Große Sprachmodelle bringen den Stand der Technik in der Verarbeitung natürlicher Sprache voran. Sie sind jedoch in erster Linie für Englisch oder eine begrenzte Anzahl von Sprachen konzipiert, wodurch bei ressourcenarmen Sprachen eine große Lücke in ihrer Wirksamkeit entsteht. Um diese Lücke zu schließen, haben Forscher der Universität München, der Universität Helsinki und andere Forscher gemeinsam MaLA-500 als Open-Source-Lösung entwickelt, das ein breites Spektrum von 534 Sprachen abdecken soll.
MaLA-500 basiert auf LLaMA 2 7B und verwendet dann den mehrsprachigen Datensatz Glot500-c für das Spracherweiterungstraining. Die experimentellen Ergebnisse der Forscher zu SIB-200 zeigen, dass MaLA-500 kontextlernende Ergebnisse auf dem neuesten Stand der Technik erzielt hat.
Glot500-c enthält 534 Sprachen, die 47 verschiedene ethnische Sprachen abdecken, mit einem Datenvolumen von bis zu 2 Billionen Token. Die Forscher sagten, der Grund für die Wahl des Glot500-c-Datensatzes sei, dass er die Sprachabdeckung bestehender Sprachmodelle erheblich erweitern könne und eine äußerst reichhaltige Sprachfamilie enthalte, was für das Modell eine große Hilfe beim Erlernen der inhärenten Grammatik und Semantik sei Regeln der Sprache.
Obwohl der Anteil einiger ressourcenintensiver Sprachen relativ gering ist, reicht das Gesamtdatenvolumen von Glot500-c außerdem aus, um umfangreiche Sprachmodelle zu trainieren. In der anschließenden Vorverarbeitung wurde eine gewichtete Zufallsstichprobe am Korpusdatensatz durchgeführt, um den Anteil ressourcenarmer Sprachen in den Trainingsdaten zu erhöhen und dem Modell eine stärkere Fokussierung auf bestimmte Sprachen zu ermöglichen.
Basierend auf LLaMA 2-7B hat MaLA-500 zwei wichtige technologische Innovationen vorgenommen:
- Um den Wortschatz zu erweitern, trainierten die Forscher einen mehrsprachigen Wortsegmentierer mithilfe des Glot500-c-Datensatzes und erweiterten so den ursprünglichen englischen Wortschatz von LLaMA 2 auf 2,6 Millionen, wodurch die Anpassungsfähigkeit des Modells an nicht-englische und ressourcenarme Sprachen erheblich verbessert wurde.

- Die Modellverbesserung nutzt die LoRA-Technologie, um eine Low-Rank-Anpassung basierend auf LLaMA 2 durchzuführen. Nur das Training der Anpassungsmatrix und das Einfrieren der Grundmodellgewichte können die kontinuierliche Lernfähigkeit des Modells in neuen Sprachen effektiv realisieren und gleichzeitig das ursprüngliche Wissen des Modells beibehalten.
Trainingsprozess
Was das Training angeht, verwendeten die Forscher 24 N-Card-A100-GPUs für das Training und drei gängige Deep-Learning-Frameworks, darunter Transformers, PEFT und DeepSpeed.
Unter anderem bietet DeepSpeed Unterstützung für verteiltes Training und kann Modellparallelität erreichen; PEFT implementiert eine effiziente Modellfeinabstimmung; Transformers bietet die Implementierung von Modellfunktionen wie Textgenerierung, schnelles Wortverständnis usw.
Um die Effizienz des Trainings zu verbessern, verwendet MaLA-500 auch verschiedene Speicher- und Rechenoptimierungsalgorithmen, wie den redundanten ZeRO-Optimierer, der die Nutzung von GPU-Rechenressourcen maximieren kann, und das bfloat16-Zahlenformat für gemischtes Präzisionstraining, um das zu beschleunigen Trainingsprozess.
Darüber hinaus führten die Forscher zahlreiche Optimierungen an den Modellparametern durch, indem sie herkömmliches SGD-Training mit einer Lernrate von 2e-4 und eine L2-Gewichtungsdämpfung von 0,01 verwendeten, um zu verhindern, dass das Modell zu groß, überpassend und instabil wird Inhaltsausgabe usw. Bedingung.
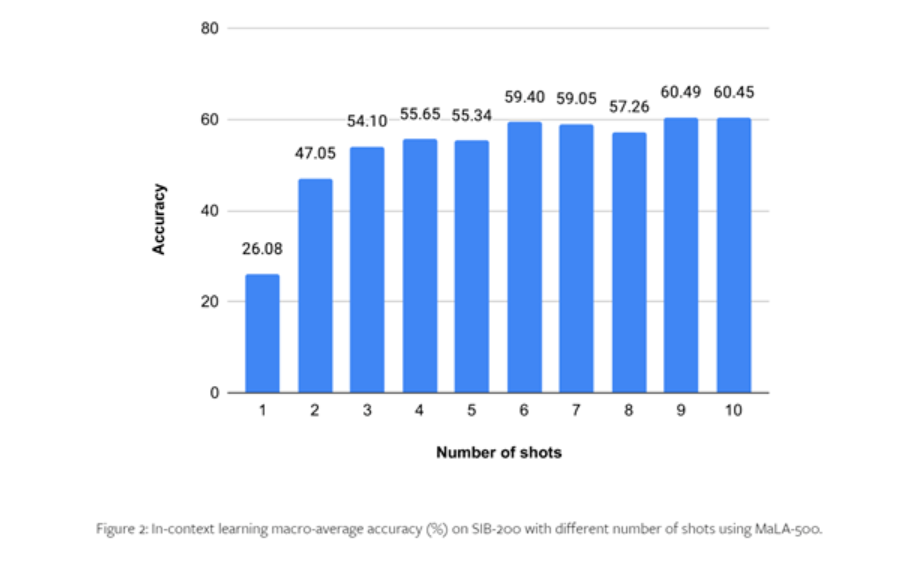
Um die Leistung von MaLA-500 zu testen, führten die Forscher umfangreiche Experimente mit Datensätzen wie SIB-200 durch.
Die Ergebnisse zeigen, dass die Genauigkeit von MaLA-500 bei Bewertungsaufgaben wie der Themenklassifizierung im Vergleich zum ursprünglichen LLaMA 2-Modell um 12,16 % erhöht wurde, was zeigt, dass die Mehrsprachigkeit von MaLA-500 vielen bestehenden Open-Source-Modellen für große Sprachen überlegen ist .
Weitere Details finden Sie im vollständigen Artikel .