
Das Empfehlungssystem ist ein Informationsfiltersystem, das dazu dient, Benutzerpräferenzen vorherzusagen und aus einer großen Menge an Informationen Inhalte herauszufiltern, die den Benutzer interessieren könnten, um personalisierte Empfehlungen abzugeben. Ein vollständiger Empfehlungssystemprozess umfasst hauptsächlich Verarbeitungsknoten wie Mehrkanalrückruf -> Materialvervollständigung -> Feinsortierung und Filterung -> Gemischte Sortierung -> Anpassungsausgabe. Als letzte Verarbeitungsebene vor der Ergebnisausgabe wird das Mischen hauptsächlich zum Normalisieren und Sortieren der Empfehlungsergebnisse aus verschiedenen Quellen verwendet. Einerseits dient es dazu, die Sortierreihenfolge mit dem besten Empfehlungseffekt für Benutzer zu erhalten, und andererseits Es kann auch die Vielfalt, Personalisierung und Reichweite von Empfehlungen verbessern.

▐Bestehender Link
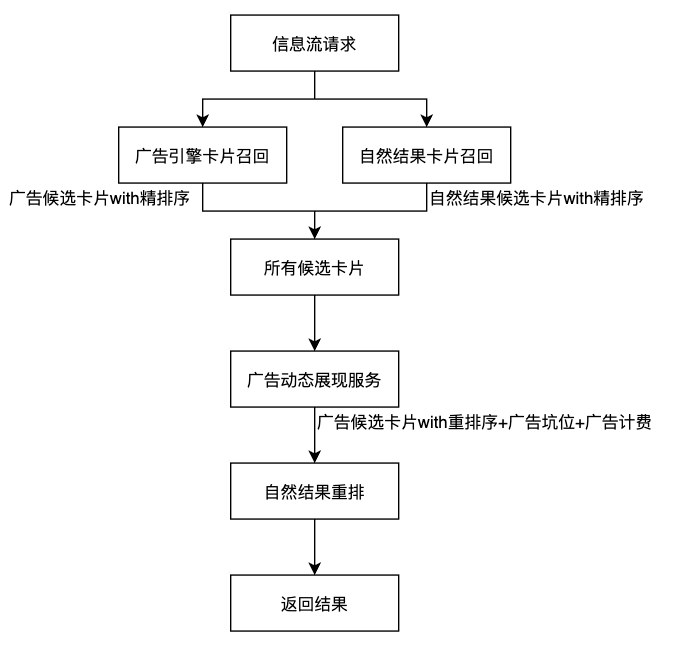
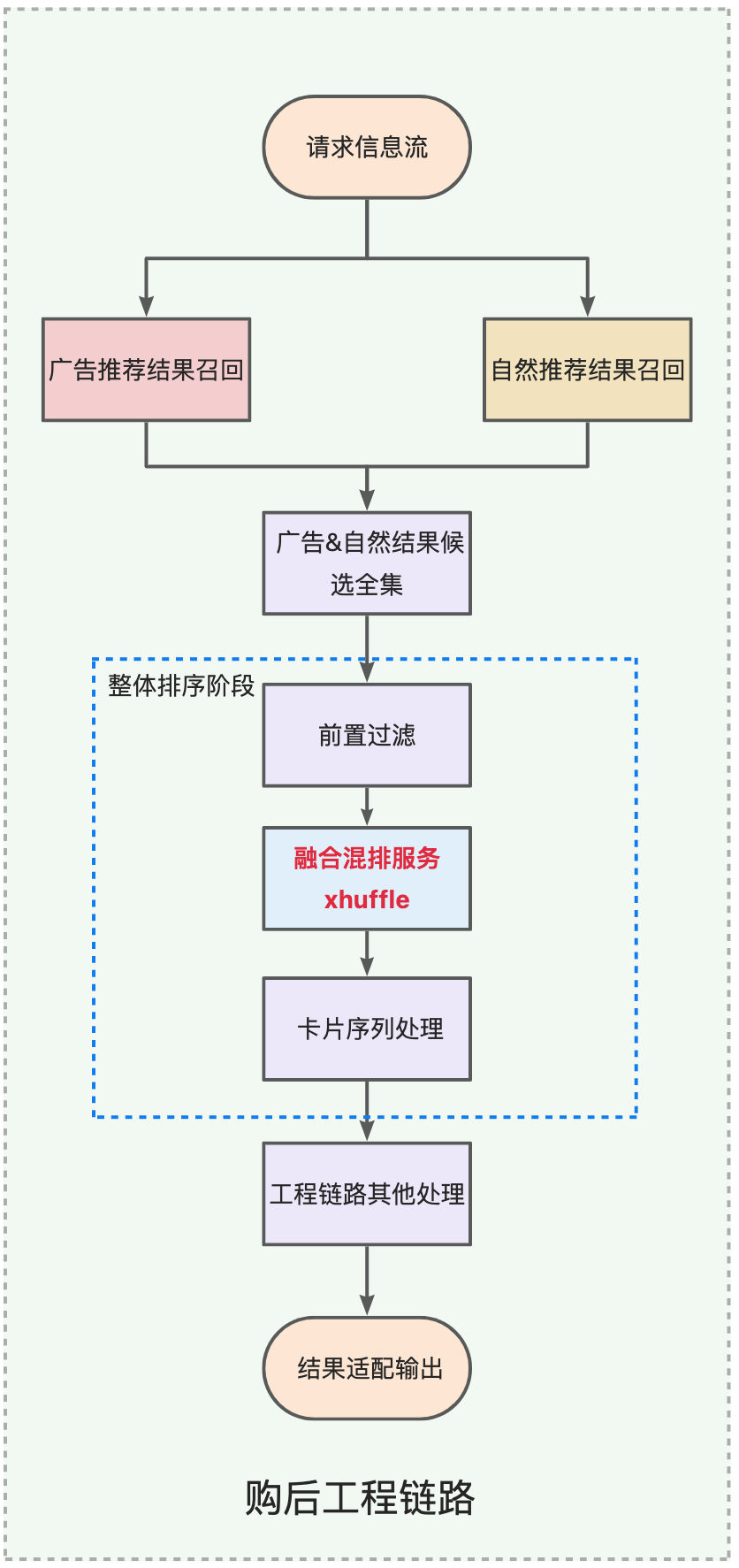
Der Informationsfluss von Taobao ist ein typisches Empfehlungssystem. Im Informationsfluss gibt es viele Arten von Visitenkarten, wie z. B. Produkte, Werbung, Cloud-Themen, Kurzvideos, Live-Übertragungen usw. Wir werden Visitenkarten in zwei Kategorien einteilen: Werbeergebnisse und natürliche Empfehlungsergebnisse. In der Sortierphase werden zwei serielle Verarbeitungsmodule in zwei verschiedene Ergebnistypen unterteilt, um sie zu mischen und zu sortieren.
-
Werbeergebnisse : Werbung verwendet hauptsächlich eine dynamische Pit-Anzeigestrategie. Durch Aufrufen des von der Werbung bereitgestellten dynamischen Anzeigedienstes wird entschieden, in welchen Pits Werbung angezeigt werden soll, welche Werbeergebnisse speziell angezeigt werden und welche Werbeabrechnungen erfolgen. Das Entscheidungsziel ist eine optimale Kommerzialisierung . Wert. Bei der Entscheidungsfindung werden alle empfohlenen Kandidatensätze als kontextbezogene Merkmale eingegeben, die Reihenfolge der natürlichen Ergebnisse wird jedoch nicht festgelegt. -
Natürliche Ergebnisse : Der Prozess der Neuanordnung natürlicher Ergebnisse verwendet den Werbekandidatensatz nicht als kontextbezogene Merkmale zur Entscheidungsfindung. Ebenso werden keine zusätzlichen Entscheidungen über die Rangfolge der Werbekandidatensätze getroffen. Die Neuordnung erfolgt lediglich innerhalb der natürlichen Ergebnisse. , um zu erhalten die Sortierreihenfolge des optimalen Benutzernutzens.
▐Es liegt ein Problem vor
-
Die Algorithmusstrategien haben inkonsistente Ziele und können nicht die global optimalen Ergebnisse erzielen : Die Werbeanzeigestrategie basiert mehr auf dem kommerziellen Wert, und der Benutzerwert natürlicher Ergebnisse wird weniger berücksichtigt, obwohl der Ersatz von Indikatoren durch Anpassen des Kompromisses erreicht werden kann Koeffizient zwischen den beiden. , aber offensichtlich kann kein global optimales Sequenzergebnis erzielt werden. -
Es besteht eine starke Kopplung zwischen der Iteration der Algorithmusstrategie und der Iteration der Geschäftslogik : Im aktuellen Link müssen Algorithmenstudenten gemeinsam mit Ingenieurstudenten denselben Codesatz entwickeln. Gleichzeitig sind die verschiedenen beteiligten Richtlinienmodule auf verschiedene Phasen verteilt B. Der Werbe-ECPM-Wertdienst, auf den sich der Werbedienst für dynamisches Targeting verlässt, wird während der Abschlussphase aufgerufen, während die tatsächlichen Ergebnisse des dynamischen Targetings während der gemischten Planung verarbeitet werden, was zu einer höheren Komplexität des Gesamtsystems und einer höheren Stabilität führt Instandhaltungskosten.
▐Lösung _
-
Anpassung des Shuffle-Strategieziels : Der Shuffle-Dienst muss den Benutzerwert und den kommerziellen Wert umfassend berücksichtigen und den Gesamtwert der Seite als Shuffle-Strategieziel maximieren. Entkopplung von Strategie und Geschäft : Extrahieren Sie die Mischstrategielogik aus der serverseitigen Geschäftsverbindung und verbinden Sie sie als unabhängigen Dienst. Spätere iterative Upgrades werden von Algorithmuskollegen im neuen Dienst verwaltet, und die Strategie des Algorithmus wird iteriert. Es ist unabhängig von die geschäftliche Iteration der Engineering-Verbindung, wodurch die Arbeitsteilung in der Entwicklung klarer wird und die entsprechenden Wartungskosten gesenkt werden.

Konkreter Umsetzungsplan
▐Technische Auswahl
Dieser neue Hybrid-Fusion-Dienst wählt xrec als Code-Framework. xrec ist ein Geschäftsframework, das auf der TPP-Grafik-Engine basiert. Das Framework bietet hauptsächlich die folgenden Vorteile:
Empfohlene Komponentisierung von Geschäftsprozessen : Das xrec-Framework kann die Geschäftsknoten der Verknüpfung in Komponenten abstrahieren. Entwickler müssen lediglich das Geschäft jedes Knotens gemäß den vom Framework vereinbarten Komponentenimplementierungsspezifikationen implementieren und beim Anordnen eine JSON-Datei mit festem Format übergeben Prozesse besteht keine Notwendigkeit, die Orchestrierung von Geschäftsprozessen auf Codeebene zu berücksichtigen.
Vollständig asynchrone Parallelitätsleistungsoptimierung : Anders als der optimierte Ausführungsprozess des TPE-Frameworks, das im ursprünglichen Engineering-Link verwendet wurde, verbessert das xrec-Framework die Szenenleistung durch Automatisierung der Mehrkanal-Parallelität und Kapselung von Datenvorgängen und verwendet eine grafische Struktur zur Beschreibung des Geschäftsprozesses , damit Benutzer dies nicht tun müssen Durch das Erlernen der gleichzeitigen Programmierung können Sie eine umfassende und sichere Parallelität erreichen. Gleichzeitig werden Datenserialisierung/Deserialisierung, Datenkonvertierung und allgemeine externe Dienstaufrufe zur Verwendung in Bedieneroperationen gekapselt Leistungsoptimierte Plattformmodule werden verwendet, um ungenutzten, leistungsoptimierten Benutzercode zu ersetzen.
Das xrec-Framework erspart Algorithmenentwicklern viel Arbeit, stellt aber auch mehr Einschränkungen für die Codierungsregeln dar. Der Entwicklungsprozess muss streng nach den Regeln des Frameworks durchgeführt werden.
▐Link -Schema
Gemischte Service-Link-Lösung
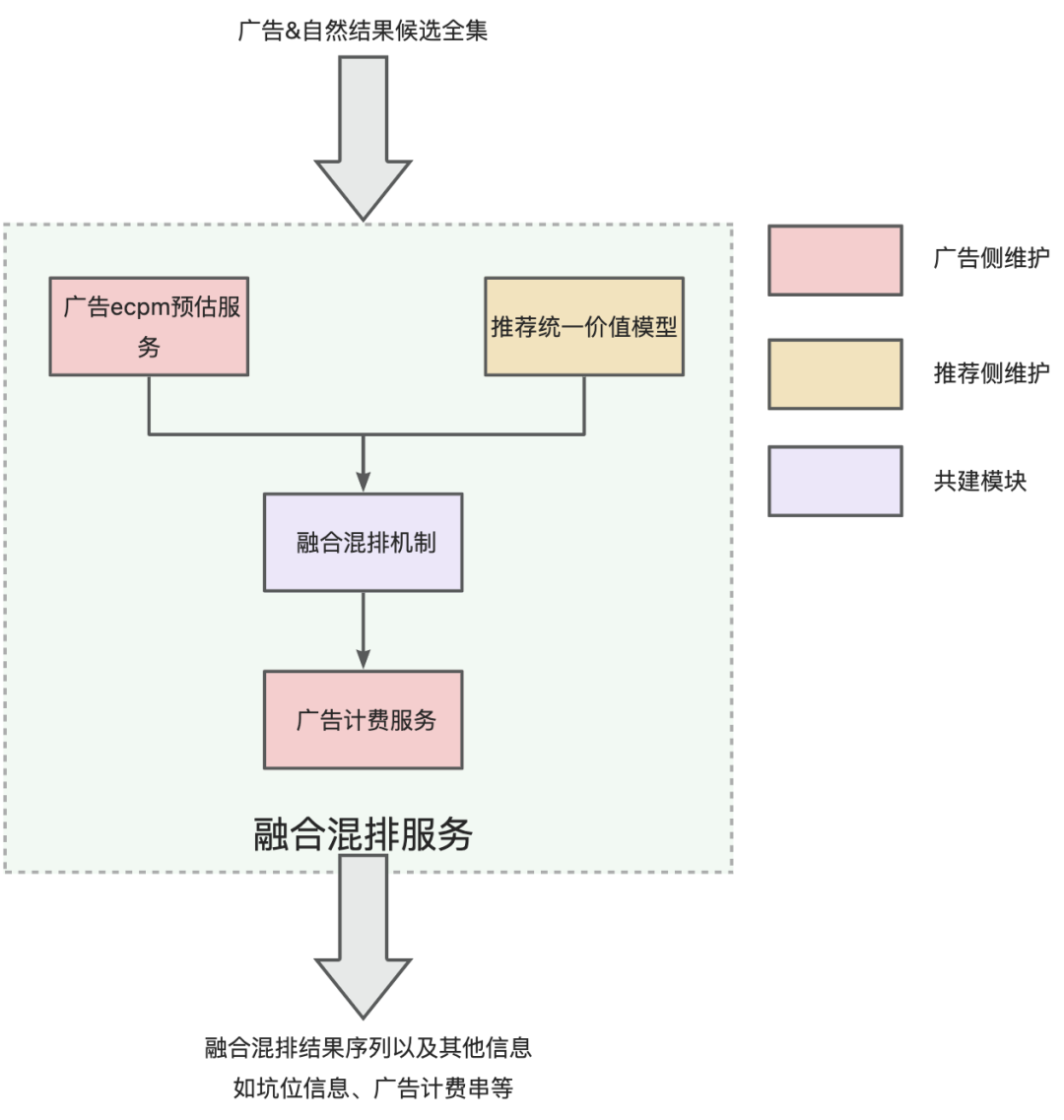
Basierend auf dem xrec-Framework haben wir einen unabhängigen TPP-Dienst (xhuffle) aufgebaut, um die integrierte Mischstrategielogik aller Werbe- und Naturergebnisse zu übernehmen. Der Gesamtlink des Dienstes ist wie folgt. Der xhuffle-Dienst ruft intern den Werbe-ECPM-Wertschätzungsdienst und das empfohlene einheitliche Wertmodell parallel auf, um die Wertinformationen von Werbung und natürlichen Ergebnissen zu erhalten. Das Fusion-Mixing-Mechanismus-Modul fasst die Wertinformationen von Werbung und natürlichen Ergebnissen zusammen und trifft Entscheidungen über die Sortierung Ergebnisse aller Karten. , unter Angabe der Pit-Position der Karte oder Neuordnung der Karten und schließlich Anruf beim Werbeabrechnungsdienst, um Werbeabrechnungsinformationen für die Werbeergebnisse zu erhalten.
-
Im ursprünglichen Engineering-Link sind die gemischten und abhängigen Servicemodule auf verschiedene Phasen der Pipeline verteilt. Nach der Erstellung eines neuen Dienstes wird die relevante Logik zum Mischen und Sortieren in einen unabhängigen Dienst integriert und kann im neuen Dienst separat iteriert werden, wodurch die Entwicklungs- und Wartungskosten erheblich gesenkt werden. -
Das Empfehlungs-Unified-Value-Modell und der Werbe-ECPM-Schätzdienst werden von Empfehlung bzw. Werbung verwaltet und sind jeweils für die Erlangung von Empfehlungswertpunkten und Werbewertpunkten verantwortlich. -
Das integrierte Mischmechanismusmodul wird von der Werbe- und Empfehlungsseite gemeinsam gepflegt und iteriert. -
Der Werbeabrechnungsdienst wird von der Werbeseite verwaltet. Durch den Aufruf des Werbe-EADS-Dienstes wird die Generierung von Werbeabrechnungszeichenfolgen innerhalb des Werbedienstes konvergiert, um die Informationssicherheit zu gewährleisten.
Da es im Informationsfluss nach der Akquisition noch einige Business-Targeting-Strategien gibt, wie z. B. Cloud-Themen, Kurzvideo-Targeting usw., wurde dieser Teil der Strategie in der ursprünglichen gemischten Arrangement-Strategie nicht berücksichtigt. Was die Aktie betrifft Bei der Geschäftsausrichtung kann die Mischstrategie immer noch die Pit-Positionen bestimmen, was dazu führt, dass diese Business-Pit-Karten die Mischergebnisse beeinträchtigen und sich direkt auf die Geschäftsdatenindikatoren auswirken. Im xhuffle-Dienst stellen wir diesen Teil der Business-Pit-Informationen als Service-Eingabe für das Shuffling-Modul bereit und vermeiden diesen Teil des Pits proaktiv, um sicherzustellen, dass sich die Mischergebnisse und die Business-Pit-Ergebnisse nicht gegenseitig beeinträchtigen.
Anrufplan für den Engineering-Link-Service
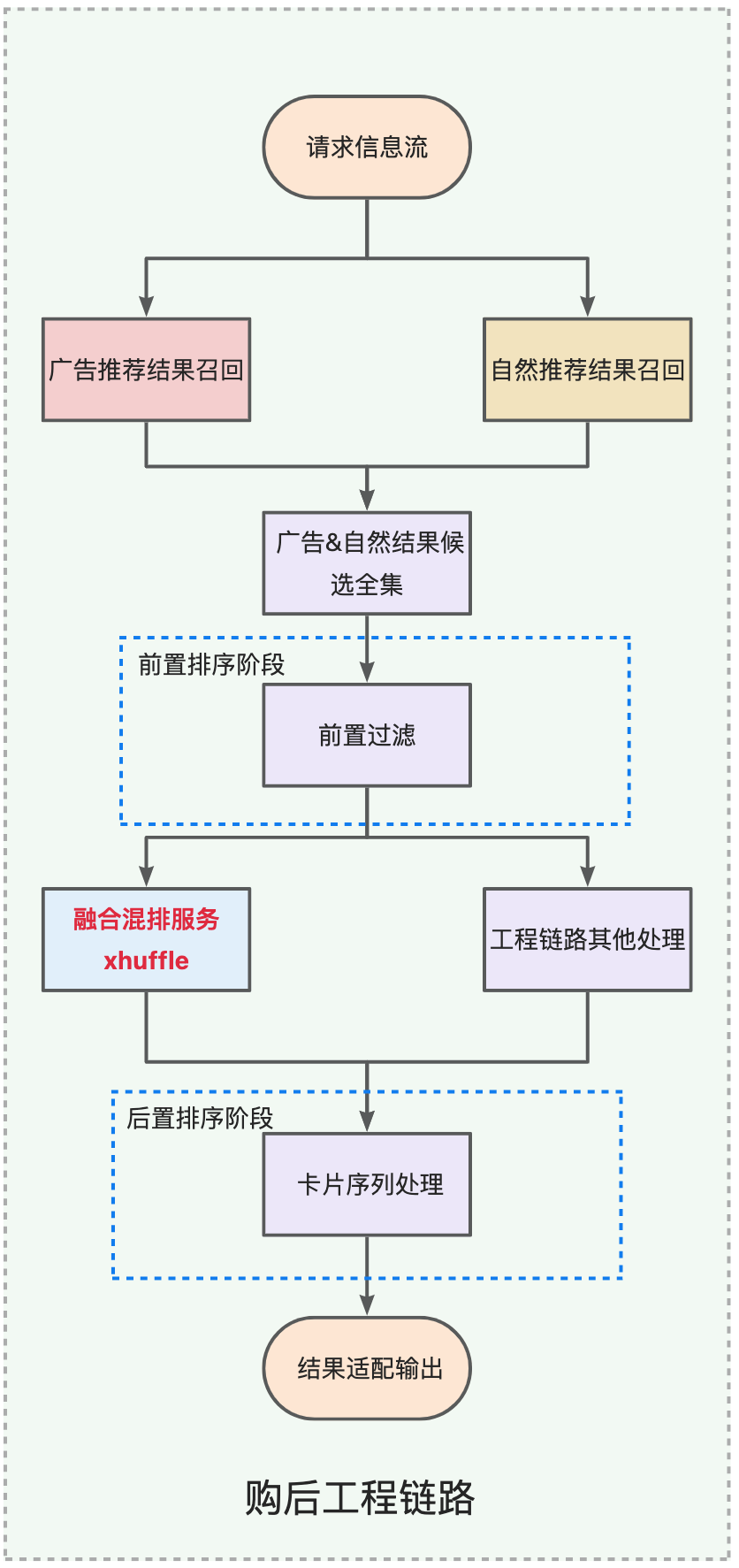
Option 1: Teilen Sie die Sortierphase auf und rufen Sie Dienste parallel auf
-
Vorsortierstufe : Diese Stufe führt hauptsächlich eine Vorsortierkartenfilterung durch. Nachdem Sie die vorgefilterte Kartensequenz erhalten haben, initiieren Sie parallele Aufrufe an den Shuffle-Dienst und andere externe Dienste des Engineering-Links. -
Nachsortierungsphase : In dieser Phase wird die Kartensequenz basierend auf den Mischergebnissen sortiert und gekürzt, um die endgültige Kartensequenz zu bestimmen, die für die Ausgabe angepasst werden muss.
方案二:串行调用服务
这种调用方式对链路的RT压力会更大,由于是串行执行,服务调用的耗时会直接体现到整体链路耗时上。为了缓解RT的压力,我们采取了以下两个方面的措施:
xhuffle服务本身的链路优化。混排服务中耗时占比最大的是推荐统一价值模型的调用,在最初的方案中是通过调用外部tpp服务进行处理,目前已优化为在服务中直接进行RTP调用来处理,同时调用所需的qinfo数据直接使用商品召回的缓存数据,不用重新生成。
购后工程链路在不影响用户体验的前提下,适当放宽超时限制,以此降低端上的超时率。目前,各场景均将场景超时限制放宽50ms。
两种方案对比
优点 |
缺点 |
并行调用对链路整体的RT影响较小 |
将工程链路其他处理前置,会带来下游服务承接的卡片数量增长三至四倍,带来冗余的资源消耗 |
链路改造成本小,无冗余资源消耗 |
服务耗时会直接体现在链路整体耗时上,对系统稳定性的压力更大 |
经过综合考虑后,我们认为方案一带来的冗余资源消耗是不可接受的,最终选择了方案二作为正式的链路改造方案。

▐ 链路稳定性结果
-
混排服务场景指标:入口场景的服务调用平均RT保持在30ms以内,P99保持在70ms以内。服务调用超时率稳定在0.5%以内。 -
入口场景整体的系统稳定性指标:链路整体耗时可控,整体超时率保持在0.3%以内。 -
端上用户体验指标:由于各场景均扩了超时RT限制,我们通过端上接口的耗时变化来反映对用户体感上的影响。从扩RT前后分端接口耗时来看,用户体感上没有明显的变化。
▐ 未来展望
-
短视频、直播等业务的混排策略升级,减少业务定坑对混排的约束。 -
类目打散等规则化策略的融入。 -
建设通用化的混排服务链路接入方案,以同一套方案为更多场景提供混排策略服务。

这里有巨大的流量,可以满足你对高并发大规模分布式系统练手的畅想;
这里有前沿的算法应用场景,可以玩转各种智能创新;
这里有严苛的系统指标要求,可以让你感受到优化复杂系统化的快感~
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。