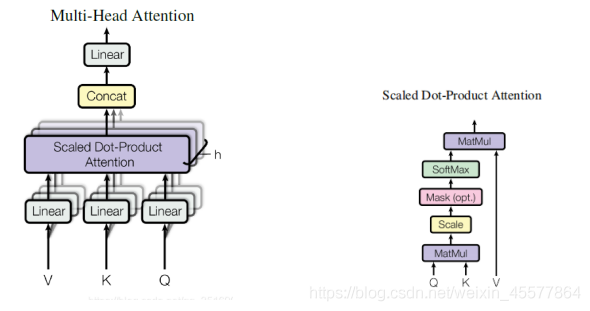
Jede Decoderschicht enthält zwei Unterschichten
- sublayer1: Mehrkopf-Aufmerksamkeitsebene für Maske
- sublayer2: ffn (Feed-Forward-Netzwerk) Feed-Forward-Netzwerk (mehrschichtiges Perzeptron)
sublayer1: Mehrkopf-Aufmerksamkeitsebene der Maske
输入:q, k, v, mask
计算注意力:Linear (Matrixmultiplikation)→Skalierte Punktproduktaufmerksamkeit→Concat (Mehrfachaufmerksamkeitsergebnisse, Umformen)→Linear(Matrixmultiplikation)
残差连接和归一化操作:Dropout-Operation → Restverbindung → Layer-Normalisierungsoperation
Berechnungsprozess:
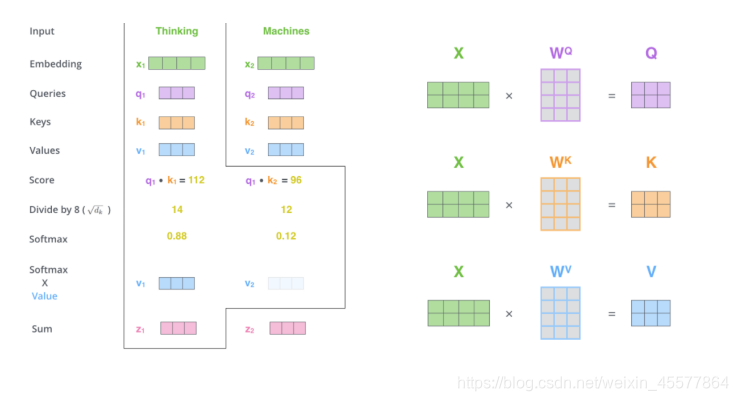
Der folgende Absatz beschreibt den Gesamtprozess der Aufmerksamkeitsberechnung:

Explosionshinweise:
Maske Mehrkopf-Aufmerksamkeit
1. Matrixmultiplikation:
Wandeln Sie die Eingabe q, k, v um
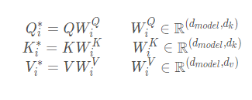
2.Skalierte Punktprodukt-Aufmerksamkeit
Die Hauptsache ist, die Aufmerksamkeitsberechnung und die Maskenoperation durchzuführen Maskenoperation
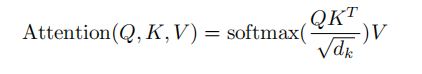
: masked_fill_(Maske, Wert)
Maskenoperation, füllt das Element im Tensor, das dem Wert 1 in der Maske entspricht, mit Wert. Die Form der Maske muss mit der Form des zu füllenden Tensors übereinstimmen. (Hier wird -inf padding verwendet, so dass der Softmax 0 wird, was gleichbedeutend damit ist, die folgenden Wörter nicht zu sehen)
Die Maskenoperation im Transformator
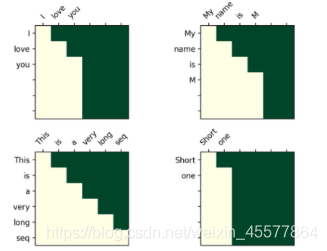
Visualisierungsmatrix nach Maske:
Das intuitive Verständnis ist, dass jedes Wort nur das Wort davor sehen kann (weil der Zweck darin besteht, das zukünftige Wort vorherzusagen, wenn Sie es sehen, müssen Sie es nicht vorhersagen)
3. Concat-Operation:
Das Kombinieren der Ergebnisse mehrerer Aufmerksamkeitsköpfe transformiert tatsächlich die Matrix: Permutierung, Umformungsoperationen und Dimensionsreduktion. (Wie in der roten Box in der Abbildung unten gezeigt)
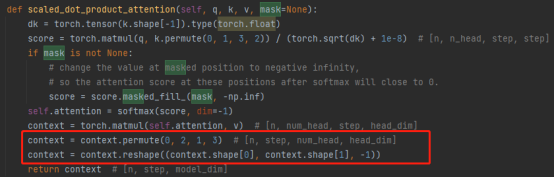
4. Matrixmultiplikation: eine lineare Schicht, die die Aufmerksamkeitsergebnisse linear transformiert
Die Mehrkopf-Aufmerksamkeitsebene der gesamten Maske 代码:
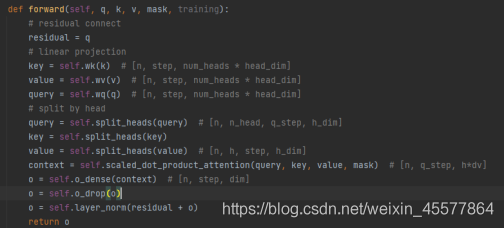
Hinweis: Die folgenden Zeilen im obigen Code sollen 残差连接和归一化操作
den Prozess der Aufmerksamkeitsergebnisse erläutern:
Restverbindungs- und Normalisierungsoperationen:
5.Dropout-Schicht
6. Matrixaddition
7. Ebenennormalisierung
Die Stapelnormalisierung ist die Normalisierung eines einzelnen Neurons zwischen verschiedenen Trainingsdaten, und die Schichtnormalisierung ist die Normalisierung eines einzelnen Trainingsdatens zwischen allen Neuronen einer bestimmten Schicht.
Input-Normalisierung, Batch-Normalisierung (BN) und Layer-Normalisierung (LN)
代码展示:
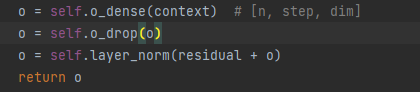
sublayer2: ffn (Feed-Forward-Netzwerk) Feedforward-Netzwerk
1. Lineare Schicht (Matrixmultiplikation)
2. Aktivierung der Relu-Funktion
3. Lineare Schicht (Matrixmultiplikation)
4. Dropout-Betrieb
5. Ebenennormalisierung
[Lineare Ebene]:
Die Ausgabeergebnisse des Mehrschichtblocks werden zur Transformation in zwei lineare Schichten gebracht, was relativ einfach ist und nicht im Detail beschrieben wird.
Ergänzung: Flussdiagramm der Aufmerksamkeitsschicht
Verweise
1. Nachschlagewerk: Radford ua „Improving Language Undersatnding by Generative Pre-Training“
2. Nachschlagewerk: „Natural Language Processing Based on Pre-training Model Method“ Che Wanxiang, Guo Jiang, Cui Yiming
3. Die Quelle des Code in diesem Artikel : Kümmern Sie sich nicht um den Python-GPT-Implementierungscode
4. Weitere Referenzlinks (Teile, die im Blog-Beitrag erwähnt werden):
Word-Embedding-Berechnungsprozessanalyse
Transformers Matrix-Dimensionsanalyse und detaillierte Maskenerklärung