
Basierend auf den häufigen Fragen von Apache Doris zum Lese- und Schreibprozess, zum Kopierkonsistenzmechanismus, zum Speichermechanismus, zum Hochverfügbarkeitsmechanismus usw. werden diese sortiert und in Form von Fragen und Antworten beantwortet. Bevor wir beginnen, erklären wir zunächst die Begriffe im Zusammenhang mit diesem Artikel:
-
FE : Frontend, der Front-End-Knoten von Doris. Hauptsächlich verantwortlich für den Empfang und die Rückgabe von Kundenanfragen, Metadaten, Clusterverwaltung, Erstellung von Abfrageplänen usw.
-
BE : Backend, der Backend-Knoten von Doris. Hauptverantwortlich für die Datenspeicherung und -verwaltung, die Ausführung von Abfrageplänen usw.
-
BDBJE : Oracle Berkeley DB Java Edition. In Doris wird BDBJE verwendet, um die Persistenz von Metadaten-Betriebsprotokollen, FE-Hochverfügbarkeit und anderen Funktionen zu vervollständigen.
-
Tablet : Tablet ist die tatsächliche physische Speichereinheit einer Tabelle. Eine Tabelle wird in Tablet-Einheiten in der verteilten Speicherschicht gespeichert, die von BE entsprechend Partitionen und Buckets gebildet wird. Jedes Tablet enthält Metainformationen und mehrere aufeinanderfolgende RowSets.
-
RowSet : RowSet ist eine Datensammlung einer Datenänderung in Tablet. Zu den Datenänderungen gehören Datenimport, Löschung, Aktualisierung usw. RowSet-Datensätze nach Versionsinformationen. Jede Änderung generiert eine Version.
-
Version : besteht aus zwei Attributen: Start und Ende und verwaltet Aufzeichnungsinformationen zu Datenänderungen. Wird normalerweise zur Darstellung des Versionsbereichs von RowSet verwendet. Nach einem neuen Import wird ein RowSet mit gleichem Start und Ende generiert. Nach der Komprimierung wird eine RowSet-Version im Bereich generiert.
-
Segment : Stellt Datensegmente im RowSet dar. Mehrere Segmente bilden ein RowSet.
-
Komprimierung : Der Prozess des Zusammenführens aufeinanderfolgender Versionen von RowSet wird als Komprimierung bezeichnet, und die Daten werden während des Zusammenführungsprozesses komprimiert.
-
Schlüsselspalte, Wertspalte : In Doris werden Daten logisch in Form einer Tabelle beschrieben. Eine Tabelle enthält Zeilen (Row) und Spalten (Column). Row ist eine Zeile mit Benutzerdaten, und Column wird verwendet, um verschiedene Felder in einer Datenzeile zu beschreiben. Die Spalte kann in zwei Kategorien unterteilt werden: Schlüssel und Wert. Aus geschäftlicher Sicht können Schlüssel und Wert Dimensionsspalten bzw. Indikatorspalten entsprechen. Die Schlüsselspalte von Doris ist die in der Tabellenerstellungsanweisung angegebene Spalte. Die Spalte, die in der Tabellenerstellungsanweisung auf das Schlüsselwort „Eindeutiger Schlüssel“ oder „Aggregatschlüssel“ oder „Duplikatschlüssel“ folgt, ist die Schlüsselspalte. Zusätzlich zur Schlüsselspalte ist der Rest der Wert Spalte.
-
Datenmodell : Das Datenmodell von Doris ist hauptsächlich in drei Kategorien unterteilt: Aggregat, Eindeutig und Dupliziert.
-
Basistabelle : In Doris nennen wir die vom Benutzer über die Tabellenerstellungsanweisung erstellte Tabelle die Basistabelle. In der Basistabelle werden die Basisdaten auf die in der Tabellenerstellungsanweisung des Benutzers angegebene Weise gespeichert.
-
ROLLUP-Tabelle : Zusätzlich zur Basistabelle können Benutzer eine beliebige Anzahl von ROLLUP-Tabellen erstellen. Diese ROLLUP-Daten werden auf Basis der Basistabelle generiert und physisch unabhängig gespeichert. Die Grundfunktion der ROLLUP-Tabelle besteht darin, grobkörnigere aggregierte Daten basierend auf der Basistabelle zu erhalten, ähnlich einer materialisierten Ansicht.
F1: Was ist der Unterschied zwischen Doris-Partitionierung und Bucketing?
Doris unterstützt zwei Ebenen der Datenpartitionierung:
-
Die erste Schicht ist Partition, die die Divisionsmethoden Bereich und Liste unterstützt (ähnlich dem Konzept der Partitionstabelle von MySQL). Mehrere Partitionen bilden eine Tabelle, und die Partition kann als kleinste logische Verwaltungseinheit betrachtet werden. Daten können nur für eine Partition importiert und gelöscht werden.
-
Die zweite Ebene ist Bucket (Tablet wird auch Bucketing genannt), die Hash- und Random-Division-Methoden unterstützt. Jedes Tablet enthält mehrere Datenzeilen, und die Daten zwischen den Tablets haben keine Überschneidungen und werden physisch unabhängig gespeichert. Ein Tablet ist die kleinste physische Speichereinheit für Vorgänge wie das Verschieben und Kopieren von Daten.
Sie können auch nur eine Partitionierungsebene verwenden. Wenn Sie beim Erstellen einer Tabelle keine Partitionierungsanweisung schreiben, generiert Doris eine Standardpartition, die für den Benutzer transparent ist.
Die Angabe lautet wie folgt:
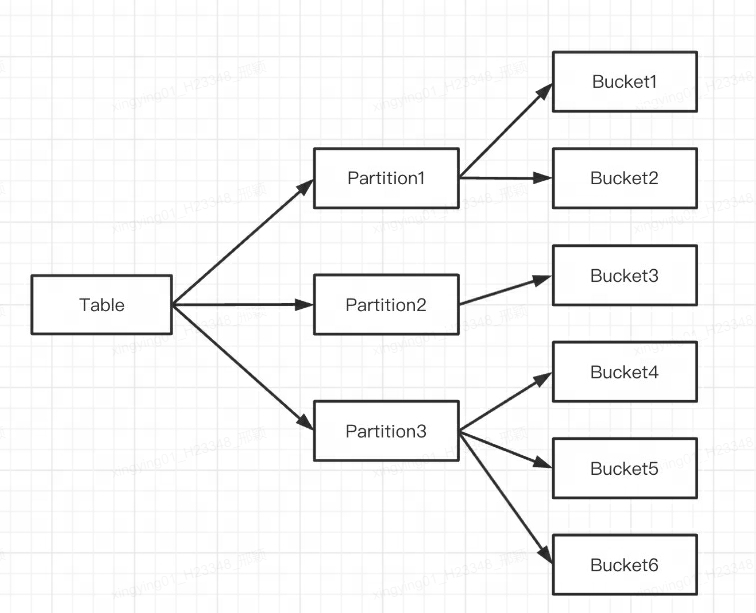
Mehrere Tablets gehören logischerweise zu verschiedenen Partitionen (Partition). Ein Tablet gehört nur zu einer Partition und eine Partition enthält mehrere Tablets. Da das Tablet physisch unabhängig gespeichert wird, kann davon ausgegangen werden, dass die Partition auch physisch unabhängig ist.
Logisch gesehen besteht der größte Unterschied zwischen Partitionierung und Bucketing darin, dass die Datenbank beim Bucketing zufällig aufgeteilt wird, während die Partitionierung die Datenbank nicht zufällig aufteilt.
Wie stellt man mehrere Kopien von Daten sicher?
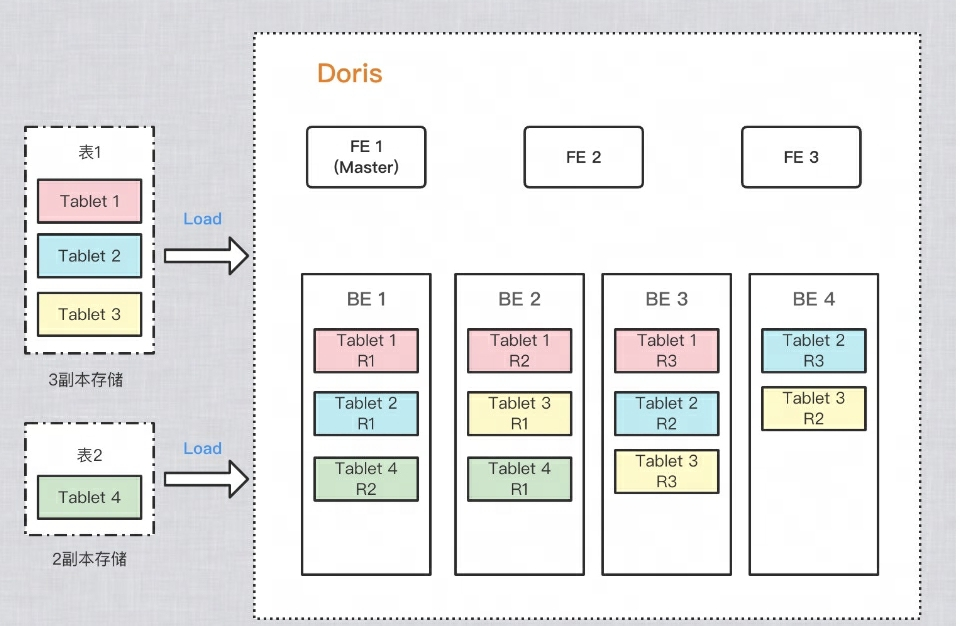
Um die Zuverlässigkeit der Datenspeicherung und die Berechnungsleistung zu verbessern, erstellt Doris mehrere Kopien jeder Tabelle zur Speicherung. Jede Datenkopie wird als Kopie bezeichnet. Doris verwendet Tablet als Basiseinheit zum Speichern von Datenkopien. Standardmäßig verfügt ein Shard über 3 Kopien. Beim Erstellen einer Tabelle können Sie PROPERTIESdie Anzahl der Kopien festlegen in:
PROPERTIES
(
"replication_num" = "3"
);
Als Beispiel in der Abbildung unten werden jeweils zwei Tabellen in Doris importiert. Tabelle 1 wird nach dem Import in drei Kopien gespeichert, und Tabelle 2 wird nach dem Import in zwei Kopien gespeichert. Die Datenverteilung ist wie folgt:
F2: Warum ist eine Eimerbildung erforderlich?
Um in Buckets zu schneiden und Datenverzerrungen zu vermeiden, Lese-IOs zu verteilen und die Abfrageleistung zu verbessern, können verschiedene Kopien des Tablets auf verschiedene Maschinen verteilt werden, sodass die E/A-Leistung verschiedener Maschinen bei Abfragen vollständig genutzt werden kann.
F3: Wie ist die Speicherstruktur und das Format physischer Dateien?
Jeder Import von Doris kann als Transaktion betrachtet werden und es wird ein RowSet generiert. Und RowSet enthält mehrere Segmente, das heißt Tablet-->Rowset-->Segment. Wie speichert BE diese Dateien?
Doris' Lagerstruktur
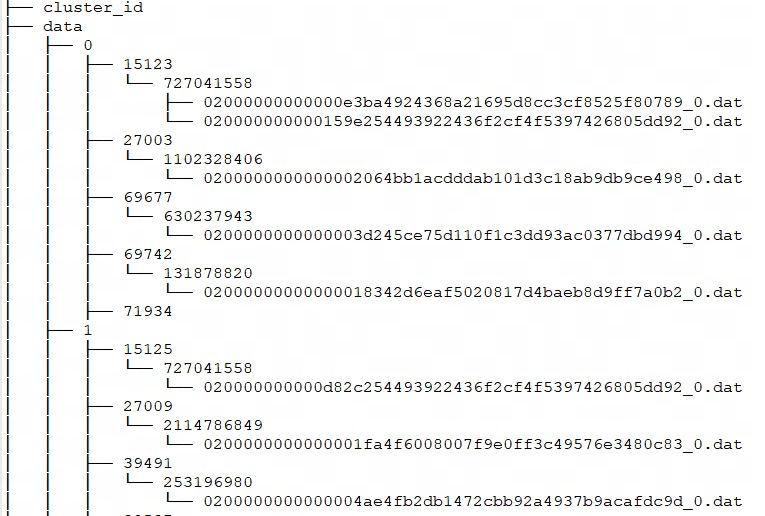
Doris storage_root_pathkonfiguriert den Speicherpfad über , und Segmentdateien werden im tablet_idVerzeichnis gespeichert und von SchemaHash verwaltet. Es können mehrere Segmentdateien vorhanden sein, die im Allgemeinen nach Größe unterteilt sind. Der Standardwert ist 256 MB. Die Regeln für die Benennung von Speicherverzeichnissen und Segmentdateien lauten:
${storage_root_path}/data/${shard}/${tablet_id}/${schema_hash}/${rowset_id}_${segment_id}.dat
Geben Sie storage_root_pathdas Verzeichnis ein und Sie sehen die folgende Speicherstruktur:
-
${shard}: Das ist 0, 1 in der obigen Abbildung. Es wird von BE automatisch im Speicherverzeichnis erstellt und ist zufällig. Sie wird mit der Zunahme der Daten zunehmen. -
${tablet_id}: Das heißt 15123, 27003 usw. in der obigen Abbildung. Dies ist die ID des oben erwähnten Buckets. -
${schema_hash}: Das heißt 727041558, 1102328406 usw. im Bild oben. Da sich die Struktur einer Tabelle ändern kann, wird für jede Schemaversion eine erstellt,SchemaHashum die Daten unter dieser Version zu identifizieren. -
${segment_id}.dat: Das erste istrowset_id, das heißt 02000000000000e3ba4924368a21695d8cc3cf8525f80789 in der obigen Abbildung;${segment_id}es ist das aktuelle RowSetsegment_id, beginnend bei 0 und aufsteigend.
Segmentdateispeicherformat
Das gesamte Dateiformat von Segment ist in drei Teile unterteilt: Datenbereich, Indexbereich und Fußzeile, wie in der folgenden Abbildung dargestellt:

-
Datenbereich: Wird zum Speichern der Dateninformationen jeder Spalte verwendet. Die Daten hier werden bei Bedarf in Seiten geladen. Die Seiten enthalten die Spaltendaten und jede Seite ist 64 KB groß.
-
Indexbereich: Doris speichert die Indexdaten jeder Spalte im Indexbereich. Die Daten werden hier entsprechend der Spaltengranularität geladen, sodass sie getrennt von den Spaltendateninformationen gespeichert werden.
-
Fußzeileninformationen: Enthält Metadateninformationen der Datei, Prüfsumme des Inhalts usw.
F4: Welche DML-Einschränkungen gibt es bei den verschiedenen Tischmodellen von Doris?
-
Update: Die Update-Anweisung unterstützt derzeit nur das UNIQUE KEY-Modell und nur die Aktualisierung der Wertspalte.
-
Löschen: 1) Wenn das Tabellenmodell eine Aggregatklasse (AGGREGATE, UNIQUE) verwendet, kann die Löschoperation nur die Bedingungen für die Schlüsselspalte angeben; 2) Diese Operation löscht auch die Daten des Rollup-Index, die sich auf diesen Basisindex beziehen.
-
Einfügen: Alle Datenmodelle können eingefügt werden.
Wie implementiert man Einfügen? Wie können die Daten nach dem Einfügen abgefragt werden?
-
AGGREGATE-Modell : In der Einfügephase werden die inkrementellen Daten in der Append-Methode in das RowSet geschrieben, und in der Abfragephase wird die Methode „Merge on Read“ zum Zusammenführen verwendet. Das heißt, die Daten werden beim Importieren zuerst in ein neues RowSet geschrieben und nach dem Schreiben wird keine Deduplizierung durchgeführt. Die gleichzeitige Sortierung in mehrere Richtungen wird nur durchgeführt, wenn eine Abfrage initiiert wird. Bei der Zusammenführungssortierung in mehrere Richtungen duplizieren Die Daten werden sortiert. Die Schlüssel werden zusammengestellt und aggregiert. Der Schlüssel mit der höheren Version überschreibt den Schlüssel mit der niedrigeren Version und letztendlich wird nur der Datensatz mit der höchsten Version an den Benutzer zurückgegeben.
-
DUPLICATE-Modell : Dieses Modell ist ähnlich wie das oben beschriebene geschrieben und in der Lesephase werden keine Aggregationsvorgänge durchgeführt.
-
UNIQUE-Modell : Vor Version 1.2 war dieses Modell im Wesentlichen ein Sonderfall des Aggregatmodells, dessen Verhalten mit dem AGGREGATE-Modell übereinstimmte. Da das Aggregationsmodell durch Merge on Read implementiert wird , ist die Leistung bei einigen Aggregationsabfragen schlecht. Doris führte nach Version 1.2 eine neue Implementierung des Unique-Modells ein, Merge on Write , die beim Schreiben überschriebene und aktualisierte Daten markiert und löscht. Während der Abfrage werden alle markierten und gelöschten Daten gelöscht. Die Daten werden auf Dateiebene herausgefiltert. und die gelesenen Daten sind die neuesten Daten, wodurch der Datenaggregationsprozess beim Zusammenführen zur Lesezeit entfällt und in vielen Fällen das Pushdown mehrerer Prädikate unterstützt werden kann.
Einfach ausgedrückt ist der Verarbeitungsablauf von Merge on Write:
-
Suchen Sie für jeden Schlüssel seine Position in den Basisdaten (RowSetid + Segmentid + Zeilennummer). [Der Primärschlüsselintervallbaum auf Segmentebene wird im Speicher verwaltet, um Abfragen zu beschleunigen.]
-
Wenn der Schlüssel vorhanden ist, markieren Sie die Datenzeile zum Löschen. Die zum Löschen markierten Informationen werden in der Lösch-Bitmap aufgezeichnet, wobei jedes Segment über eine entsprechende Lösch-Bitmap verfügt.
-
Schreiben Sie die aktualisierten Daten in das neue RowSet, schließen Sie die Transaktion ab und machen Sie die neuen Daten sichtbar, dh sie können vom Benutzer abgefragt werden.
-
Lesen Sie bei der Abfrage die Lösch-Bitmap, filtern Sie die zum Löschen markierten Zeilen heraus und geben Sie nur gültige Daten zurück. [Für alle Treffersegmente Abfrage nach Version von hoch nach niedrig]
Im Folgenden wird die Implementierung des Schreibprozesses und des Leseprozesses vorgestellt.
Schreibvorgang : Beim Schreiben von Daten wird zuerst der Primärschlüsselindex jedes Segments erstellt und dann die Löschbitmap aktualisiert.
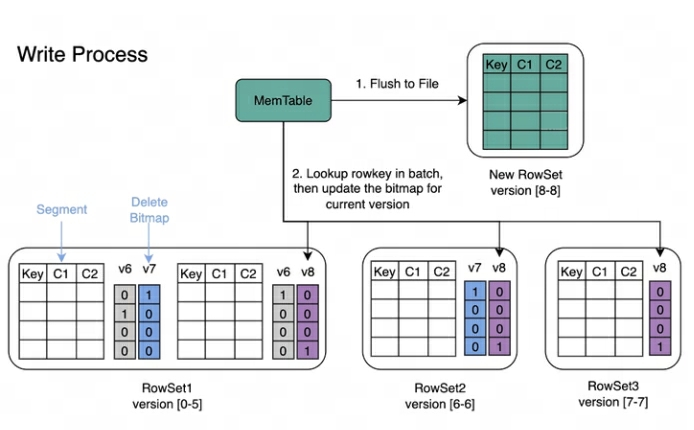
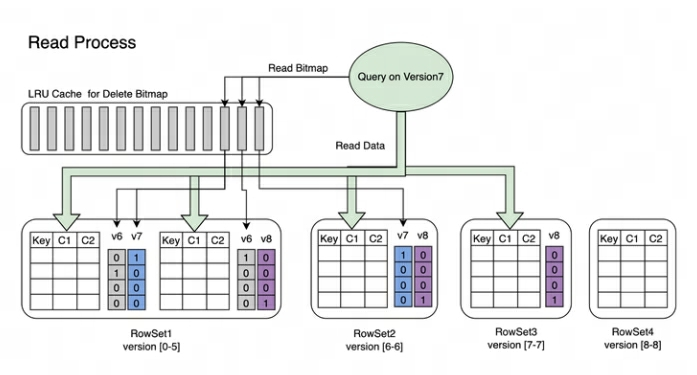
Lesevorgang : Der Lesevorgang von Bitmap ist in der folgenden Abbildung dargestellt. Aus dem Bild können wir Folgendes erkennen:
-
Bei einer Abfrage, die Version 7 anfordert, werden nur Daten angezeigt, die Version 7 entsprechen.
-
Beim Lesen der Daten von RowSet5 werden die durch V6- und V7-Änderungen generierten Bitmaps zusammengeführt, um die vollständige DeleteBitmap entsprechend Version7 zu erhalten, die zum Filtern der Daten verwendet wird.
-
Im obigen Beispiel deckt der Import von Version 8 ein Datenelement in Segment2 von RowSet1 ab, aber die Abfrage, die Version 7 anfordert, kann die Daten weiterhin lesen.
Wie wird das Update implementiert?
Der UNIQUE-Modellaktualisierungsprozess besteht im Wesentlichen aus Auswählen+Einfügen.
-
Update verwendet die Where-Filterlogik der Abfrage-Engine, um die zu aktualisierenden Zeilen aus der zu aktualisierenden Tabelle herauszufiltern und auf dieser Grundlage die Lösch-Bitmap beizubehalten und neu eingefügte Daten zu generieren.
-
Führen Sie dann die Einfügelogik aus. Der spezifische Prozess ähnelt der oben erwähnten Logik zum Schreiben von UNIQUE-Modellen.
F5: Wie wird Doris‘ Löschung implementiert? Wird auch ein RowSet generiert? Wie lösche ich die entsprechenden Daten?
-
Doris' Löschen generiert auch ein RowSet. Im DELETE-Modus werden die Daten nicht tatsächlich gelöscht, sondern die Datenlöschbedingungen werden aufgezeichnet. In Metainformationen gespeichert. Beim Ausführen der Basiskomprimierung werden die Löschbedingungen in die Basisversion übernommen.
-
Doris unterstützt auch LOAD_DELETE unter dem UNIQUE KEY-Modell, das das Löschen von Daten durch Stapelimport der zu löschenden Schlüssel ermöglicht und umfangreiche Datenlöschfunktionen unterstützen kann. Die Gesamtidee besteht darin, dem Datensatz eine Löschstatuskennung hinzuzufügen und den gelöschten Schlüssel während des Komprimierungsprozesses zu komprimieren. Die Komprimierung ist hauptsächlich für das Zusammenführen mehrerer RowSet-Versionen verantwortlich.
F6: Welche Indizes hat Doris?
Derzeit unterstützt Doris hauptsächlich zwei Arten von Indizes:
-
Integrierte intelligente Indizes, einschließlich Präfixindizes und ZoneMap-Indizes.
-
Zu den von Benutzern manuell erstellten Sekundärindizes gehören invertierte Indizes, Bloomfilter-Indizes, Ngram-Bloomfilter-Indizes und Bitmap-Indizes.
Der ZoneMap-Index ist eine Indexinformation, die automatisch für jede Spalte im Spaltenspeicherformat verwaltet wird, einschließlich Min/Max, der Anzahl der Nullwerte usw. Diese Indizierung ist für den Benutzer transparent.
Welches Niveau hat der Index?
-
Jetzt sind alle Indizes in Doris lokal auf BE-Ebene, z. B. invertierter Index, Bloomfilter-Index, Ngram-Bloomfilter-Index und Bitmap-Index, Präfixindex und ZoneMap-Index usw.
-
Doris hat keinen globalen Index. Im weitesten Sinne können Partitionen und Bucket-Schlüssel auch als global betrachtet werden, sie sind jedoch relativ grobkörnig.
Was ist das Speicherformat des Index?
In Doris werden die Indexdaten jeder Spalte einheitlich im Indexbereich der Segmentdatei gespeichert. Die Daten werden hier entsprechend der Spaltengranularität geladen, sodass sie getrennt von den Spaltendateninformationen gespeichert werden. Hier nehmen wir als Beispiel den Short Key Index-Präfixindex.
Der Präfixindex Short Key Index ist eine Indexmethode, die auf der Schlüsselsortierung (AGGREGATE KEY, UNIQ KEY und DUPLICATE KEY) basiert, um schnell Daten basierend auf einer bestimmten Präfixspalte abzufragen. Der Short Key Index-Index verwendet hier ebenfalls eine spärliche Indexstruktur. Während des Datenschreibvorgangs wird nach jeder bestimmten Anzahl von Zeilen ein Indexelement generiert. Diese Anzahl von Zeilen ist die Indexgranularität, die standardmäßig 1024 Zeilen beträgt und konfigurierbar ist. Der Prozess ist unten dargestellt:
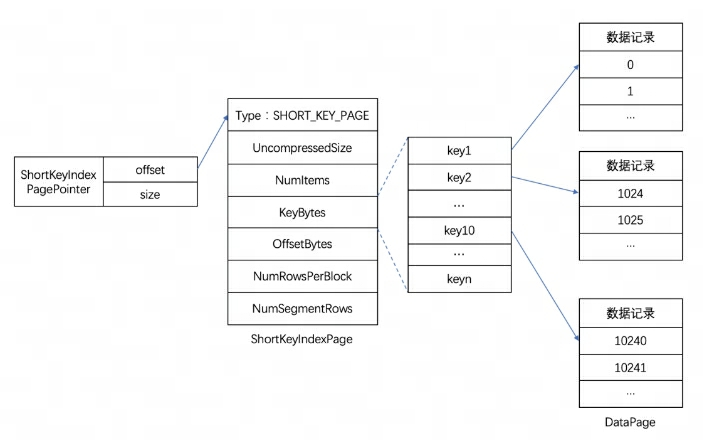
Unter anderem speichert KeyBytes die Indexelementdaten und OffsetBytes speichert den Offset des Indexelements in KeyBytes.
Short Key Index verwendet die ersten 36 Bytes als Präfixindex dieser Datenzeile. Wenn ein VARCHAR-Typ gefunden wird, wird der Präfixindex direkt abgeschnitten. Short Key Index verwendet die ersten 36 Bytes als Präfixindex dieser Datenzeile. Wenn ein VARCHAR-Typ gefunden wird, wird der Präfixindex direkt abgeschnitten.
Wie wirkt sich der Lesevorgang auf den Index aus?
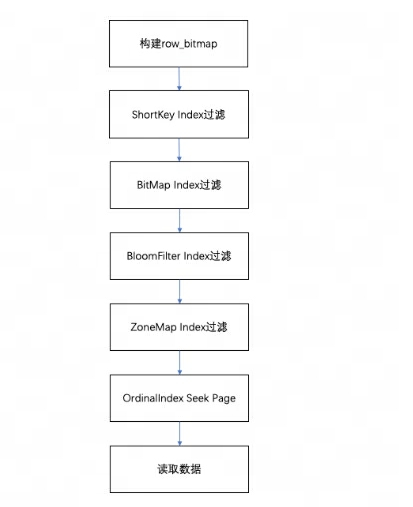
Beim Abfragen der Daten in einem Segment werden die Daten gemäß den ausgeführten Abfragebedingungen zunächst basierend auf dem Feldindex gefiltert. Lesen Sie dann die Daten. Der gesamte Abfrageprozess ist wie folgt:
-
Zunächst wird eine entsprechend der Anzahl der Zeilen im Segment erstellt,
row_bitmapum anzugeben, welche Daten gelesen werden müssen. Alle Daten müssen ohne Verwendung eines Index gelesen werden. -
Wenn der Schlüssel in den Abfragebedingungen gemäß der Präfixindexregel verwendet wird, wird zuerst der ShortKey-Index gefiltert und der Ordinalzeilennummernbereich, der im ShortKey-Index abgeglichen werden kann, wird zu kombiniert
row_bitmap. -
Wenn im Spaltenfeld der Abfragebedingung ein BitMap-Indexindex vorhanden ist, wird die ordinale Zeilennummer, die die Bedingungen erfüllt, direkt anhand des BitMap-Index ermittelt und zum Filtern mit row_bitmap geschnitten. Die Filterung hier ist präzise. Wenn die Abfragebedingung später entfernt wird, wird dieses Feld nicht für nachfolgende Indizes gefiltert.
-
Wenn das Spaltenfeld in der Abfragebedingung einen BloomFilter-Index hat und die Bedingung äquivalent ist (eq, in, is), wird es gemäß dem BloomFilter-Index gefiltert. Hier werden alle Indizes durchlaufen, der BloomFilter jeder Seite wird es tun gefiltert werden und die Abfragebedingungen können gefunden werden. Alle Seiten.
row_bitmapFiltern Sie den Schnittpunkt des Ordinalzeilennummernbereichs in den Indexinformationen und . -
Wenn im Spaltenfeld der Abfragebedingung ein ZoneMap-Index vorhanden ist, wird dieser nach dem ZoneMap-Index gefiltert. Hier werden auch alle Indizes durchlaufen, um alle Seiten zu finden, auf denen sich die Abfragebedingung mit der ZoneMap überschneiden kann.
row_bitmapFiltern Sie den Schnittpunkt des Ordinalzeilennummernbereichs in den Indexinformationen und . -
Suchen Sie nach dem Generieren
row_bitmapstapelweise über den OrdinalIndex jeder Spalte nach der spezifischen Datenseite. -
Lesen Sie die Daten der Spaltendatenseite jeder Spalte stapelweise. Bestimmen Sie beim Lesen für Seiten mit Nullwerten anhand der Nullwert-Bitmap, ob die aktuelle Zeile Null ist. Wenn sie Null ist, füllen Sie sie direkt aus.
F7: Wie führt Doris die Komprimierung durch?
Doris verwendet Komprimierung, um RowSet-Dateien inkrementell zu aggregieren und so die Leistung zu verbessern. Die Versionsinformationen von RowSet bestehen aus zwei Feldern, Start und Ende, um den Versionsbereich des zusammengeführten Rowsets darzustellen. Die Versionen Start und End eines nicht zusammengeführten kumulativen RowSets sind gleich. Während der Komprimierung werden benachbarte RowSets zusammengeführt, um ein neues RowSet zu generieren, und die Anfangs- und Endinformationen der Version werden ebenfalls zusammengeführt, um eine größere Version zu bilden. Andererseits reduziert der Komprimierungsprozess die Anzahl der RowSet-Dateien erheblich und verbessert die Abfrageeffizienz.
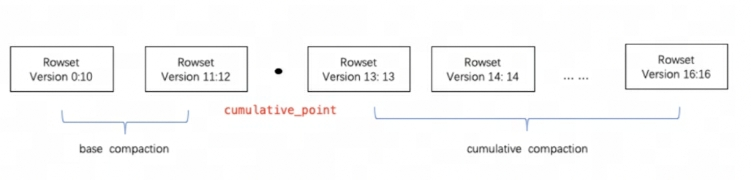
Wie in der Abbildung oben dargestellt, werden Komprimierungsaufgaben in zwei Typen unterteilt: Basiskomprimierung und kumulative Komprimierung. cumulative_pointEs ist der Schlüssel zur Trennung der beiden Strategien.
Es kann so verstanden werden:
-
cumulative_pointAuf der rechten Seite befindet sich ein inkrementelles RowSet, das noch nie zusammengeführt wurde, und die Start- und Endversionen jedes RowSets sind gleich; -
cumulative_pointAuf der linken Seite befindet sich das zusammengeführte RowSet. Die Startversion und die Endversion sind unterschiedlich. -
Die Aufgabenprozesse der Basiskomprimierung und der kumulativen Komprimierung sind grundsätzlich gleich. Der einzige Unterschied liegt in der Logik der Auswahl des zusammenzuführenden InputRowSet.
Auf welchem Schlüssel basiert die Komprimierung?
-
In einem Segment werden Daten immer in der Sortierreihenfolge des Schlüssels gespeichert (AGGREGATE KEY, UNIQ KEY und DUPLICATE KEY). Das heißt, die Sortierung des Schlüssels bestimmt die physische Struktur der Datenspeicherung und die physische Strukturreihenfolge der Spaltendaten.
-
Der Doris-Verdichtungsprozess basiert also auf AGGREGATE KEY, UNIQ KEY und DUPLICATE KEY.
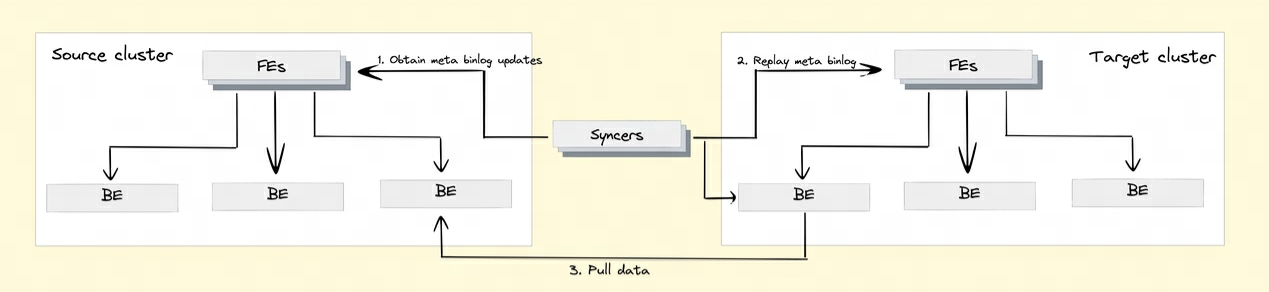
F8: Wie implementiert Doris die Cluster-übergreifende Datenreplikation?
Um die Cluster-übergreifende Datenreplikationsfunktion zu realisieren, führte Doris den Binlog-Mechanismus ein. Datenänderungsdatensätze und -vorgänge werden automatisch über den Binlog-Mechanismus aufgezeichnet, um eine Rückverfolgbarkeit der Daten zu erreichen. Datenwiedergabe und -wiederherstellung können auch basierend auf dem Binlog-Wiedergabemechanismus erreicht werden.
Wie wird Binlog aufgezeichnet?
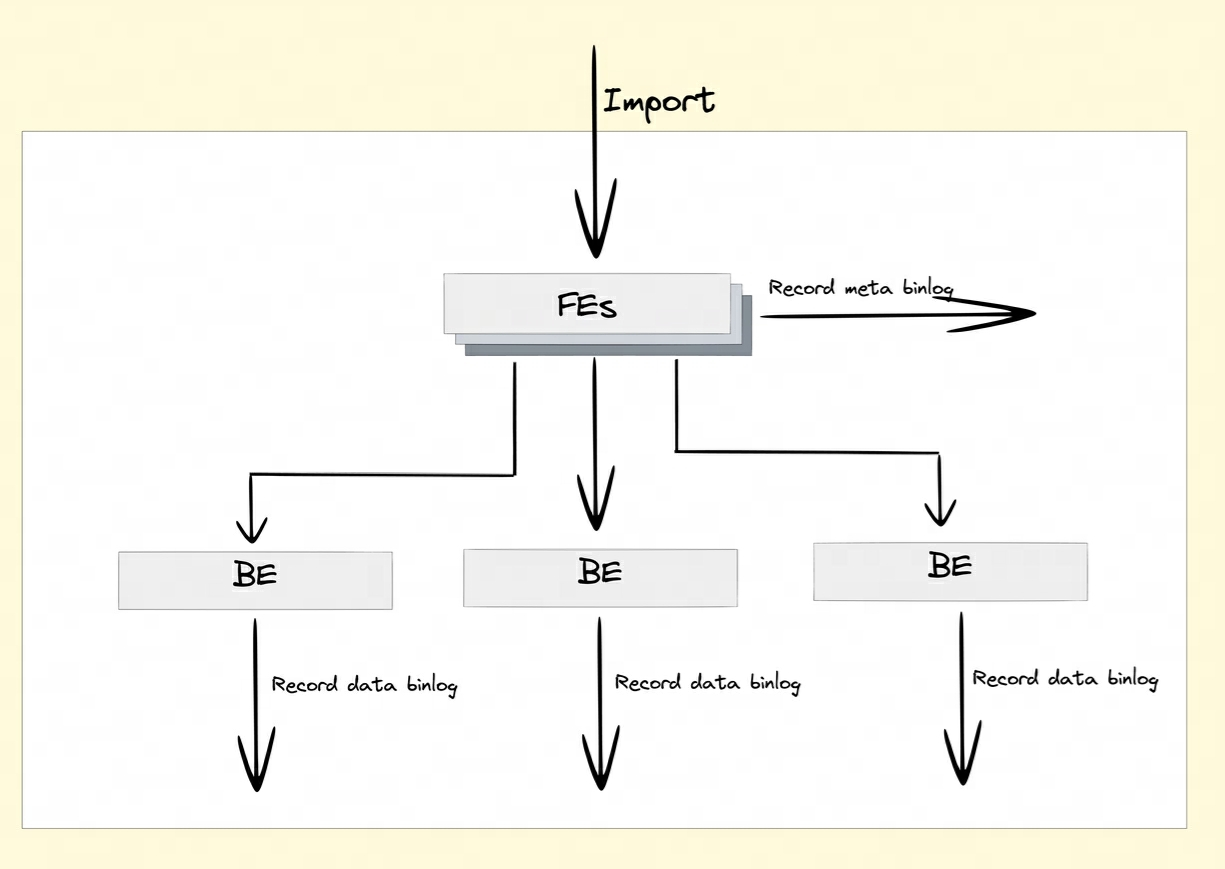
Nach dem Aktivieren des Binlog-Attributs behalten FE und BE die Änderungsdatensätze von DDL/DML-Vorgängen im Meta-Binlog und im Daten-Binlog bei.
-
Meta Binlog: Doris hat die Implementierung von EditLog verbessert, um die Ordnung des Protokolls sicherzustellen. Durch die Erstellung einer zunehmenden Folge von LogIDs wird jeder Vorgang genau aufgezeichnet und der Reihe nach gespeichert. Dieser geordnete Persistenzmechanismus trägt dazu bei, die Datenkonsistenz sicherzustellen.
-
Daten-Binlog: Wenn FE eine Veröffentlichungstransaktion initiiert, führt BE den entsprechenden Veröffentlichungsvorgang aus. BE schreibt die Metadateninformationen dieser Transaktion, an der RowSet beteiligt ist
rowset_meta, mit und speichert sie im Metaspeicher. Nach der Übermittlung werden die importierten Segmentdateien gespeichert mit dem Binlog-Ordner verknüpft.
Binlog-Generierung:
Wiedergabe von BInlog-Daten:
F9: Doris‘ Tisch hat mehrere Kopien. Wie kann man während der Schreibphase mehrere Kopien sicherstellen? Gibt es ein Master-Slave-Konzept? Ist es notwendig, den Schreiberfolg nach Majority zurückzugeben?
-
Die 3 Kopien von Doris BE verfügen nicht über das Master-Slave-Konzept und verwenden den Quorum-Algorithmus, um das Schreiben mehrerer Kopien sicherzustellen.
-
Während des Schreibvorgangs stellt FE fest, ob die Anzahl der Kopien jedes Tablets, das erfolgreich Daten schreibt, die Hälfte der Gesamtzahl der Tablet-Kopien übersteigt. Wenn die Anzahl der Kopien jedes Tablets, das erfolgreich Daten schreibt, die Hälfte der Gesamtzahl der Tablets überschreitet Kopien (größter Erfolg), dann ist die Commit-Transaktion erfolgreich und der Transaktionsstatus wird auf COMMITTED gesetzt; der COMMITTED-Status zeigt an, dass die Daten erfolgreich geschrieben wurden, die Daten jedoch noch nicht sichtbar sind und die Aufgabe „Version veröffentlichen“ fortgesetzt werden muss . Danach kann die Transaktion nicht mehr zurückgesetzt werden.
-
FE verfügt über einen separaten Thread zum Ausführen der Veröffentlichungsversion für die erfolgreiche Commit-Transaktion. Wenn FE die Veröffentlichungsversion ausführt, sendet es Veröffentlichungsversionsanforderungen an alle Executor BE-Knoten, die sich auf die Transaktion beziehen, über Thrift RPC. Die Aufgabe „Version veröffentlichen“ wird auf jedem asynchron ausgeführt Executor BE-Knoten. Importieren Sie die Daten in das generierte RowSet und machen Sie daraus eine sichtbare Datenversion.
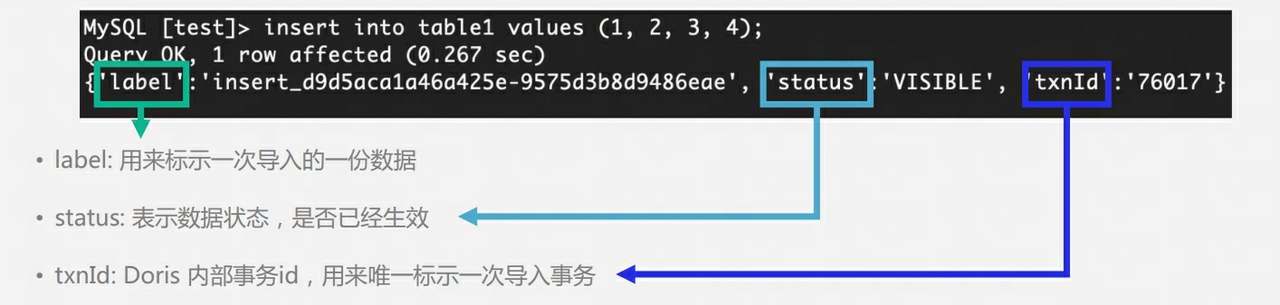
Warum gibt es einen Veröffentlichungsmechanismus : Ähnlich wie bei MVCC können Benutzer Daten lesen, die noch nicht übermittelt wurden, wenn es keinen Veröffentlichungsmechanismus gibt.
Was passiert, wenn die Tabelle 3 Kopien hat und nur 1 Kopie erfolgreich geschrieben wurde : Zu diesem Zeitpunkt wird die Transaktion abgebrochen
Was passiert, wenn die Tabelle 3 Kopien enthält und nur 2 Kopien erfolgreich geschrieben wurden : Zu diesem Zeitpunkt wird die Transaktion festgeschrieben und Doris FE führt regelmäßig Tablet-Überwachungen und -Inspektionen durch. Wenn eine Anomalie in der Tablet-Kopie festgestellt wird, wird ein Klon erstellt Es wird die Aufgabe generiert, eine neue Kopie zu klonen.
Warum führt der Benutzer die Abfrage unmittelbar nach dem Ausführen von Einfügen in aus und das Ergebnis ist möglicherweise leer ?Der Grund dafür ist, dass die Transaktion noch nicht veröffentlicht wurde.
F10: Wie stellt Doris' FE eine hohe Verfügbarkeit sicher?
Auf der Metadatenebene verwendet Doris das Paxos-Protokoll und den Memory + Checkpoint + Journal-Mechanismus, um eine hohe Leistung und hohe Zuverlässigkeit der Metadaten sicherzustellen.
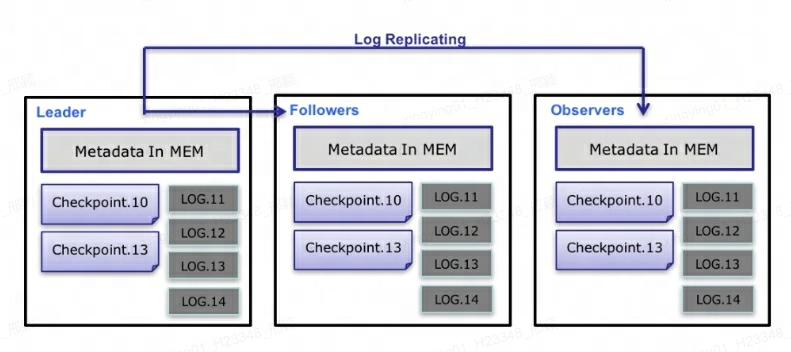
Der spezifische Prozess des Metadaten-Datenflusses ist wie folgt :
-
Nur Leader FE kann Metadaten schreiben. Nachdem der Schreibvorgang den Speicher des Leaders geändert hat, wird er in ein Protokoll serialisiert und
key-valuein Form von in BDBJE geschrieben. Der Schlüssel ist eine fortlaufende Ganzzahl undlog idder Wert ist das serialisierte Betriebsprotokoll. -
Nachdem das Protokoll in BDBJE geschrieben wurde, kopiert BDBJE das Protokoll gemäß der Richtlinie (Schreibmehrheit/alle Schreibvorgänge) auf andere Nicht-Leader-FE-Knoten. Der Nicht-Leader-FE-Knoten ändert sein eigenes Metadatenspeicherbild, indem er Protokolle wiedergibt, um die Metadatensynchronisierung mit dem Leader-Knoten abzuschließen.
-
Die Anzahl der Protokolle auf dem Leader-Knoten erreicht den Schwellenwert (standardmäßig 100.000) und erfüllt den Checkpoint-Thread-Ausführungszyklus (standardmäßig 60 Sekunden). Checkpoint liest die vorhandene Image-Datei und die nachfolgenden Protokolle und gibt eine neue Metadaten-Image-Kopie im Speicher wieder. Die Kopie wird dann auf die Festplatte geschrieben, um ein neues Image zu erstellen. Der Grund dafür, eine Kopie des Bildes neu zu generieren, anstatt das vorhandene Bild als Bild zu schreiben, liegt hauptsächlich darin, dass das Schreiben in das Bild und das Hinzufügen einer Lesesperre den Schreibvorgang blockiert. Daher belegt jeder Checkpoint den doppelten Speicherplatz.
-
Nachdem die Bilddatei generiert wurde, benachrichtigt der Leader-Knoten andere Nicht-Leader-Knoten darüber, dass das neue Bild generiert wurde. Non-Leader ruft aktiv die neueste Bilddatei über HTTP ab, um die alte lokale Datei zu ersetzen.
-
Bei Protokollen in BDBJE werden alte Protokolle regelmäßig gelöscht, nachdem das Image abgeschlossen ist.
erklären :
-
Jede Metadatenaktualisierung wird zunächst in die Protokolldatei auf der Festplatte geschrieben, dann in den Speicher geschrieben und schließlich regelmäßig per Checkpoint auf die lokale Festplatte übertragen.
-
Dies entspricht einer reinen Speicherstruktur, was bedeutet, dass alle Metadaten im Speicher zwischengespeichert werden, wodurch sichergestellt wird, dass FE Metadaten nach einem Absturz schnell wiederherstellen kann, ohne Metadaten zu verlieren.
-
Die drei Leader, Follower und Observer stellen einen zuverlässigen Dienst dar. Wenn ein einzelner Knoten ausfällt, reichen im Grunde drei aus, da der FE-Knoten schließlich nur eine Kopie der Metadaten speichert und sein Druck nicht groß ist Bei zu vielen FEs werden Maschinenressourcen verbraucht, sodass in den meisten Fällen drei ausreichen, um einen hochverfügbaren Metadatendienst zu erreichen.
-
Benutzer können MySQL verwenden, um eine Verbindung zu jedem FE-Knoten herzustellen, um Lese- und Schreibzugriff auf Metadaten zu erhalten. Wenn die Verbindung zu einem Nicht-Leader-Knoten besteht, leitet der Knoten den Schreibvorgang an den Leader-Knoten weiter.
Über den Autor
Invisible (Xing Ying) ist leitende Datenbank-Kernel-Ingenieurin bei NetEase. Sie beschäftigt sich seit ihrem Abschluss mit der Datenbank-Kernel-Entwicklung. Derzeit ist sie hauptsächlich mit der Entwicklung, Wartung und Geschäftsunterstützung von MySQL und Apache Doris beschäftigt. Als Mitwirkender am MySQL-Kernel meldete er mehr als 50 Fehler und Optimierungselemente für MySQL, und mehrere Beiträge wurden in die MySQL-Version 8.0 integriert. Seit 2023 ist Apache Doris Active Contributor Mitglied der Apache Doris-Community und hat Dutzende Commits für die Community eingereicht und zusammengeführt.
Eine Mittelschule hat ein „intelligentes interaktives Katharsis-Gerät“ gekauft – was eigentlich ein Fall für Nintendo Wii ist. TIOBE 2023 Programmiersprache des Jahres: C# Kingsoft WPS abgestürzt Linuxs Rust-Experiment war erfolgreich, kann Firefox die Gelegenheit nutzen ... 10 Vorhersagen darüber Open-Source -Follow-up zum Vorfall, bei dem weibliche Führungskräfte Mitarbeiter entlassen haben: Der Vorsitzende des Unternehmens bezeichnete Mitarbeiter als „Wiederholungstäter“ und stellte „falsche akademische Lebensläufe“ in Frage. Das Open-Source-Artefakt LSPosed kündigte an, die Aktualisierung einzustellen. Der Autor sagte, es habe einen großen Schaden erlitten Anzahl böswilliger Angriffe. 2024 „Die Schlacht des Jahres“ im Front-End-Kreis: React kann keine Löcher graben. Müssen Sie diese mit Dokumenten ausfüllen? Linux Kernel 6.7 ist offiziell veröffentlicht. Die „Post-Open-Source“-Ära ist da: Die Lizenz ist ungültig und kann nicht der Allgemeinheit dienen. Weibliche Führungskräfte wurden rechtswidrig entlassen. Mitarbeiter äußerten sich zu Wort und wurden ins Visier genommen, weil sie sich gegen den Einsatz von Raubkopien von EDA-Tools ausgesprochen hatten Design-Chips.