1.Abstrakt
Die feinkörnige Vogelbilderkennung dient der genauen Klassifizierung von Vogelbildern und ist eine grundlegende Arbeit bei der visuellen Verfolgung von Robotern. Angesichts der Bedeutung der Überwachung und Erhaltung gefährdeter Vögel für den Schutz gefährdeter Vögel sind automatisierte Methoden erforderlich, um die Überwachung von Vögeln zu erleichtern. In dieser Arbeit schlagen wir eine neue Methode zur Vogelüberwachung vor, die auf der visuellen Verfolgung von Robotern basiert und ein affinitätsbewusstes Modell namens TBNet verwendet, das CNN- und Transformer-Architekturen mit dem Modul Novel Feature Selection (FS) kombiniert. Insbesondere wird CNN zum Extrahieren von Oberflächeninformationen verwendet. Verwenden Sie Transformer, um abstrakte semantische Affinitäten zu entwickeln. Zur Offenlegung von Identifikationsmerkmalen wird das FS-Modul eingeführt .
Umfangreiche Experimente zeigen, dass der Algorithmus sowohl beim Cub-200-201-Datensatz (91,0 %) als auch beim Nabbirds-Datensatz (90,9 %) eine Spitzenleistung erzielen kann.
2. Frage
Die feinkörnige Vogelbilderkennung ist eine grundlegende Aufgabe für die visuelle Verfolgung und Bildverarbeitung von Robotern [1-3]. Die autonome Verfolgung von Vögeln durch Roboter ohne menschliches Eingreifen ist für den Schutz gefährdeter Vögel von entscheidender Bedeutung. Derzeit sind einige gefährdete Vögel aufgrund der drohenden Umweltzerstörung vom Aussterben bedroht. Daher sind die Überwachung und der Schutz gefährdeter Vögel für den Vogelschutz von großer Bedeutung. Angesichts der Tatsache, dass fast die Hälfte der weltweiten Vogelpopulationen rückläufig ist und sich 13 % von ihnen „in einer sehr ernsten Situation“ befinden [4], hat der Schutz gefährdeter Vögel zunehmende Aufmerksamkeit auf sich gezogen. Um den Vogelschutz zu stärken, ist die Vogelbestandsüberwachung zu einem Forschungsschwerpunkt geworden. Aufgrund der extremen Feldbedingungen wie hohen Temperaturen in den Tropen und hoher Luftfeuchtigkeit in Regenwäldern war dies jedoch eine anspruchsvolle Aufgabe. Traditionell beobachten und erfassen Vogelforscher manuell Informationen über gefährdete Vögel in ihren Lebensräumen, was eine zeitaufwändige und arbeitsintensive Aufgabe ist. In den letzten Jahren wurden mit der Entwicklung der künstlichen Intelligenz viele Deep-Learning-Methoden für die feinkörnige Vogelbildklassifizierung (FBIC) vorgeschlagen. Daher scheitern nachgelagerte Aufgaben wie die Vogelüberwachung.
Durch sorgfältige Beobachtung des Aussehens von Vögeln haben wir die Affinität zwischen verschiedenen Teilen von Vögeln entdeckt, was für die FBIC-Forschung hilfreich ist. Wie in Abbildung 1 dargestellt, die Kombination aus Kopf und Schnabel eines Vogels oder das Farbmuster auf Kopf, Flügeln und Schwanz eines Vogels. Diese Affinitätsbeziehungen können als Unterscheidungsmerkmale von FBIC verwendet werden.

2.1 Entdeckung
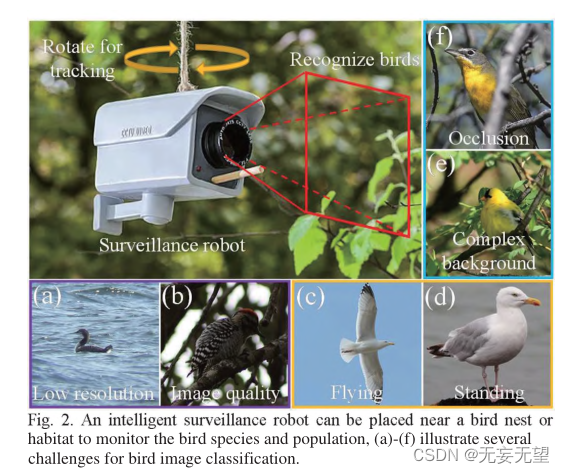
Die Identifizierung von Vögeln in freier Wildbahn ist jedoch auch mit einigen Herausforderungen verbunden. Erstens variiert die Bildqualität aufgrund der extrem wilden Umgebung. Beispielsweise können aus der Ferne aufgenommene Bilder eine niedrige Auflösung haben (Abbildung 2(a)) oder Bilder, die bei schwacher Beleuchtung aufgenommen wurden (Abbildung 2(a)). 2(b)), zweitens gibt es willkürliche Vogelhaltungen. Wie beispielsweise in Abbildung 2(e) und Abbildung 2(d) zu sehen ist, zeigt das erste Bild eine fliegende Silbermöwe, während das zweite Bild eine stehende Silbermöwe zeigt. Auf jedem Bild scheinen die Vögel ein anderes Aussehen zu haben, was eine weitere Schwierigkeit für das FBIC darstellt. Drittens können sich Vögel aufgrund der Verborgenheit und Komplexität wilder Hintergründe zwischen Ästen und Blättern aufhalten (Abbildung 2(e)) oder von Ästen aus beobachtet werden (Abbildung 2(f)), was die Klassifizierung von Vogelbildern erschwert .
2.2 Entwicklung
Da es von großer Bedeutung ist, die semantischen langfristigen abhängigen Affinitäten zwischen Vogelbildern zu identifizieren, ist Transformer eine Sprache, die von Natur aus gut darin ist, mikroskopisch feine Details und mikroskopische langfristige abhängige semantische Beziehungen in Bildern zu untersuchen. Transformer[5] wurde ursprünglich für die Verarbeitung natürlicher Sprache verwendet. Dann ließ er sich vom Bereich Computer Vision inspirieren. Carion et al. [6] schlugen eine auf Transformer basierende End-to-End-Zielerkennungsmethode vor. In [7] schlugen Dosovitskiy et al. Vision Transformer (ViT) vor, das zum ersten Mal angewendet wurde und bewies, dass es sich um einen reinen Transformer handelt Eine Methode, die mit CNN konkurrieren kann und die Struktur, die ihren Platz einnimmt. Daher wird die ViT-Struktur als Rückgrat unseres Modells verwendet, um die Affinitäten von FBIC-Aufgaben auszunutzen.
2.3 Innovation
In dieser Arbeit schlagen wir eine Methode vor, die für intelligente Vogelüberwachungsroboter (Abb. 2) verwendet werden kann, die in der Nähe von Futterhäuschen, Vogelnestern oder Vogellebensräumen installiert werden können. Der Roboter kann vertikal und horizontal rotieren, um ein breiteres Sichtfeld zum Erkennen von Vögeln zu bieten. Der Roboter nimmt in regelmäßigen Abständen Bilder auf und erhöht so die Häufigkeit, mit der ein Vogel im Bild erkannt wird. Ein großer Roboter ist mit einer Batterie mit großer Kapazität ausgestattet, die eine Langzeitüberwachung ermöglicht. Außerdem ist im Inneren des Roboters unser TBNet-Modellprogrammchip installiert, der Vögel in Echtzeit klassifizieren kann.
Während des Überwachungszeitraums wird die Häufigkeit des Vorkommens der Studienvögel berechnet und aufgezeichnet. Die gesammelten Informationen können dann von Vogelforschern genutzt werden, um Vogelpopulationen abzuschätzen und zu schützen. Das TBNet-Modell klassifiziert Vogelbilder, indem es Affinitätsbeziehungen in Vogelbildern identifiziert und so die Schätzung der Vogelpopulation flussabwärts erleichtert. Zusammenfassend sind die Hauptbeiträge dieser Arbeit wie folgt:
1) Es wird eine neue visuelle Roboterverfolgungsmethode zum Vogelschutz vorgeschlagen. Der smarte Überwachungsroboter kann sich in verschiedene Richtungen drehen und die Anzahl der Vögel aufzeichnen.
2) Ein effektives TBNet-Modell wurde etabliert. Unseres Wissens wurde diese Affinität zum ersten Mal in Vogelbildern offenbart. Daher wird ViT verwendet, um diese abstrakten semantischen Affinitäten auszunutzen. CNN wird zum Extrahieren von Oberflächeninformationen verwendet und das FS-Modul wird eingeführt, um Unterscheidungsmerkmale aufzudecken. Für die Feature-Map-Generierung des TBNet-Modells wird eine Feature-Extraktionsstrategie (CPG-Strategie) vorgeschlagen.
3) Führen Sie Experimente mit zwei Vogeldatensätzen durch, CUB-200-2011 und NABirds. Das vorgeschlagene TBNet erzielt im Vergleich zu mehreren bestehenden Methoden auf dem neuesten Stand der Technik eine bessere Leistung und bestätigt damit seine Wirksamkeit.
3.Netzwerk
3.1 Gesamtstruktur
Die Pipeline des TBNet-Modells ist in Abbildung 3 dargestellt. Die Methode besteht aus drei Teilen: Merkmalsextraktions -Backbone, FS-Modul und Klassifizierungskopf . Der erste Teil ist das Merkmalsextraktions-Backbone, mit dem feinkörnige und mehrskalige Informationen aus Vogelbildern extrahiert werden. Generell kommen mehrere aktuelle Backbones [1-3,7] als Kandidaten in Betracht. Da CNN über eine starke Fähigkeit verfügt, Oberflächeninformationen zu extrahieren, und Transformer hervorragend darin ist, abstrakte semantische Affinitätsbeziehungen zu ermitteln, verwendet diese Studie die Kombination von CNN und ViT als Rückgrat . Backbone wurde weiter modifiziert, um die Leistung zu verbessern. Um eine Überanpassung abzumildern, verfügt das entwickelte Netzwerk über eine Dropout-Schicht am Klassifizierungskopf des Backbones. Der zweite Teil ist das FS-Modul, das die Unterscheidungsmerkmale bestimmter Vögel extrahiert. Der dritte Teil ist der Klassifizierungskopf, in dem die Feature-Map schließlich zur endgültigen Klassifizierung verwendet wird.
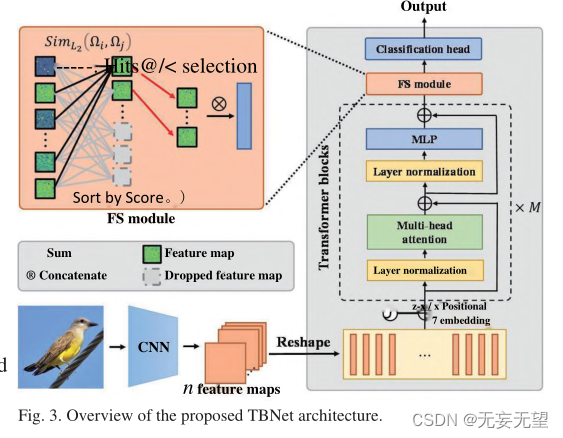
1. Verwenden Sie das CNN-Netzwerk, um vorläufige Merkmale des Bildes zu extrahieren, komprimieren Sie es dann in einen Patch und geben Sie ihn in das Vit-Netzwerk ein, das mehr globale Informationen des Bildes behalten kann, gleichzeitig aber auch einige auf niedriger Ebene Aufgrund der schichtweisen Faltung werden detaillierte Informationen ignoriert.
2. Das FS-Modul entspricht einer Bildverbesserung. Es erhöht das Gewicht wichtiger Bereiche, indem es Bereiche mit kleinen Beiträgen im Transformatorblock entfernt.
3.2 Feature-Map-Generierung
Die Vogelbilder werden über das Feature-Extraktions-Backbone verarbeitet und Feature-Karten generiert. Dieser Prozess kann in drei Schritte zusammengefasst werden: CNN-Verarbeitung, Positionseinbettung und Übergabe des Transformer-Blocks (CPG-Strategie). Nach Abschluss des Vorgangs wird das ursprüngliche Eingabebild zur Klassifizierung in eine Feature-Map umgewandelt.
Schritt I:CNN-Verarbeitung. In diesem Schritt wird das ursprüngliche Eingabebild zunächst über CNN verarbeitet, um n Feature-Maps zu generieren. Anschließend wird jede Merkmalskarte t in einen eindimensionalen Vektor planarisiert. Als nächstes wenden Sie eine lineare Projektion an, um pt in p[ zu projizieren. Dieser Vorgang drückt sich wie folgt aus:

In der Formel ist pt der i-te Patch, E die lineare Projektion und i der d-dimensionale projizierte visuelle Vektor.
Schritt II: Einbettung positionieren. Da die Transformer-Schicht gegenüber der Anordnung der Eingabe-Patch-Sequenz invariant ist, sind Positionseinbettungen erforderlich, um die räumlichen Positionen und Beziehungen von Patches zu kodieren. Konkret werden diese Patches durch positionelle Einbettung in Patch-Vektoren hinzugefügt. Die Einbettungsformel lautet wie folgt:

In der Formel stellt n eine aus Patch-Vektoren bestehende Matrix dar, n stellt die Anzahl der Patches dar und
stellt die Positionseinbettung dar. Die Art der Positionseinbettung kann aus mehreren Optionen ausgewählt werden, nämlich 2D-Sinusform, erlernbarer und relativer Positionseinbettung.
Schritt III: Gehen Sie den Transformer-Block durch. Der Positionseinbettungspatch wird dann durch M Transformer-Blöcke geleitet. Jeder Transformer-Block wird wie folgt berechnet:

wobei l und
die Ausgabe-Patch-Vektoren des MSA-Moduls bzw. des MLP-Moduls von Transformatorblock 1 sind. LN(-) zeigt die Schichtnormalisierung an. MLP repräsentiert mehrere vollständig verbundene Schichten. MSA bedeutet, dass Bullen auf sich selbst aufpassen. Diese Transformatorblöcke können in N Ebenen unterteilt werden.
3.3 FS-Modul
Der ursprüngliche Patch kann schädliche Funktionen einführen, die sich negativ auf die Klassifizierung auswirken. Abbildung 4 zeigt die Liste der Attributzuordnungen im Transformer-Block. In der letzten Phase werden die Feature-Maps anhand ihrer Unterscheidungswerte sortiert. Wie in Abbildung 4 dargestellt, weisen die Hits@k-Merkmale auf niedrigeren Ebenen wie Stufe 1 und Stufe 2 nahezu keine Ähnlichkeit zueinander auf, während die Merkmale mit schlechteren Bewertungen nahezu identisch miteinander sind. In höheren Schichten, wie z. B. Stufe N, sind die Hits@k-Funktionen ähnlicher und stärker aktiviert, während die Funktionen mit schlechteren Bewertungen verrauscht zu sein scheinen. Im Allgemeinen sind in jeder Phase hervorstechende Merkmale hoher Punktzahlen wichtiger als hervorstechende Merkmale niedriger Punktzahlen . Daher schlagen wir das FS-Modul vor, um die durch diese einzigartigen Merkmale bereitgestellten Informationen weiter zu nutzen und die schädlichen Auswirkungen destruktiver Merkmale wirksam abzumildern.
Angenommen, in Stufe i besteht die Ausgabe aus n ID-Patch-Vektoren, bezeichnet als Qj, dh [1,2,3,…,]. Zunächst berechnet das FS-Modul die Ähnlichkeit zwischen n Vektoren. Wählen Sie die Ähnlichkeit aus der Kosinusähnlichkeit oder dem Kehrwert des L2-Abstands aus. Kosinusähnlichkeit ist wie folgt definiert
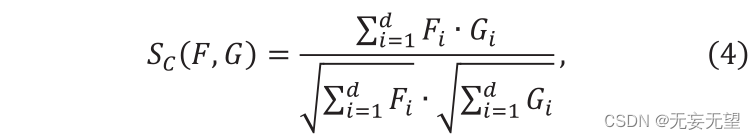
Wobei F ” und G ” zwei Vektoren sind, Sc (F,G) ∈[0,1]. Der Wert von Sc stellt die Ähnlichkeit zwischen F und g dar und sein L2-Abstand wird wie folgt konstruiert:
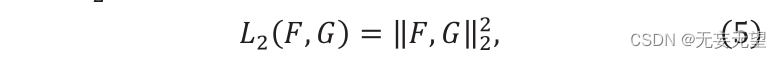
Wobei „F“ und „G“ zwei Merkmalsvektoren darstellen. Die Berechnungsformel für die Ähnlichkeit lautet wie folgt:
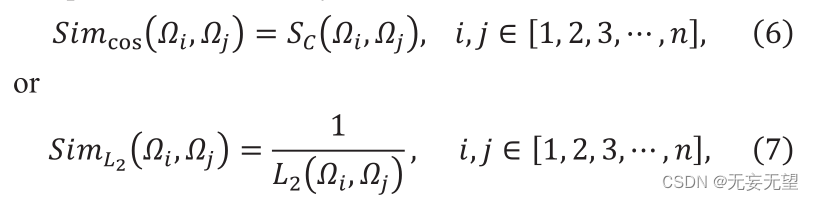
Darunter repräsentieren und
den i-ten bzw. j-ten Patch-Vektor. Sc stellt die Kosinusähnlichkeit dar,
die den Abstand darstellt
. Durch Berechnung der Ähnlichkeit kann die Ähnlichkeitsmatrix erhalten werden. Die Ähnlichkeitsmatrix, die die Ähnlichkeiten zwischen allen Patches enthält, kann wie folgt ausgedrückt werden:

Zweitens erhält jeder Patch-Vektor einen Diskriminanzwert, indem seine Ähnlichkeit zu anderen Patch-Vektoren addiert und eine Round-Trip-Operation durchgeführt wird. Die Betriebsformel lautet wie folgt:
 Schließlich wird der Hits@k (k)-Patch-Vektor mit der höchsten Punktzahl ausgewählt und in die nächste Ebene eingegeben. Die verbleibenden Patch-Vektoren werden verworfen, da sie weniger diskriminierend sind.
Schließlich wird der Hits@k (k)-Patch-Vektor mit der höchsten Punktzahl ausgewählt und in die nächste Ebene eingegeben. Die verbleibenden Patch-Vektoren werden verworfen, da sie weniger diskriminierend sind.

4. Experimentieren
4.1 Versuchsaufbau
4.1.1 Datensatz
CUB-200-2011, NABirds
4.1.2 Experimentelle Details
Das vorgeschlagene Modell wird auf folgende Weise umgesetzt. Für einen fairen Vergleich ändern Sie zunächst die Auflösung des Eingabebilds auf 448 bis 448. Um die Effizienz zu verbessern, ist die Chargengröße auf 8 eingestellt. Der AdamW-Optimierer wird verwendet und die Gewichtsdämpfung beträgt 0,05. Die Lernrate wird auf 0,0001 initialisiert. Alle Experimente wurden auf einer Nvidia TITAN GPU mit der PyTorch-Toolbox durchgeführt.
4.2 Vergleichstest


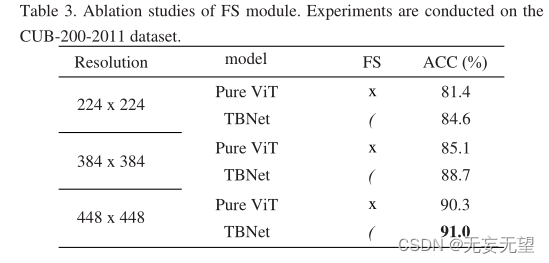
4.3 Ablationsexperiment
4.4 Visualisierung

5. Schlussfolgerung
In dieser Arbeit schlagen wir eine neue visuelle Trackingmethode für Vogelschutzroboter vor. Der smarte Überwachungsroboter kann sich in verschiedene Richtungen drehen und die Anzahl der Vögel aufzeichnen. Auf dieser Grundlage wird ein effektives TBNet-Modell erstellt. Soweit wir wissen, wurden erstmals Verwandtschaften in Vogelbildern aufgedeckt. CNNs werden verwendet, um oberflächliche Informationen zu extrahieren. Verwenden Sie ViT, um abstrakte semantische Affinitätsbeziehungen zu ermitteln. Zur Offenlegung von Identifikationsmerkmalen wird das FS-Modul eingeführt. Für die Feature-Map-Generierung des TBNet-Modells wird eine Feature-Extraktionsstrategie (CPG-Strategie) vorgeschlagen. Wir haben TBNet an zwei FBIC-Datensätzen getestet. Experimentelle Ergebnisse zeigen, dass diese Methode Affinitätsbeziehungen und Unterscheidungsmerkmale in Vogelbildern identifizieren kann. Angesichts der vielversprechenden Ergebnisse von TBNet kann man davon ausgehen, dass die visuelle Verfolgung von Vögeln durch Roboter großes Potenzial hat.