1. Einführung in die Plattform
Die selbstverwaltete Finanzabrechnung übernimmt hauptsächlich die Funktion der Übertragung der selbstverwalteten Daten von JD vom C-Ende zum B-Ende in der gesamten Lieferkette. Es handelt sich um eine spätere Stufe in der gesamten Lieferkette. Die Hauptfunktion des Systems ist die Abrechnung und Aggregation zum B-Ende.
2. Problembeschreibung
In den letzten Jahren ist die Menge der selbst betriebenen Abrechnungsdaten mit mehr als 10 Milliarden Datenmengen deutlich gestiegen, und die Zusammenfassung macht die Hälfte der Datenbankressourcen an einem Tag aus.
1. Suchen Sie jeden Tag Zehntausende Daten aus mehreren zehn Millionen W+ in einer einzigen Tabelle, um eine Zusammenfassung durchzuführen, d täglich.
2. Während des Aggregationszeitraums stagnierte das System grundsätzlich, was zu einer langsamen Verarbeitung von Nachrichten und Aufgaben, einem großen Rückstand und der Unfähigkeit führte, Daten zeitnah abzurechnen.
3. Die Datenbank steht unter großem Druck und kann jederzeit abstürzen.
4. Es wirkt sich auf das Lieferantenerlebnis aus. Während des großen Aktionszeitraums müssen Lieferanten Verkaufsdaten und Kampfberichte in Echtzeit überprüfen, und das System kann nicht rechtzeitig reagieren.
3. Einführung in die Originaltechnologie
Der Kern der Systemzusammenfassung basiert auf der physischen MySQL-Maschine, um die Gruppierung in jeder Datenbank und jeder Tabelle durchzuführen. Die Zusammenfassung wird nach Ausgabentyp unterteilt und erobert. Jeder Typ von Zusammenfassungsdimension ist anders. Jedes Mal, wenn eine neue Zusammenfassungsdimension eingeführt wird, Es muss von vorne nach hinten geschrieben werden. Die neue Zusammenfassungslogik besteht hauptsächlich darin, den Datenbereich der neuen Dimension zu sperren und die neue Gruppe nach Feld zu bestimmen. Die vorherige Logik musste einem Regressionstest unterzogen werden, was meiner Meinung nach dumm ist.
4. Ideen und Methoden zur Problemlösung
Bestimmen Sie auf der Grundlage des oben genannten Hintergrunds und der oben genannten Probleme eine grobe Lösung des Problems
1. Zunächst müssen wir uns von der MySQL-Zusammenfassung lösen. Die Datenbank ist sehr fragil. Wir müssen die Datenbank schützen, sonst wird die Größe weiter zunehmen und der Himmel wird eines Tages einstürzen.
2. Beheben Sie im Übrigen die Nachteile der wiederholten Entwicklung neuer Anforderungen.
5. Beschreibung des praktischen Ablaufs
Aufgrund des großen Volumens ist die T + 1-Verarbeitung im Unternehmen zulässig. Da es sich um eine Offline-Datenverarbeitung handelt, können im Allgemeinen an Spark, Spring Batch, Finlk usw. gedacht werden. In der technischen Forschungsphase stehen Reife und Community-Aktivität im Vordergrund berücksichtigt, wobei überwiegend die Spark-Technologie zum Einsatz kommt. Teilen Sie den Zusammenfassungsprozess in 4 Schritte auf. Um das Verständnis zu erleichtern, wird im Folgenden die Logik vereinfacht und kurz beschrieben.
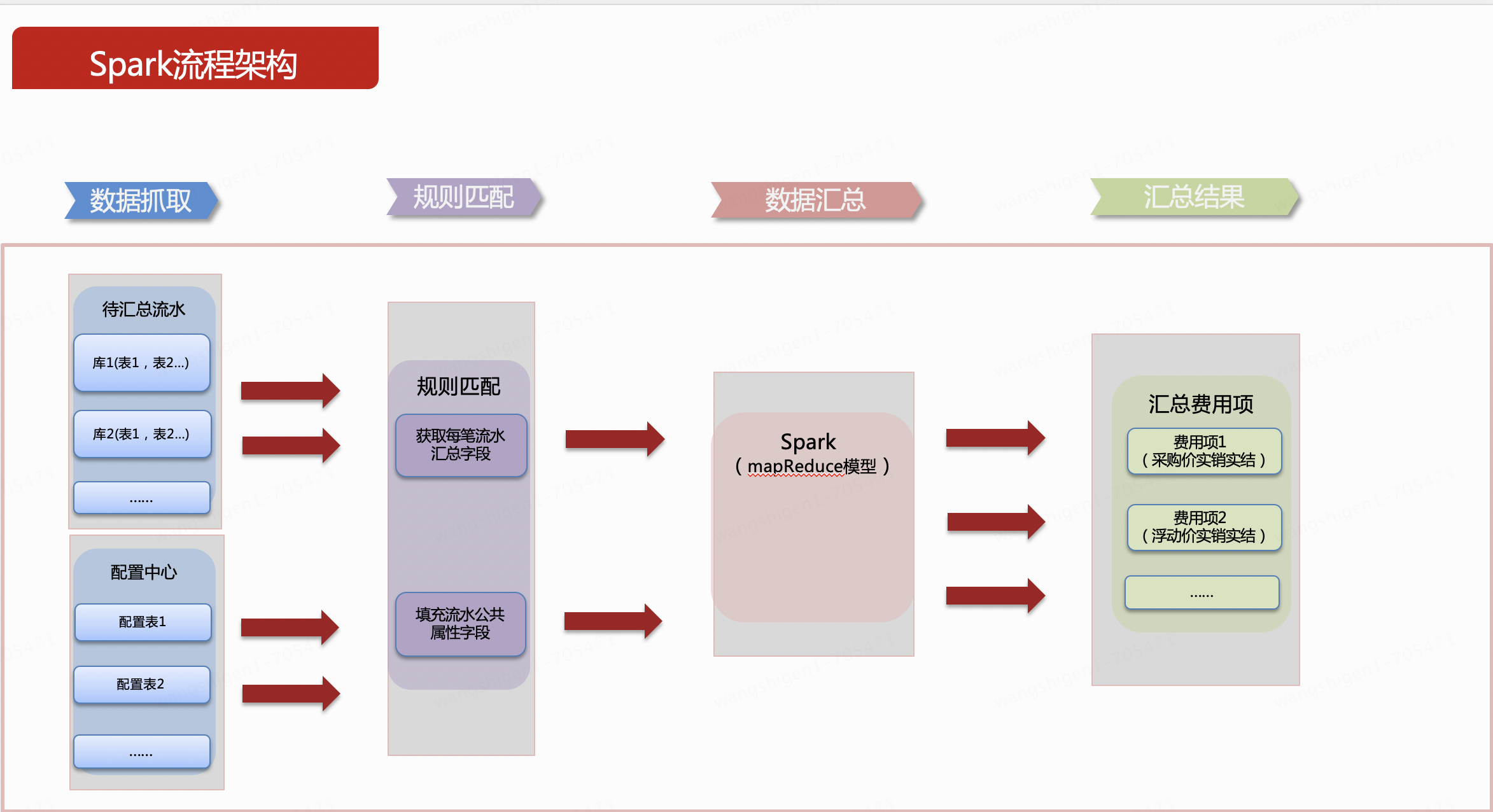
1. Datenerfassung
Bei den Daten vor der Aggregation handelt es sich um Geschäftsdaten. Typ bezieht sich im Allgemeinen auf das Feld, das den Datenkostentyp in die Geschäftsdaten unterteilt. ou und dept beziehen sich im Allgemeinen auf die Dimensionen der Quelldaten, bei denen es sich um ein oder mehrere andere Felder handeln kann. Betrag ist der Feld, das zusammengefasst und summiert werden soll. Hier wird der Betrag ausgedrückt.
Die Konfigurationstabelle wird aus den Quelldaten abgeleitet. Es kann viele Konfigurationsdaten geben, was ein allgemeiner Begriff ist. Dieses System verwendet nur eine Tabelle. Typ gibt an, dass der Ausgabentyp zur Verknüpfung mit den Quelldaten verwendet wird. Die Zuordnung kann einem oder mehreren Feldern zugeordnet werden. Hier wird ein Feld als Beispiel verwendet. merge_key ist ein Zusammenfassungsfeld und der Feldwert ist eins oder mehrere aus der Tabellenstruktur der Quelldaten. Feldzusammensetzung. bill_type stellt die öffentlichen Felder dar, die im aggregierten Ergebnissatz ausgefüllt werden müssen, und wird hier allgemein als Rechnungstyp bezeichnet. Es kann entsprechend den ausgefüllten Feldern erweitert werden. Wenn es erweitert wird, fügen Sie später einfach Spalten in der Konfigurationstabelle hinzu. Das folgende Beispieldiagramm drückt diese Bedeutung in einem einzelnen Feld aus.
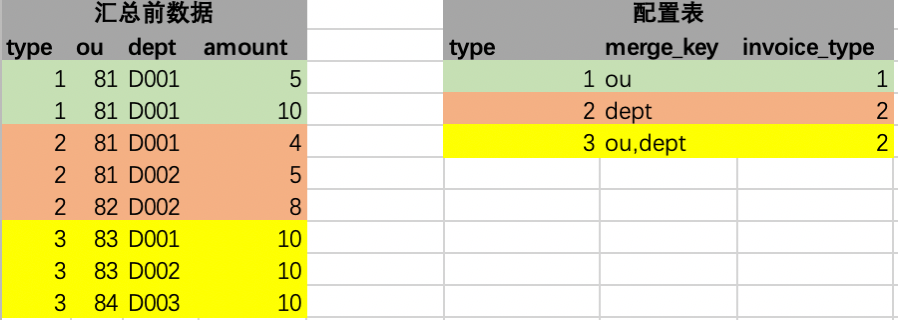
2. Regelabgleich
Die erste Verarbeitung wird durchgeführt, das heißt, jede Zeile in den Quelldaten wird mit der einzigen Zeile in der Konfigurationstabelle verknüpft, wie in der folgenden Abbildung dargestellt. Unter besonderen Anweisungen kann jede Zeile mit Quelldaten nur einer Zeile von zugeordnet werden Konfiguration in der Konfigurationstabelle. Das heißt, ein linker Join, der nicht zugeordnet werden kann, also keine Konfiguration hat, wird herausgefiltert und nicht zusammengefasst . Der erste Schritt des Verarbeitungsvorgangs wird im Speicher abgeschlossen.

Fahren Sie dann mit dem zweiten Verarbeitungsschritt fort. In diesem Schritt müssen wir das aus der Konfigurationstabelle entnommene Feld merge_key weiter in den spezifischen Wert des Felds analysieren, das der aktuellen linken Join-Zeile entspricht. Das analysierte Ergebnis ist wie folgt: In der Erklärung dieses Schritts wird entsprechend dem Feld von merge_key, z. B. der ersten Zeile ou, der Feldwert der entsprechenden Spalte dieser Zeile erhalten, nämlich 81. Das Prinzip wird implementiert durch Java-Reflexion. Es gibt jetzt verschiedene Open-Source-Tools Das Paket kann direkt verwendet werden, wie z. B. Federausdrücke und andere Tools. Analog können auch die Werte mehrerer Felder ermittelt werden. Mehrere Felder können gemäß bestimmten Verbindungssymbolen gespleißt werden. Diese Zahl wird mit _ gespleißt. Gleichzeitig werden auch gefüllte Felder hinzugefügt.
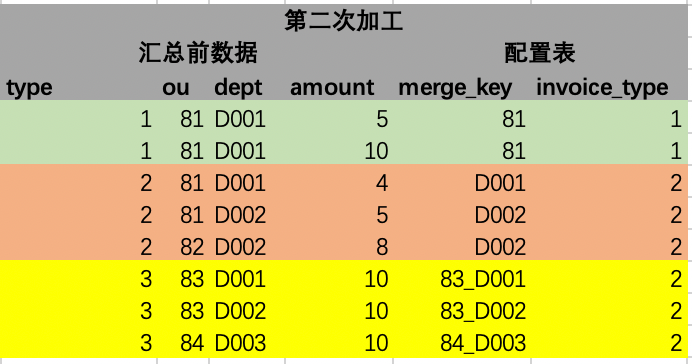
3. Datenzusammenfassung
Nachdem die Regelübereinstimmungsdaten verarbeitet wurden, müssen wir nur noch das verarbeitete Feld merge_key zusammenfassen. Die Zusammenfassungs-Engine muss nur dem festen Zusammenfassungsfeld folgen (das Beispiel hier ist das Feld merge_key nach der Verarbeitung im zweiten Schritt), und die Zusammenfassungslogik ist Es kann verfestigt werden, und es ist nur ein allgemeines SQL erforderlich, um die Zusammenfassung aller Ausgabentypen zu implementieren und das endgültige Zusammenfassungsergebnis zu generieren.
4. Zusammenfassende Ergebnisse
Die aggregierten Daten können dieselben Ergebnisse liefern wie die durch die ursprüngliche Technologie aggregierten Daten, und gleichzeitig können einige gemeinsame Felder ausgefüllt werden. Wie in der Abbildung unten gezeigt, werden die grünen 2 Zeilen mit Quelldaten von ou zusammengefasst und werden zu einer Zeile in der Ergebnistabelle; die orangefarbenen 3 Zeilen mit Quelldaten werden von dept zusammengefasst und zu 2 Zeilen in der Ergebnistabelle; die gelbe Quelle Die Daten werden durch die Felder „ou“ und „dept“ zusammengefasst. Die Zusammenfassung besteht aus 3 Zeilen.

Schreiben Sie abschließend die zusammenfassenden Ergebnisse zurück in MySQL.
6. Praktisches Prozessdenken und Wirkungsbewertung
1. Während des Überprüfungsprozesses der Testumgebung weisen die Testtabelle und die Online-Tabelle unterschiedliche numerische Ebenen auf. Beim ersten Online-Start war das Lesen der Daten extrem langsam. Da Spark eine einzelne Tabelle sehr schnell liest, sinkt die Effizienz beim Lesen von Daten aus Unterdatenbanken und Untertabellen. Hier wird eine Multithreading-Methode verwendet, um die nicht zusammengefassten Daten, die die Bedingungen erfüllen, zu lesen und schließlich einen großen Satz zusammenzufassen.
2. Nachdem Sie online gegangen sind und über einen bestimmten Zeitraum stabil ausgeführt haben, zeigt das Leistungsvergleichsdiagramm, dass durch das Entfernen der Gruppe nach Vorgängen in MySQL die Zusammenfassungszeit verkürzt, die Datenbankleistung verbessert und die Fähigkeit zum Verarbeiten von Nachrichten usw. verbessert wurde Auch asynchrone Aufgaben haben sich verbessert und wirken sich auf die Gesamtsituation aus.
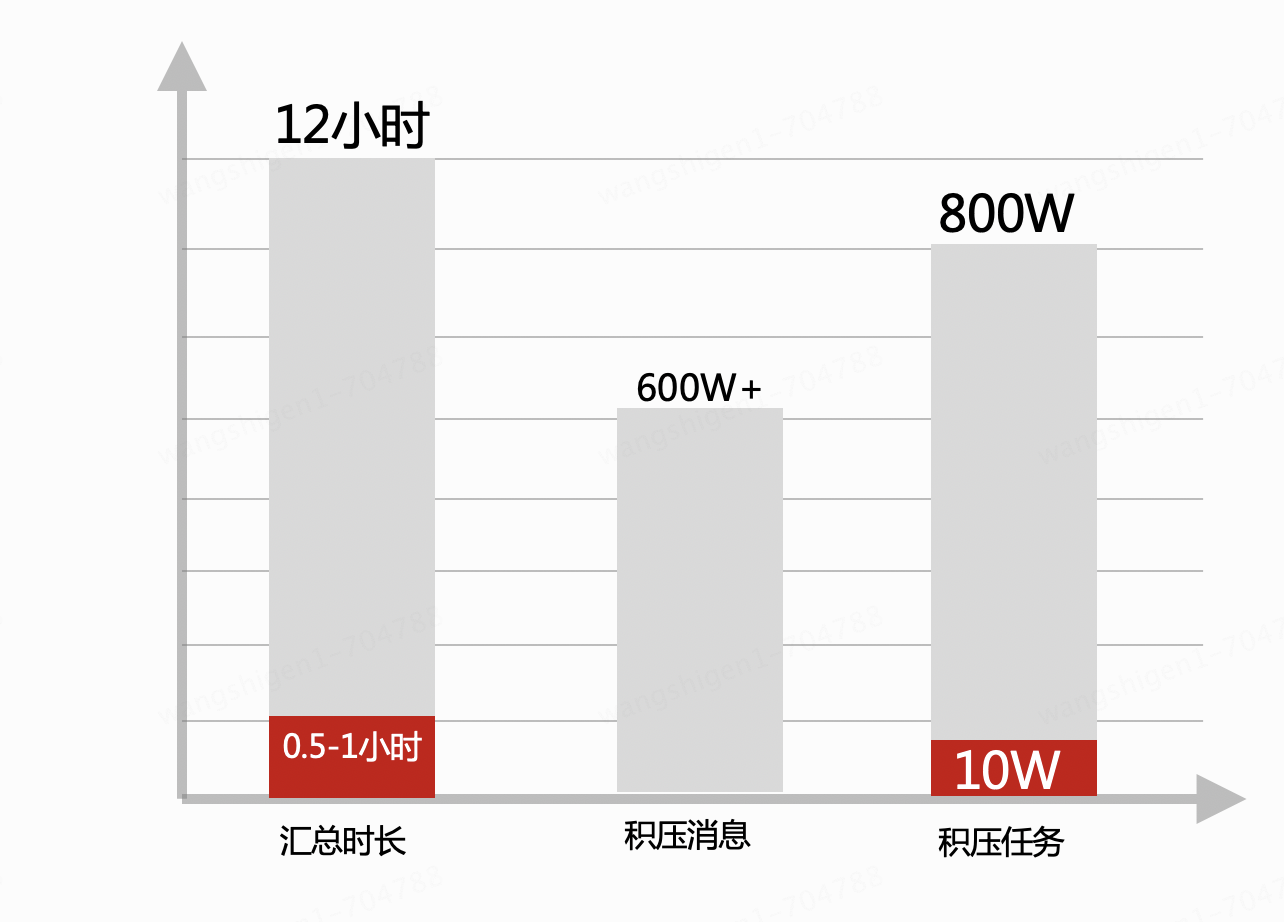
3. Wenn in Zukunft neue zusammenfassende Anforderungen online gehen, kann die neue Dimensionszusammenfassungsfunktion durch Konfiguration implementiert werden, was die Forschungs- und Entwicklungsarbeit vereinfacht und die Pünktlichkeit der Bedarfslieferung verbessert. Es gibt auch Nachteile: Derzeit müssen die Felder der Zusammenfassungsdimensionen aus der Haupttabelle entnommen werden, da Spark beim Lesen von Geschäftsdaten nur die Haupttabelle und nicht die erweiterte Tabelle liest. Wenn Sie von der Datenqualität der Hive-Tabelle in Zukunft überzeugt sind, können Sie sie in Spark ändern, um die Hive-Tabelle direkt zu lesen, oder aus es, ck und anderen Bibliotheken lesen.
4. Durch die Einführung des Spark-Frameworks wird die große Datenbankzusammenfassung von online auf offline umgestellt, wodurch die Datenbank entlastet wird. Nach der Verbesserung der Datenbankleistung wird auch die Effektivität der Abrechnung verbessert und die Stabilität erhöht das System und verbessert die Erfahrung des Lieferanten.
Autor: Wang Shigen
Quelle: JD Cloud Developer Community Bitte geben Sie beim Nachdruck die Quelle an
npm wird missbraucht – jemand hat mehr als 700 Wulin-Gaiden-Slice-Videos hochgeladen „Linux China“ Die Open-Source-Community kündigte an, den Betrieb einzustellen. Microsoft hat ein neues Team gebildet, um beim Neuschreiben der Windows-Kernbibliothek mit Rust zu helfen. Der gebündelte KI-Assistent JetBrain sorgte für Unzufriedenheit bei den Nutzern der Deutschen Bahn rekrutiert Personen, die mit MS vertraut sind - IT-Administratoren von DOS und Windows 3.11 VS Code 1.86 wird dazu führen, dass die Remote-Entwicklungsfunktion nicht verfügbar ist. FastGateway: ein Gateway, das als Ersatz für Nginx verwendet werden kann. Visual Studio Code 1.86 wird veröffentlicht . Sieben Abteilungen, darunter die Das Ministerium für Industrie und Informationstechnologie hat gemeinsam ein Dokument herausgegeben: Entwickeln Sie das Betriebssystem der nächsten Generation und fördern Sie die Open-Source-Technologie. , Aufbau eines Open-Source-Ökosystems Windows Terminal Preview 1.20 veröffentlicht