1. Einführung in Datensätze
Der CIFAR-10-Datensatz besteht aus 60.000 32x32- Farbbildern in 10 Kategorien , 6000mit 1 Bild in jeder Kategorie. Es gibt 50000Trainingsbilder und 10000Testbilder.
Der Datensatz ist in 5 Trainingsstapel und 1 Teststapel unterteilt. Jeder Stapel enthält 10.000 Bilder. Der Teststapel enthält genau 1000 zufällig ausgewählte Bilder aus jeder Klasse. Die Trainingsstapel enthalten die verbleibenden Bilder in zufälliger Reihenfolge, einige Trainingsstapel enthalten jedoch möglicherweise mehr Bilder aus einer Klasse als aus einer anderen. Insgesamt enthält der Trainingsstapel genau 5000 Bilder aus jeder Klasse.
Zusammenfassen:
Size(大小):32×32 RGB-Bild, der Datensatz selbst ist BGR-Kanal,
Num(数量):Trainingssatz 50.000 und Testsatz 10.000, insgesamt 60.000 Bilder
Classes(十种类别):Flugzeug (Flugzeug), Auto (Auto), Vogel (Vogel), Katze (Katze), Hirsch (Hirsch). ), Hund (Hund), Frosch (Frosch), Pferd (Pferd), Schiff (Schiff), LKW (Lastwagen)

Download-Link
Dream是个帅哥Teilen von Blogger ( ):
Link: https://pan.baidu.com/s/1gKazlkk108V_1nrc68VoSQ Extraktionscode: 0213
Datensatzordner
CIFAR-100-Datensatz (erweitert)
Dieser Datensatz ähnelt CIFAR-10, außer dass er 100 Klassen hat und jede Klasse 600 Bilder enthält. Für jede Klasse gibt es 500 Trainingsbilder und 100 Testbilder. Die 100 Unterkategorien in CIFAR-100 sind in 20 große Kategorien unterteilt. Jedes Bild hat ein Tag „fein“ (die Unterkategorie, zu der es gehört) und ein Tag „grob“ (die Hauptkategorie, zu der es gehört).
Vergleich zwischen CIFAR-10-Datensatz und MNIST-Datensatz
- Die Dimensionen sind unterschiedlich: Der CIFAR-10-Datensatz hat 4 Dimensionen und der MNIST-Datensatz hat 3 Dimensionen (die vier Dimensionen von CIRAR-10: die Anzahl der Proben gleichzeitig, die Bildhöhe, die Bildbreite, die Anzahl). der Bildkanäle -> NHWC; die drei Dimensionen von MNIST: einmal Anzahl der Samples, Bildhöhe, Bildbreite -> NHW)
- Die Bildtypen sind unterschiedlich: Der CIFAR-10-Datensatz ist ein RGB-Bild (mit drei Kanälen) und der MNIST-Datensatz ist ein Graustufenbild, weshalb der CIFAR-10-Datensatz eine Dimension mehr hat als der MNIST-Datensatz .
- Der Inhalt der Bilder ist unterschiedlich: Der CIFAR-10-Datensatz zeigt eine Vielzahl unterschiedlicher Objekte (Katzen, Hunde, Flugzeuge, Autos...) und der MNIST-Datensatz zeigt handgeschriebene Zahlen 0 bis 9 von verschiedenen Personen.
2. Lesen des Datensatzes
Lesen Sie den Datensatz
Wählen Sie data_batch_1 aus, um eines der Bilder anzuzeigen:
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
print(dict)
Ausgabeergebnisse:
Es gibt 4 Wörterbuchschlüssel in einem Datensatzstapel. Was wir verwenden müssen, ist die Datenbeschriftung und der Dateninhalt (10000 × 32 × 32 × 3, 10000 32 × 32 RGB-Dreikanalbilder). Die

Ausgabe ist ein Wörterbuch :
{ b'batch_label': b'training batch 1 of 5', b'labels': [6, 9 … 1,5], b'data': array([[ 59, 43, …, 84, 72], …[ 62, 61, 60, …, 130, 130, 131]], dtype=uint8), b'filenames': [b'leptodactylus_pentadactylus_s_000004.png',…b'cur_s_000170.png'] }
Unter diesen ist die Bedeutung jedes Vertreters wie folgt:
b'batch_label': der Dateisatz, zu dem er gehört,
b'labels': Bildetikett
b'data' : Bilddaten
b'filename' : Bildname
Lesetyp
print(type(dict[b'batch_label']))
print(type(dict[b'labels']))
print(type(dict[b'data']))
print(type(dict[b'filenames']))
Ausgabeergebnis:
<class 'bytes'>
<class 'list'>
<class 'numpy.ndarray'>
<class 'list'>
Bilder lesen
img = dict[b'data']
print(img.shape)
Ausgabeergebnis: (10000, 3072), wobei 3072 = 32 * 32 * 3 (Bildgröße)
3. Datensatzaufruf
TensorFlow-Aufrufe
from tensorflow.keras.datasets import cifar10
(x_train,y_train), (x_test, y_test) = cifar10.load_data()
lokaler Anruf
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
4. Faltungstraining für neuronale Netze
Referenz hier: Portal
1.GPU angeben
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0],True)
#初始化
plt.rcParams['font.sans-serif'] = ['SimHei']
2. Daten laden
cifar10 = tf.keras.datasets.cifar10
(train_x,train_y),(test_x,test_y) = cifar10.load_data()
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s'%(train_x.shape,train_y.shape,test_x.shape,test_y.shape))
3. Datenvorverarbeitung
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32) #归一化
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
4. Erstellen Sie ein Modell
Die Adam-Algorithmus-Parameter verwenden die standardmäßigen öffentlichen Parameter von Keras, die Verlustfunktion verwendet die Sparse-Cross-Entropy-Loss-Funktion und die Genauigkeit verwendet die Sparse-Klassifizierungsgenauigkeitsfunktion.
model = tf.keras.Sequential()
##特征提取阶段
#第一层
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu,data_format='channels_last',input_shape=X_train.shape[1:])) #卷积层,16个卷积核,大小(3,3),保持原图像大小,relu激活函数,输入形状(28,28,1)
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2))) #池化层,最大值池化,卷积核(2,2)
#第二层
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2)))
##分类识别阶段
#第三层
model.add(tf.keras.layers.Flatten()) #改变输入形状
#第四层
model.add(tf.keras.layers.Dense(128,activation='relu')) #全连接网络层,128个神经元,relu激活函数
model.add(tf.keras.layers.Dense(10,activation='softmax')) #输出层,10个节点
print(model.summary()) #查看网络结构和参数信息
#配置模型训练方法
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
5.Trainieren Sie das Modell
Die Batch-Trainingsgröße beträgt 64, die Iteration beträgt 5 und das Testsatzverhältnis beträgt 0,2 (48.000 Trainingssatzdaten, 12.000 Testsatzdaten).
history = model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
6. Bewerten Sie das Modell
model.evaluate(X_test,y_test,verbose=2) #每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力
#保存整个模型
model.save('CIFAR10_CNN_weights.h5')
7. Visualisierung der Ergebnisse
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['sparse_categorical_accuracy'] #训练集准确率
val_acc = history.history['val_sparse_categorical_accuracy'] #测试集准确率
plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('loss')
plt.legend()
plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
8. Verwenden Sie Modelle
plt.figure()
for i in range(10):
num = np.random.randint(1,10000)
plt.subplot(2,5,i+1)
plt.axis('off')
plt.imshow(test_x[num],cmap='gray')
demo = tf.reshape(X_test[num],(1,32,32,3))
y_pred = np.argmax(model.predict(demo))
plt.title('标签值:'+str(test_y[num])+'\n预测值:'+str(y_pred))
plt.show()
Ausgabeergebnisse:

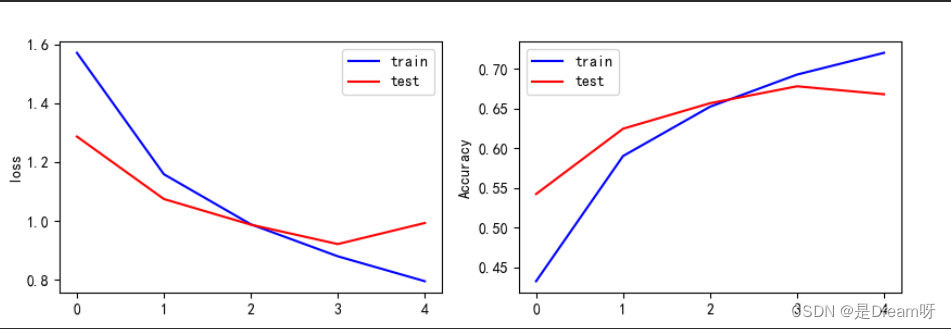
Der obige Inhalt ist der Verlustfunktionswert und die Genauigkeit der Trainingsprobe sowie der Verlustfunktionswert und die Genauigkeit der Testprobe. Sie können die Änderungen der Verlustfunktion und der Genauigkeit in jeder Trainingsiteration sehen, beginnend mit der letzten Iterationsergebnis. Es scheint, dass der Verlustfunktionswert der Testprobe 0,9123 erreicht und die Genauigkeit nur 0,6839 erreicht.
Dieses Ergebnis ist nicht sehr gut. Ich habe versucht, die Anzahl der Iterationen zu erhöhen, und festgestellt, dass der Verlustfunktionswert der Trainingsstichprobe 0,04 und die Genauigkeit 0,98 erreichen konnte. Tatsächlich erzeugte das Trainingsmodell jedoch zunehmende Generalisierungsfehler. Dies ist Training Das Phänomen des Übermaßes besteht darin, dass nach dem Ausprobieren die beste Generalisierungsfähigkeit bei der 5. Iteration liegt, sodass wir uns nur für eine 5-malige Iteration entscheiden können.

Trainierte Modelldatei – direkt verwenden
Einführung in den CIFAR10-Datensatz und die Verwendung von Faltungs-Neuronalen Netzen zum Trainieren von Bildklassifizierungsmodellen – vollständiger Code und trainierte Modelldateien im Anhang – direkt verwenden: https://download.csdn.net/download/weixin_51390582/88788820