Am 17. Januar fanden in Shanghai die Pressekonferenz von Scholar Puyuan 2.0 (InternLM2) und die Eröffnungszeremonie der Scholar Puyuan Large Model Challenge statt. Das Shanghai Artificial Intelligence Laboratory und SenseTime haben zusammen mit der Chinese University of Hong Kong und der Fudan University offiziell die neue Generation des großen Sprachmodells Puyu 2.0 (InternLM2) veröffentlicht .

Open-Source-Adresse
- Github: https://github.com/InternLM/InternLM
- HuggingFace: https://huggingface.co/internlm
- ModelScope: https://modelscope.cn/organization/Shanghai_AI_Laboratory
Berichten zufolge wurde InternLM2 auf einem hochwertigen Korpus von 2,6 Billionen Token trainiert. In Anlehnung an die Einstellungen des Gelehrten der ersten Generation Puyu (InternLM) enthält InternLM2 zwei Parameterspezifikationen von 7B und 20B sowie Basis- und Dialogversionen, um den Anforderungen verschiedener komplexer Anwendungsszenarien gerecht zu werden. Getreu dem Konzept „Innovation durch hochwertige Open-Source-Lösungen stärken“ stellt das Shanghai AI Laboratory weiterhin kostenlose kommerzielle Lizenzen für InternLM2 bereit.
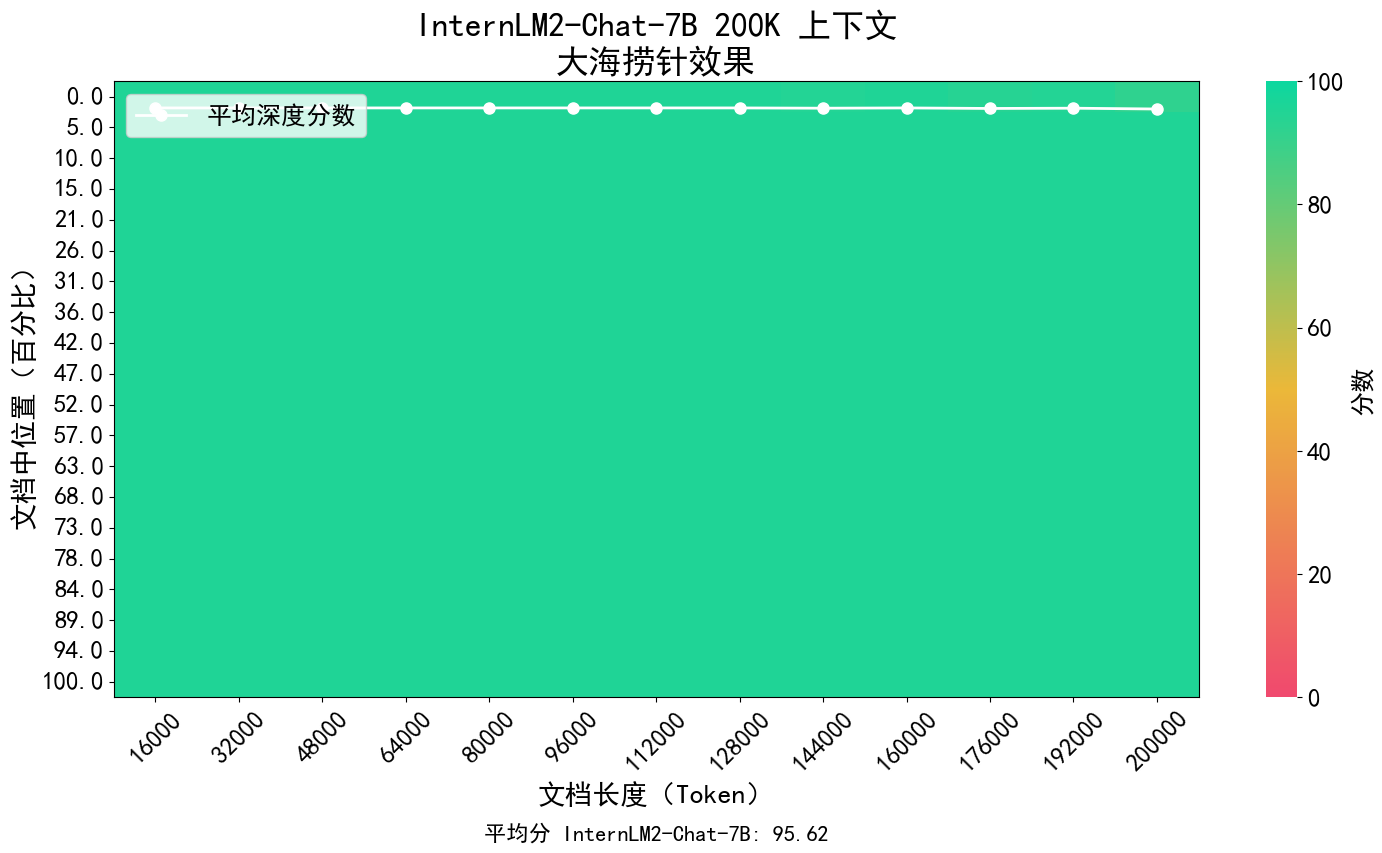
Das Kernkonzept von InternLM2 besteht darin, zum Wesen der Sprachmodellierung zurückzukehren, und setzt sich dafür ein, eine qualitative Verbesserung der Sprachmodellierungsfähigkeiten der Modellbasis zu erreichen, indem die Qualität des Korpus und die Informationsdichte verbessert werden und anschließend große Fortschritte in der Mathematik erzielt werden. Codierung, Dialog, Erstellung usw. Es wurden Fortschritte erzielt und die umfassende Leistung hat das führende Niveau von Open-Source-Modellen derselben Größenordnung erreicht. Es unterstützt den Kontext von 200.000 Token, empfängt und verarbeitet gleichzeitig Eingabeinhalte von etwa 300.000 chinesischen Schriftzeichen, extrahiert präzise Schlüsselinformationen und ermöglicht das „Finden der Nadel im Heuhaufen“ von Langtexten.
Darüber hinaus hat InternLM2 umfassende Fortschritte bei verschiedenen Funktionen erzielt: Im Vergleich zum InternLM der ersten Generation wurden seine Fähigkeiten in den Bereichen Argumentation, Mathematik, Codierung usw. erheblich verbessert und seine umfassenden Fähigkeiten liegen über dem gleichen Niveau von Open-Source-Modellen.
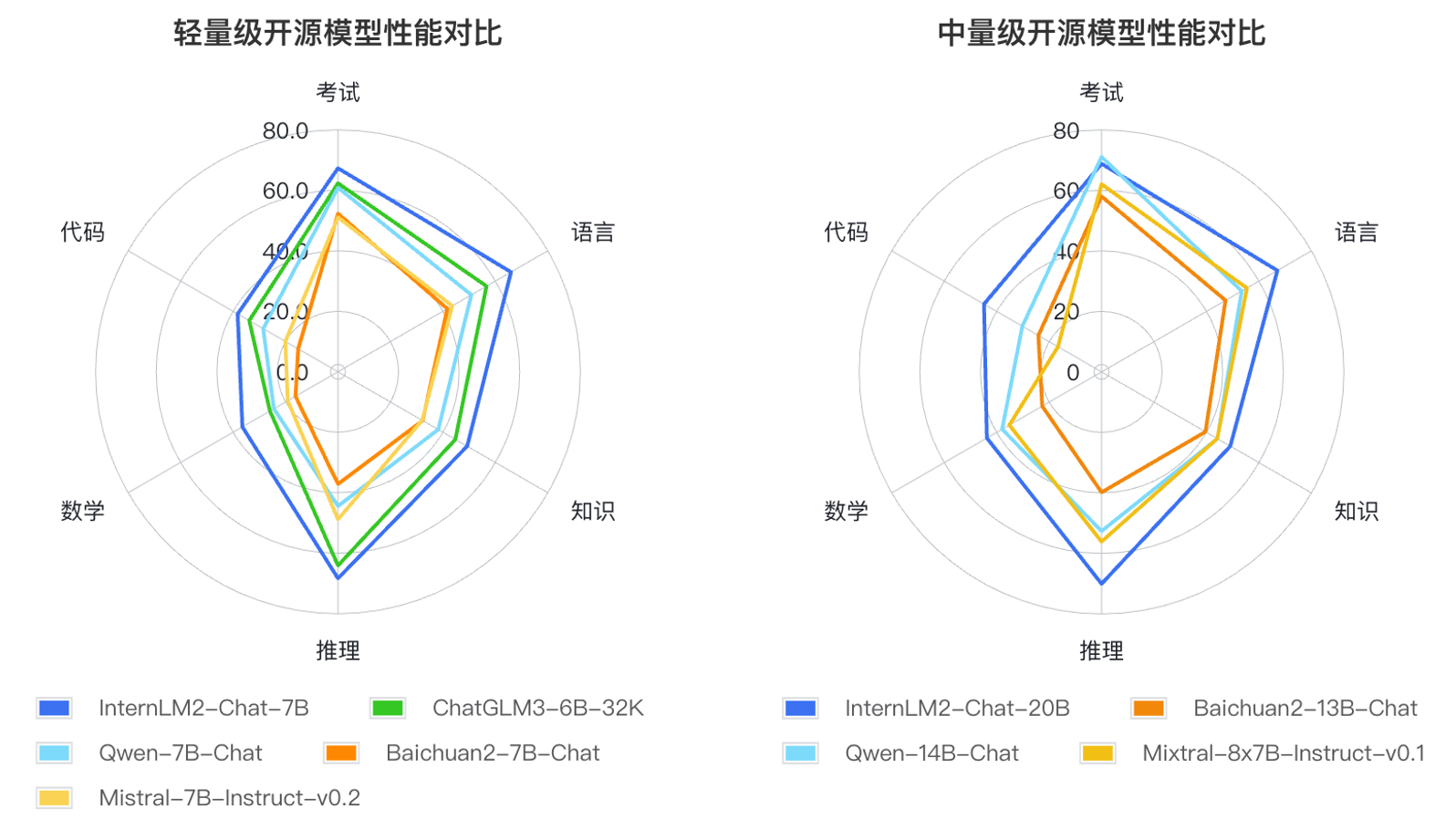
Basierend auf den Anwendungsmethoden großer Sprachmodelle und den Hauptanliegen der Benutzer definierten die Forscher sechs Kompetenzdimensionen wie Sprache, Wissen, Argumentation, Mathematik, Code und Prüfung und testeten die Leistung mehrerer Modelle derselben Größenordnung 55 Mainstream-Bewertungssätze. Die Leistung wurde umfassend bewertet. Die Evaluierungsergebnisse zeigen, dass die leichten (7B) und mittelschweren (20B) Versionen von InternLM2 bei Modellen gleicher Größe gut abschneiden.